 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Dark Side of Calibration for Modern Neural Networks
Jun 17, 2021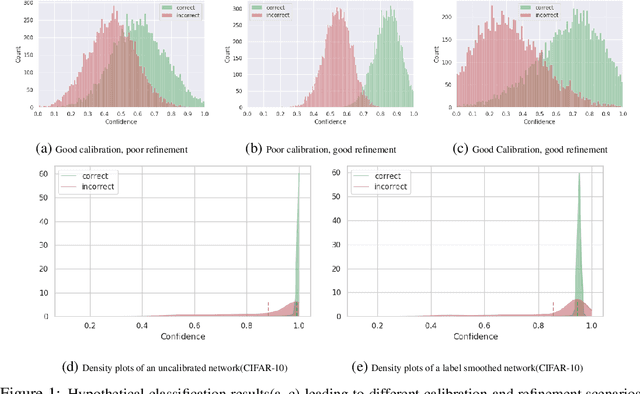

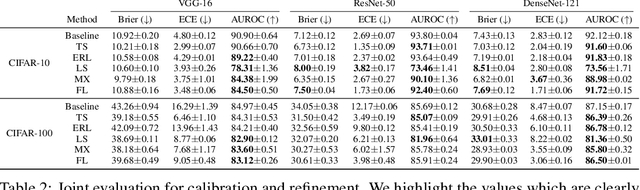
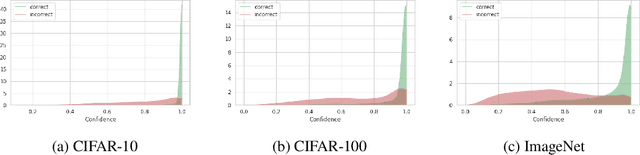
Modern neural networks are highly uncalibrated. It poses a significant challenge for safety-critical systems to utilise deep neural networks (DNNs), reliably. Many recently proposed approaches have demonstrated substantial progress in improving DNN calibration. However, they hardly touch upon refinement, which historically has been an essential aspect of calibration. Refinement indicates separability of a network's correct and incorrect predictions. This paper presents a theoretically and empirically supported exposition for reviewing a model's calibration and refinement. Firstly, we show the breakdown of expected calibration error (ECE), into predicted confidence and refinement. Connecting with this result, we highlight that regularisation based calibration only focuses on naively reducing a model's confidence. This logically has a severe downside to a model's refinement. We support our claims through rigorous empirical evaluations of many state of the art calibration approaches on standard datasets. We find that many calibration approaches with the likes of label smoothing, mixup etc. lower the utility of a DNN by degrading its refinement. Even under natural data shift, this calibration-refinement trade-off holds for the majority of calibration methods. These findings call for an urgent retrospective into some popular pathways taken for modern DNN calibration.
Assessing The Importance Of Colours For CNNs In Object Recognition
Dec 12, 2020
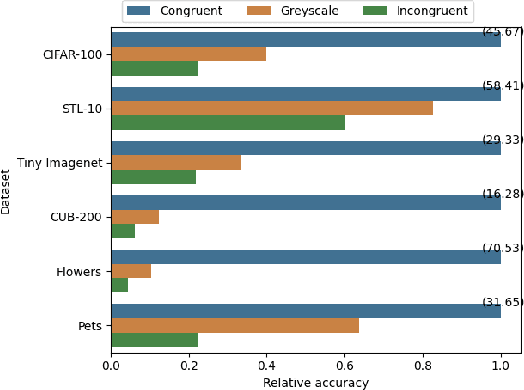

Humans rely heavily on shapes as a primary cue for object recognition. As secondary cues, colours and textures are also beneficial in this regard. Convolutional neural networks (CNNs), an imitation of biological neural networks, have been shown to exhibit conflicting properties. Some studies indicate that CNNs are biased towards textures whereas, another set of studies suggests shape bias for a classification task. However, they do not discuss the role of colours, implying its possible humble role in the task of object recognition. In this paper, we empirically investigate the importance of colours in object recognition for CNNs. We are able to demonstrate that CNNs often rely heavily on colour information while making a prediction. Our results show that the degree of dependency on colours tend to vary from one dataset to another. Moreover, networks tend to rely more on colours if trained from scratch. Pre-training can allow the model to be less colour dependent. To facilitate these findings, we follow the framework often deployed in understanding role of colours in object recognition for humans. We evaluate a model trained with congruent images (images in original colours eg. red strawberries) on congruent, greyscale, and incongruent images (images in unnatural colours eg. blue strawberries). We measure and analyse network's predictive performance (top-1 accuracy) under these different stylisations. We utilise standard datasets of supervised image classification and fine-grained image classification in our experiments.
