 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJ-MOD$^{2}$: Joint Monocular Obstacle Detection and Depth Estimation
Dec 13, 2017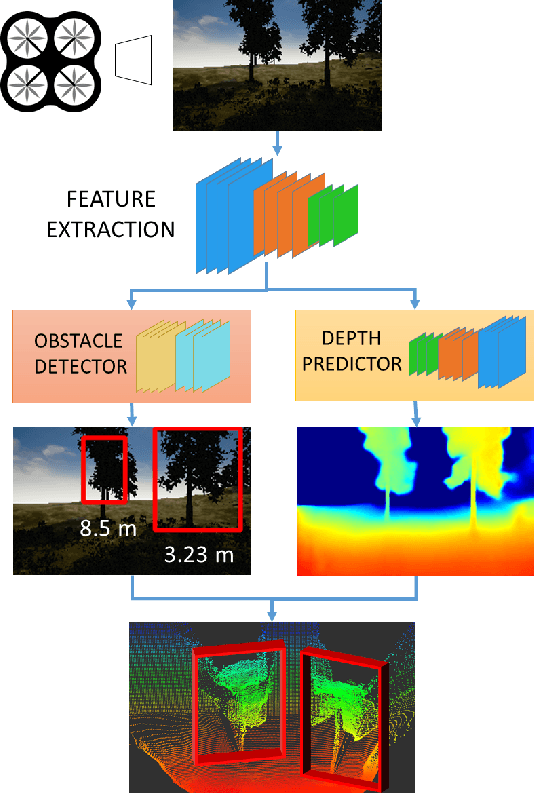
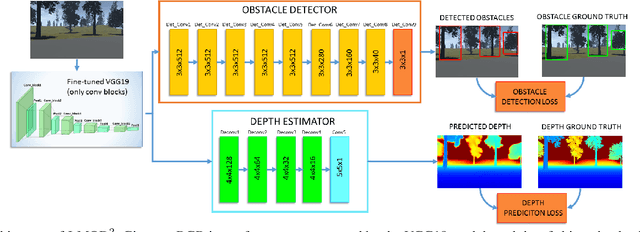
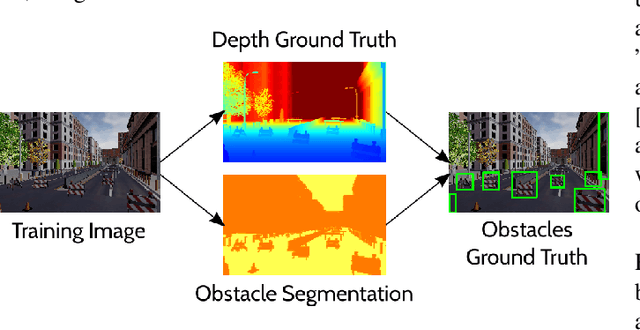
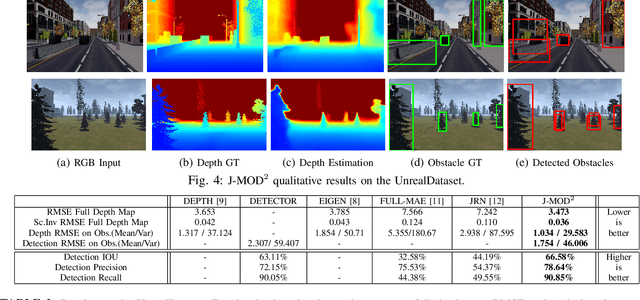
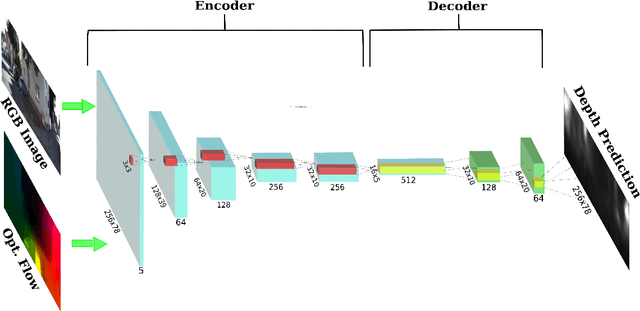
In this work, we propose an end-to-end deep architecture that jointly learns to detect obstacles and estimate their depth for MAV flight applications. Most of the existing approaches either rely on Visual SLAM systems or on depth estimation models to build 3D maps and detect obstacles. However, for the task of avoiding obstacles this level of complexity is not required. Recent works have proposed multi task architectures to both perform scene understanding and depth estimation. We follow their track and propose a specific architecture to jointly estimate depth and obstacles, without the need to compute a global map, but maintaining compatibility with a global SLAM system if needed. The network architecture is devised to exploit the joint information of the obstacle detection task, that produces more reliable bounding boxes, with the depth estimation one, increasing the robustness of both to scenario changes. We call this architecture J-MOD$^{2}$. We test the effectiveness of our approach with experiments on sequences with different appearance and focal lengths and compare it to SotA multi task methods that jointly perform semantic segmentation and depth estimation. In addition, we show the integration in a full system using a set of simulated navigation experiments where a MAV explores an unknown scenario and plans safe trajectories by using our detection model.
Fast Robust Monocular Depth Estimation for Obstacle Detection with Fully Convolutional Networks
Jul 21, 2016


Obstacle Detection is a central problem for any robotic system, and critical for autonomous systems that travel at high speeds in unpredictable environment. This is often achieved through scene depth estimation, by various means. When fast motion is considered, the detection range must be longer enough to allow for safe avoidance and path planning. Current solutions often make assumption on the motion of the vehicle that limit their applicability, or work at very limited ranges due to intrinsic constraints. We propose a novel appearance-based Object Detection system that is able to detect obstacles at very long range and at a very high speed (~300Hz), without making assumptions on the type of motion. We achieve these results using a Deep Neural Network approach trained on real and synthetic images and trading some depth accuracy for fast, robust and consistent operation. We show how photo-realistic synthetic images are able to solve the problem of training set dimension and variety typical of machine learning approaches, and how our system is robust to massive blurring of test images.