 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Illumination for Visual Ego-Motion Estimation in the Dark
Feb 19, 2025



Visual Odometry (VO) and Visual SLAM (V-SLAM) systems often struggle in low-light and dark environments due to the lack of robust visual features. In this paper, we propose a novel active illumination framework to enhance the performance of VO and V-SLAM algorithms in these challenging conditions. The developed approach dynamically controls a moving light source to illuminate highly textured areas, thereby improving feature extraction and tracking. Specifically, a detector block, which incorporates a deep learning-based enhancing network, identifies regions with relevant features. Then, a pan-tilt controller is responsible for guiding the light beam toward these areas, so that to provide information-rich images to the ego-motion estimation algorithm. Experimental results on a real robotic platform demonstrate the effectiveness of the proposed method, showing a reduction in the pose estimation error up to 75% with respect to a traditional fixed lighting technique.
The Power of Input: Benchmarking Zero-Shot Sim-To-Real Transfer of Reinforcement Learning Control Policies for Quadrotor Control
Oct 10, 2024



In the last decade, data-driven approaches have become popular choices for quadrotor control, thanks to their ability to facilitate the adaptation to unknown or uncertain flight conditions. Among the different data-driven paradigms, Deep Reinforcement Learning (DRL) is currently one of the most explored. However, the design of DRL agents for Micro Aerial Vehicles (MAVs) remains an open challenge. While some works have studied the output configuration of these agents (i.e., what kind of control to compute), there is no general consensus on the type of input data these approaches should employ. Multiple works simply provide the DRL agent with full state information, without questioning if this might be redundant and unnecessarily complicate the learning process, or pose superfluous constraints on the availability of such information in real platforms. In this work, we provide an in-depth benchmark analysis of different configurations of the observation space. We optimize multiple DRL agents in simulated environments with different input choices and study their robustness and their sim-to-real transfer capabilities with zero-shot adaptation. We believe that the outcomes and discussions presented in this work supported by extensive experimental results could be an important milestone in guiding future research on the development of DRL agents for aerial robot tasks.
Exploring Deep Reinforcement Learning for Robust Target Tracking using Micro Aerial Vehicles
Dec 29, 2023The capability to autonomously track a non-cooperative target is a key technological requirement for micro aerial vehicles. In this paper, we propose an output feedback control scheme based on deep reinforcement learning for controlling a micro aerial vehicle to persistently track a flying target while maintaining visual contact. The proposed method leverages relative position data for control, relaxing the assumption of having access to full state information which is typical of related approaches in literature. Moreover, we exploit classical robustness indicators in the learning process through domain randomization to increase the robustness of the learned policy. Experimental results validate the proposed approach for target tracking, demonstrating high performance and robustness with respect to mass mismatches and control delays. The resulting nonlinear controller significantly outperforms a standard model-based design in numerous off-nominal scenarios.
D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
Aug 31, 2023



Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this paper we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training.
Enhancing Continuous Control of Mobile Robots for End-to-End Visual Active Tracking
Sep 28, 2020

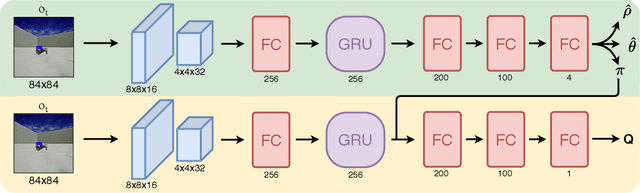

In the last decades, visual target tracking has been one of the primary research interests of the Robotics research community. The recent advances in Deep Learning technologies have made the exploitation of visual tracking approaches effective and possible in a wide variety of applications, ranging from automotive to surveillance and human assistance. However, the majority of the existing works focus exclusively on passive visual tracking, i.e., tracking elements in sequences of images by assuming that no actions can be taken to adapt the camera position to the motion of the tracked entity. On the contrary, in this work, we address visual active tracking, in which the tracker has to actively search for and track a specified target. Current State-of-the-Art approaches use Deep Reinforcement Learning (DRL) techniques to address the problem in an end-to-end manner. However, two main problems arise: i) most of the contributions focus only on discrete action spaces and the ones that consider continuous control do not achieve the same level of performance; and ii) if not properly tuned, DRL models can be challenging to train, resulting in a considerably slow learning progress and poor final performance. To address these challenges, we propose a novel DRL-based visual active tracking system that provides continuous action policies. To accelerate training and improve the overall performance, we introduce additional objective functions and a Heuristic Trajectory Generator (HTG) to facilitate learning. Through an extensive experimentation, we show that our method can reach and surpass other State-of-the-Art approaches performances, and demonstrate that, even if trained exclusively in simulation, it can successfully perform visual active tracking even in real scenarios.