Filtering Point Targets via Online Learning of Motion Models
Feb 20, 2019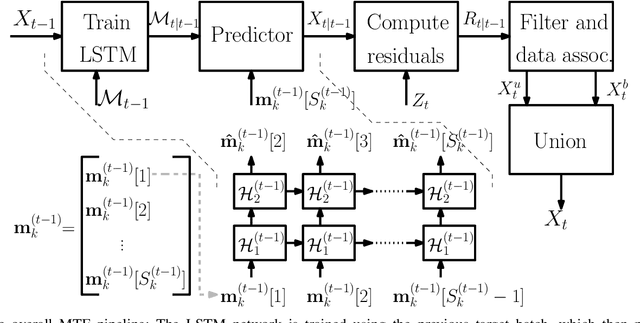
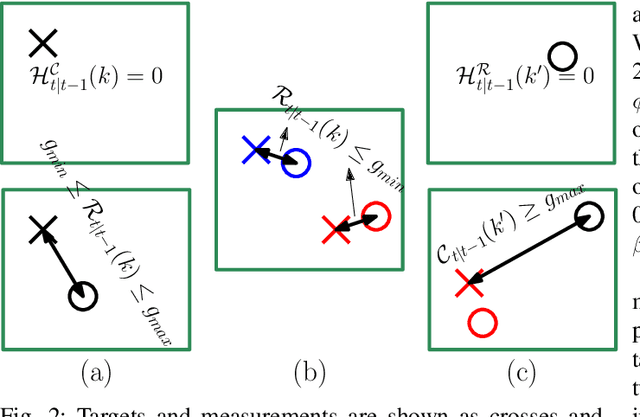
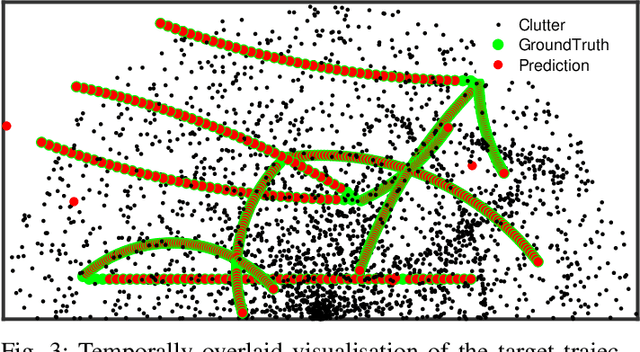
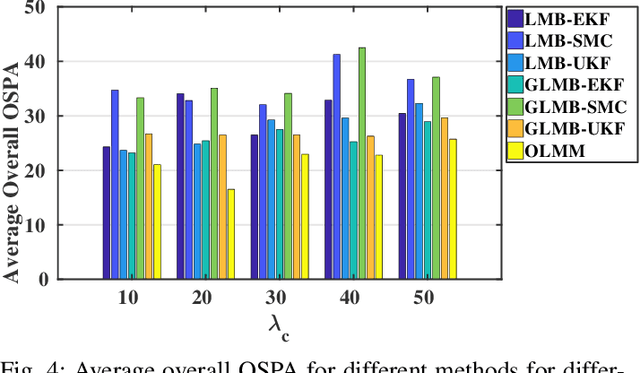
Filtering point targets in highly cluttered and noisy data frames can be very challenging, especially for complex target motions. Fixed motion models can fail to provide accurate predictions, while learning based algorithm can be difficult to design (due to the variable number of targets), slow to train and dependent on separate train/test steps. To address these issues, this paper proposes a multi-target filtering algorithm which learns the motion models, on the fly, using a recurrent neural network with a long short-term memory architecture, as a regression block. The target state predictions are then corrected using a novel data association algorithm, with a low computational complexity. The proposed algorithm is evaluated over synthetic and real point target filtering scenarios, demonstrating a remarkable performance over highly cluttered data sequences.
Real-time tracker with fast recovery from target loss
Feb 12, 2019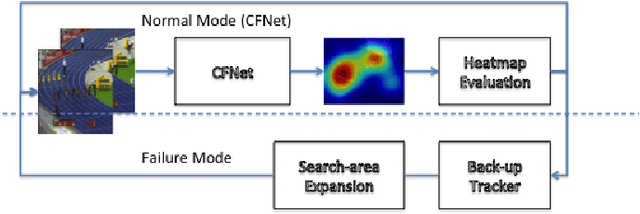
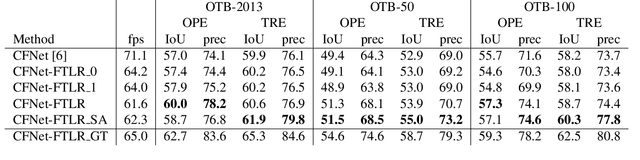
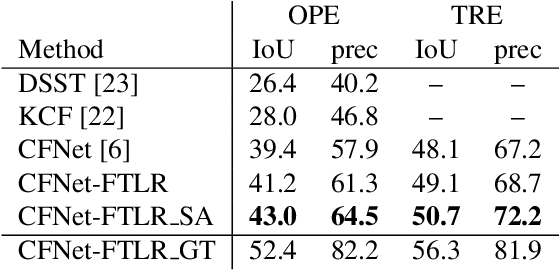
In this paper, we introduce a variation of a state-of-the-art real-time tracker (CFNet), which adds to the original algorithm robustness to target loss without a significant computational overhead. The new method is based on the assumption that the feature map can be used to estimate the tracking confidence more accurately. When the confidence is low, we avoid updating the object's position through the feature map; instead, the tracker passes to a single-frame failure mode, during which the patch's low-level visual content is used to swiftly update the object's position, before recovering from the target loss in the next frame. The experimental evidence provided by evaluating the method on several tracking datasets validates both the theoretical assumption that the feature map is associated to tracking confidence, and that the proposed implementation can achieve target recovery in multiple scenarios, without compromising the real-time performance.
