 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLS-VO: Learning Dense Optical Subspace for Robust Visual Odometry Estimation
Paper and Code
Dec 12, 2017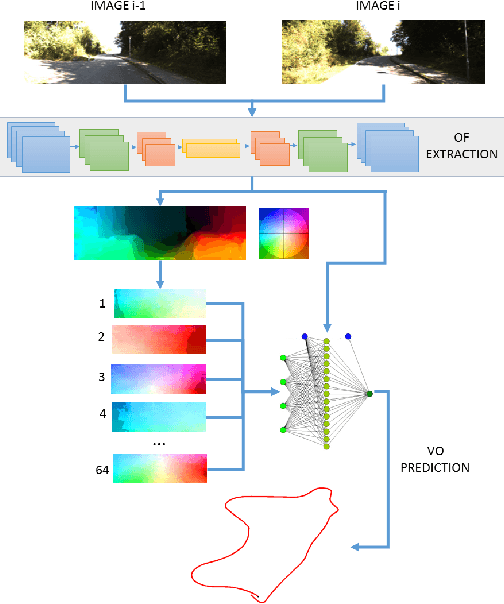
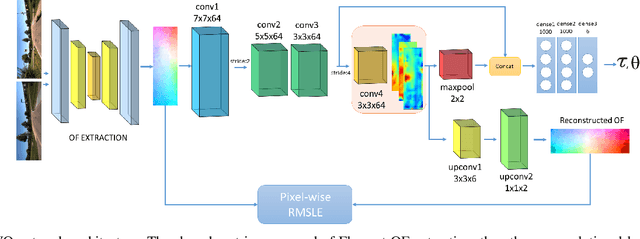


This work proposes a novel deep network architecture to solve the camera Ego-Motion estimation problem. A motion estimation network generally learns features similar to Optical Flow (OF) fields starting from sequences of images. This OF can be described by a lower dimensional latent space. Previous research has shown how to find linear approximations of this space. We propose to use an Auto-Encoder network to find a non-linear representation of the OF manifold. In addition, we propose to learn the latent space jointly with the estimation task, so that the learned OF features become a more robust description of the OF input. We call this novel architecture LS-VO. The experiments show that LS-VO achieves a considerable increase in performances in respect to baselines, while the number of parameters of the estimation network only slightly increases.