 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of the Input in Natural Language Video Description
Feb 09, 2021
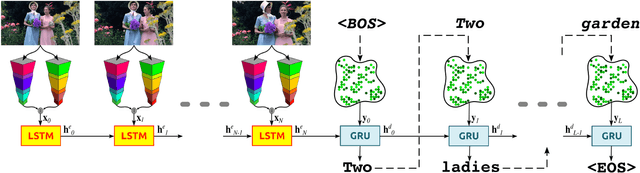


Natural Language Video Description (NLVD) has recently received strong interest in the Computer Vision, Natural Language Processing (NLP), Multimedia, and Autonomous Robotics communities. The State-of-the-Art (SotA) approaches obtained remarkable results when tested on the benchmark datasets. However, those approaches poorly generalize to new datasets. In addition, none of the existing works focus on the processing of the input to the NLVD systems, which is both visual and textual. In this work, it is presented an extensive study dealing with the role of the visual input, evaluated with respect to the overall NLP performance. This is achieved performing data augmentation of the visual component, applying common transformations to model camera distortions, noise, lighting, and camera positioning, that are typical in real-world operative scenarios. A t-SNE based analysis is proposed to evaluate the effects of the considered transformations on the overall visual data distribution. For this study, it is considered the English subset of Microsoft Research Video Description (MSVD) dataset, which is used commonly for NLVD. It was observed that this dataset contains a relevant amount of syntactic and semantic errors. These errors have been amended manually, and the new version of the dataset (called MSVD-v2) is used in the experimentation. The MSVD-v2 dataset is released to help to gain insight into the NLVD problem.
* In IEEE Transactions on Multimedia
Enhancing Continuous Control of Mobile Robots for End-to-End Visual Active Tracking
Sep 28, 2020

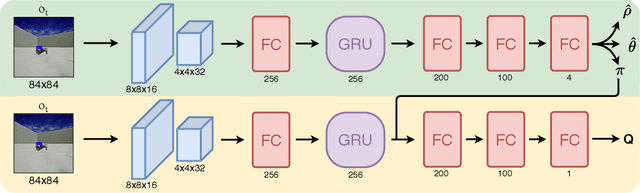

In the last decades, visual target tracking has been one of the primary research interests of the Robotics research community. The recent advances in Deep Learning technologies have made the exploitation of visual tracking approaches effective and possible in a wide variety of applications, ranging from automotive to surveillance and human assistance. However, the majority of the existing works focus exclusively on passive visual tracking, i.e., tracking elements in sequences of images by assuming that no actions can be taken to adapt the camera position to the motion of the tracked entity. On the contrary, in this work, we address visual active tracking, in which the tracker has to actively search for and track a specified target. Current State-of-the-Art approaches use Deep Reinforcement Learning (DRL) techniques to address the problem in an end-to-end manner. However, two main problems arise: i) most of the contributions focus only on discrete action spaces and the ones that consider continuous control do not achieve the same level of performance; and ii) if not properly tuned, DRL models can be challenging to train, resulting in a considerably slow learning progress and poor final performance. To address these challenges, we propose a novel DRL-based visual active tracking system that provides continuous action policies. To accelerate training and improve the overall performance, we introduce additional objective functions and a Heuristic Trajectory Generator (HTG) to facilitate learning. Through an extensive experimentation, we show that our method can reach and surpass other State-of-the-Art approaches performances, and demonstrate that, even if trained exclusively in simulation, it can successfully perform visual active tracking even in real scenarios.