 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM18K: A Comprehensive RGB-D Dataset and Benchmark for Mushroom Detection and Instance Segmentation
Jul 15, 2024
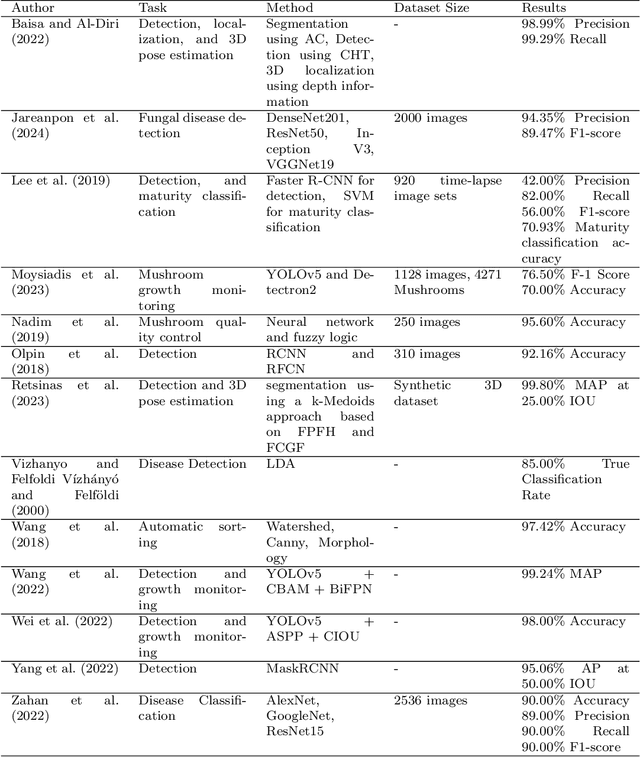
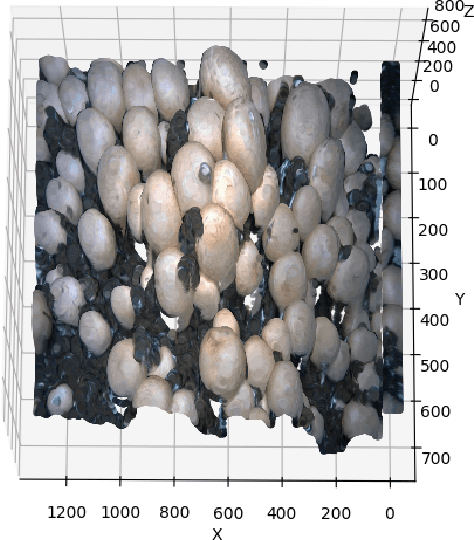
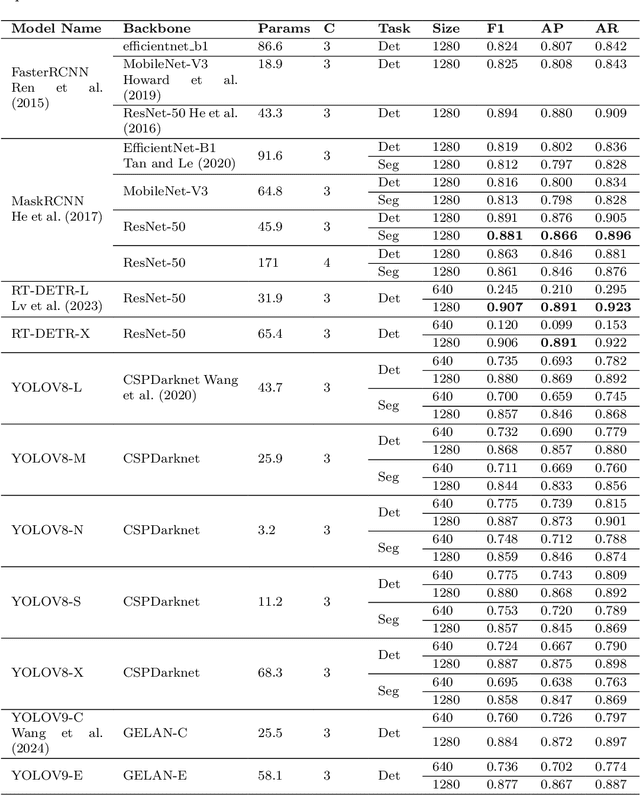
Automating agricultural processes holds significant promise for enhancing efficiency and sustainability in various farming practices. This paper contributes to the automation of agricultural processes by providing a dedicated mushroom detection dataset related to automated harvesting, growth monitoring, and quality control of the button mushroom produced using Agaricus Bisporus fungus. With over 18,000 mushroom instances in 423 RGB-D image pairs taken with an Intel RealSense D405 camera, it fills the gap in mushroom-specific datasets and serves as a benchmark for detection and instance segmentation algorithms in smart mushroom agriculture. The dataset, featuring realistic growth environment scenarios with comprehensive annotations, is assessed using advanced detection and instance segmentation algorithms. The paper details the dataset's characteristics, evaluates algorithmic performance, and for broader applicability, we have made all resources publicly available including images, codes, and trained models via our GitHub repository https://github.com/abdollahzakeri/m18k
WhisperNetV2: SlowFast Siamese Network For Lip-Based Biometrics
Jul 11, 2024



Lip-based biometric authentication (LBBA) has attracted many researchers during the last decade. The lip is specifically interesting for biometric researchers because it is a twin biometric with the potential to function both as a physiological and a behavioral trait. Although much valuable research was conducted on LBBA, none of them considered the different emotions of the client during the video acquisition step of LBBA, which can potentially affect the client's facial expressions and speech tempo. We proposed a novel network structure called WhisperNetV2, which extends our previously proposed network called WhisperNet. Our proposed network leverages a deep Siamese structure with triplet loss having three identical SlowFast networks as embedding networks. The SlowFast network is an excellent candidate for our task since the fast pathway extracts motion-related features (behavioral lip movements) with a high frame rate and low channel capacity. The slow pathway extracts visual features (physiological lip appearance) with a low frame rate and high channel capacity. Using an open-set protocol, we trained our network using the CREMA-D dataset and acquired an Equal Error Rate (EER) of 0.005 on the test set. Considering that the acquired EER is less than most similar LBBA methods, our method can be considered as a state-of-the-art LBBA method.
Classification of jujube fruit based on several pricing factors using machine learning methods
Oct 29, 2021



Jujube is a fruit mainly cultivated in India, China and Iran and has many health benefits. It is sold both fresh and dried. There are several factors in jujube pricing such as weight, wrinkles and defections. Some jujube farmers sell their product all at once, without any proper sorting or classification, for an average price. Our studies and experiences show that their profit can increase significantly if their product is sold after the sorting process. There are some traditional sorting methods for dried jujube fruit but they are costly, time consuming and can be inaccurate due to human error. Nowadays, computer vision combined with machine learning methods, is used increasingly in food industry for sorting and classification purposes and solve many of the traditional sorting methods' problems. In this paper we are proposing a computer vision-based method for grading jujube fruits using machine learning techniques which will take most of the important pricing factors into account and can be used to increase the profit of farmers. In this method we first acquire several images from different samples and then extract their visual features such as color features, shape and size features, texture features, defection and wrinkle features and then we select the most useful features using feature selection algorithms like PCA and CFS. A feature vector is obtained for each sample and we use these vectors to train our classifiers to be able to specify the corresponding pre-defined group for each of the samples. We used different classifiers and training methods in order to obtain the best result and by using decision tree we could reach 98.8% accuracy of the classification.