 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Data Generation for Precision Agriculture: Blending Simulated Environments with Real Imagery
Feb 25, 2025In precision agriculture, the scarcity of labeled data and significant covariate shifts pose unique challenges for training machine learning models. This scarcity is particularly problematic due to the dynamic nature of the environment and the evolving appearance of agricultural subjects as living things. We propose a novel system for generating realistic synthetic data to address these challenges. Utilizing a vineyard simulator based on the Unity engine, our system employs a cut-and-paste technique with geometrical consistency considerations to produce accurate photo-realistic images and labels from synthetic environments to train detection algorithms. This approach generates diverse data samples across various viewpoints and lighting conditions. We demonstrate considerable performance improvements in training a state-of-the-art detector by applying our method to table grapes cultivation. The combination of techniques can be easily automated, an increasingly important consideration for adoption in agricultural practice.
Can Robots "Taste" Grapes? Estimating SSC with Simple RGB Sensors
Dec 29, 2024



In table grape cultivation, harvesting depends on accurately assessing fruit quality. While some characteristics, like color, are visible, others, such as Soluble Solid Content (SSC), or sugar content measured in degrees Brix ({\deg}Brix), require specific tools. SSC is a key quality factor that correlates with ripeness, but lacks a direct causal relationship with color. Hyperspectral cameras can estimate SSC with high accuracy under controlled laboratory conditions, but their practicality in field environments is limited. This study investigates the potential of simple RGB sensors under uncontrolled lighting to estimate SSC and color, enabling cost-effective, robot-assisted harvesting. Over the 2021 and 2022 summer seasons, we collected grape images with corresponding SSC and color labels to evaluate algorithmic solutions for SSC estimation on embedded devices commonly used in robotics and smartphones. Our results demonstrate that SSC can be estimated from visual appearance with human-like performance. We propose computationally efficient histogram-based methods for resource-constrained robots and deep learning approaches for more complex applications.
Evaluating the Efficacy of Cut-and-Paste Data Augmentation in Semantic Segmentation for Satellite Imagery
Apr 08, 2024



Satellite imagery is crucial for tasks like environmental monitoring and urban planning. Typically, it relies on semantic segmentation or Land Use Land Cover (LULC) classification to categorize each pixel. Despite the advancements brought about by Deep Neural Networks (DNNs), their performance in segmentation tasks is hindered by challenges such as limited availability of labeled data, class imbalance and the inherent variability and complexity of satellite images. In order to mitigate those issues, our study explores the effectiveness of a Cut-and-Paste augmentation technique for semantic segmentation in satellite images. We adapt this augmentation, which usually requires labeled instances, to the case of semantic segmentation. By leveraging the connected components in the semantic segmentation labels, we extract instances that are then randomly pasted during training. Using the DynamicEarthNet dataset and a U-Net model for evaluation, we found that this augmentation significantly enhances the mIoU score on the test set from 37.9 to 44.1. This finding highlights the potential of the Cut-and-Paste augmentation to improve the generalization capabilities of semantic segmentation models in satellite imagery.
AgriSORT: A Simple Online Real-time Tracking-by-Detection framework for robotics in precision agriculture
Sep 28, 2023
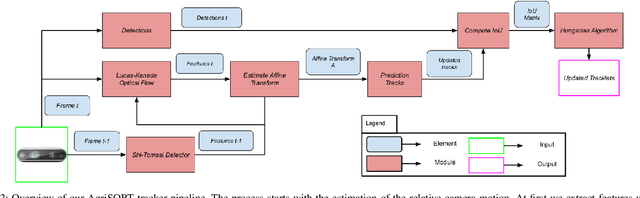


The problem of multi-object tracking (MOT) consists in detecting and tracking all the objects in a video sequence while keeping a unique identifier for each object. It is a challenging and fundamental problem for robotics. In precision agriculture the challenge of achieving a satisfactory solution is amplified by extreme camera motion, sudden illumination changes, and strong occlusions. Most modern trackers rely on the appearance of objects rather than motion for association, which can be ineffective when most targets are static objects with the same appearance, as in the agricultural case. To this end, on the trail of SORT [5], we propose AgriSORT, a simple, online, real-time tracking-by-detection pipeline for precision agriculture based only on motion information that allows for accurate and fast propagation of tracks between frames. The main focuses of AgriSORT are efficiency, flexibility, minimal dependencies, and ease of deployment on robotic platforms. We test the proposed pipeline on a novel MOT benchmark specifically tailored for the agricultural context, based on video sequences taken in a table grape vineyard, particularly challenging due to strong self-similarity and density of the instances. Both the code and the dataset are available for future comparisons.
Weakly and Semi-Supervised Detection, Segmentation and Tracking of Table Grapes with Limited and Noisy Data
Aug 27, 2022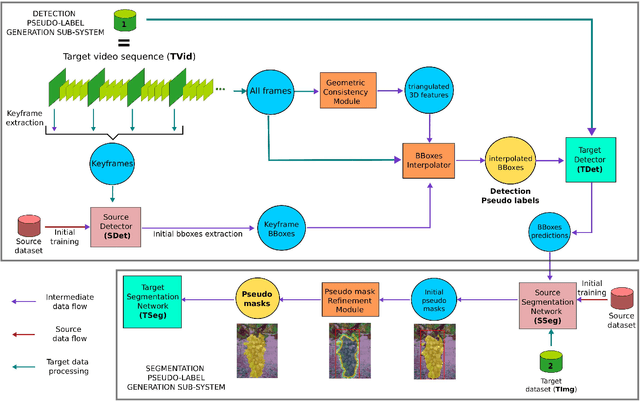

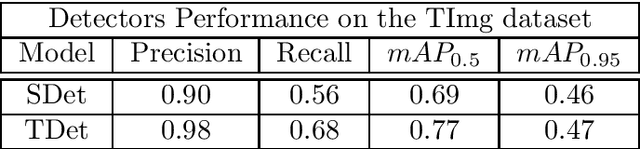
Detection, segmentation and tracking of fruits and vegetables are three fundamental tasks for precision agriculture, enabling robotic harvesting and yield estimation applications. However, modern algorithms are data hungry and it is not always possible to gather enough data to apply the best performing supervised approaches. Since data collection is an expensive and cumbersome task, the enabling technologies for using computer vision in agriculture are often out of reach for small businesses. Following previous work in this context, where we proposed an initial weakly supervised solution to reduce the data needed to get state-of-the-art detection and segmentation in precision agriculture applications, here we improve that system and explore the problem of tracking fruits in orchards. We present the case of vineyards of table grapes in southern Lazio (Italy) since grapes are a difficult fruit to segment due to occlusion, color and general illumination conditions. We consider the case when there is some initial labelled data that could work as source data (e.g. wine grape data), but it is considerably different from the target data (e.g. table grape data). To improve detection and segmentation on the target data, we propose to train the segmentation algorithm with a weak bounding box label, while for tracking we leverage 3D Structure from Motion algorithms to generate new labels from already labelled samples. Finally, the two systems are combined in a full semi-supervised approach. Comparisons with SotA supervised solutions show how our methods are able to train new models that achieve high performances with few labelled images and with very simple labelling.