 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
Aug 31, 2023



Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this paper we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training.
Interaction-GCN: a Graph Convolutional Network based framework for social interaction recognition in egocentric videos
Apr 28, 2021
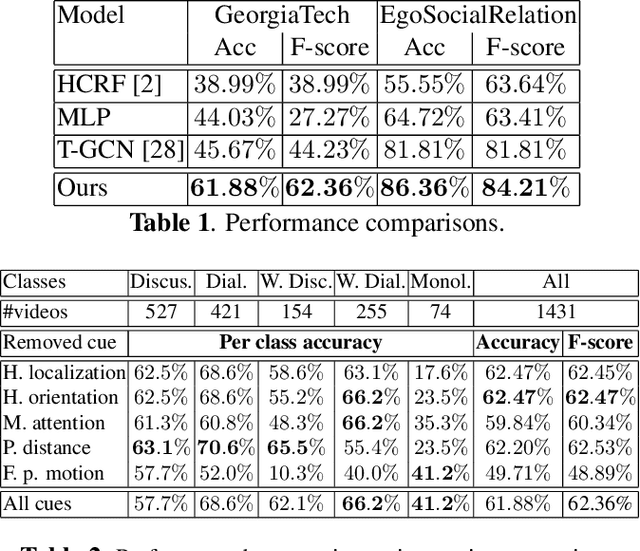
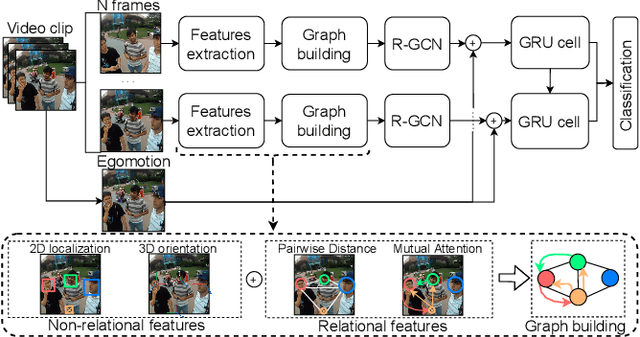
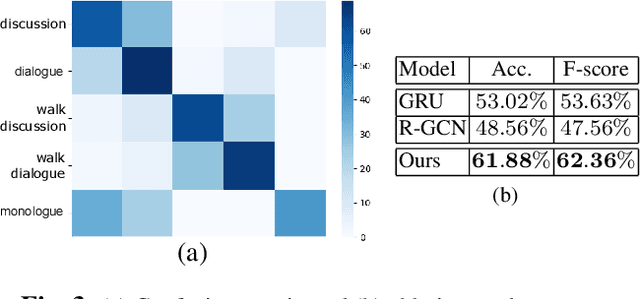
In this paper we propose a new framework to categorize social interactions in egocentric videos, we named InteractionGCN. Our method extracts patterns of relational and non-relational cues at the frame level and uses them to build a relational graph from which the interactional context at the frame level is estimated via a Graph Convolutional Network based approach. Then it propagates this context over time, together with first-person motion information, through a Gated Recurrent Unit architecture. Ablation studies and experimental evaluation on two publicly available datasets validate the proposed approach and establish state of the art results.