Convolutional Recurrent Predictor: Implicit Representation for Multi-target Filtering and Tracking
Nov 01, 2018
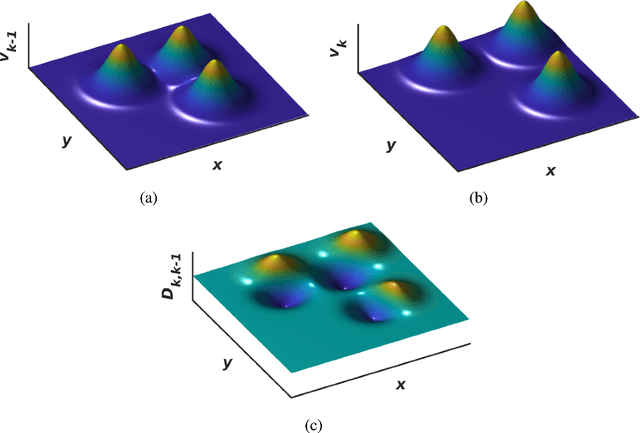

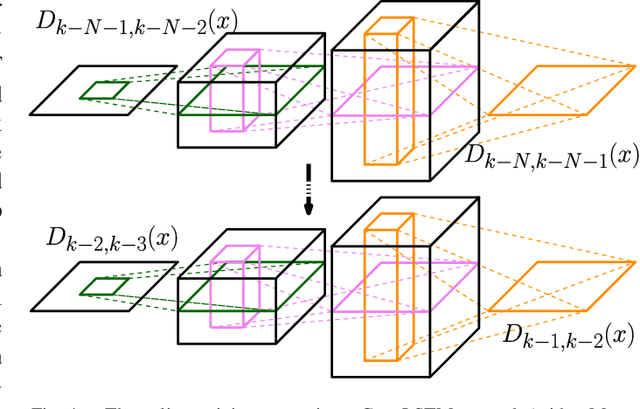
Defining a multi-target motion model, which is an important step of tracking algorithms, can be very challenging. Using fixed models (as in several generative Bayesian algorithms, such as Kalman filters) can fail to accurately predict sophisticated target motions. On the other hand, sequential learning of the motion model (for example, using recurrent neural networks) can be computationally complex and difficult due to the variable unknown number of targets. In this paper, we propose a multi-target filtering and tracking (MTFT) algorithm which learns the motion model, simultaneously for all targets, from an implicitly represented state map and performs spatio-temporal data prediction. To this end, the multi-target state is modelled over a continuous hypothetical target space, using random finite sets and Gaussian mixture probability hypothesis density formulations. The prediction step is recursively performed using a deep convolutional recurrent neural network with a long short-term memory architecture, which is trained as a regression block, on the fly, over "probability density difference" maps. Our approach is evaluated over widely used pedestrian tracking benchmarks, remarkably outperforming state-of-the-art multi-target filtering algorithms, while giving competitive results when compared with other tracking approaches.
Deep Recurrent Neural Network for Multi-target Filtering
Oct 08, 2018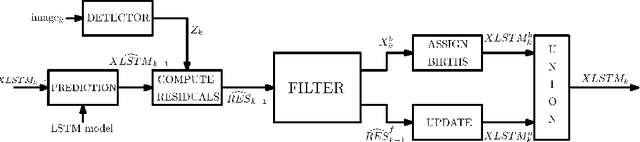
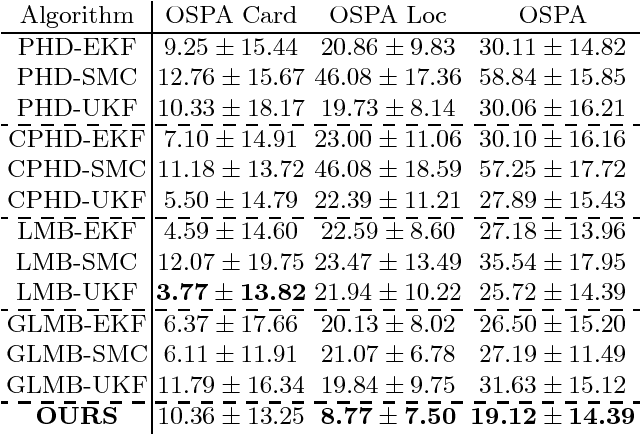
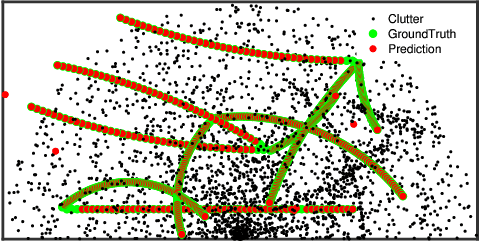
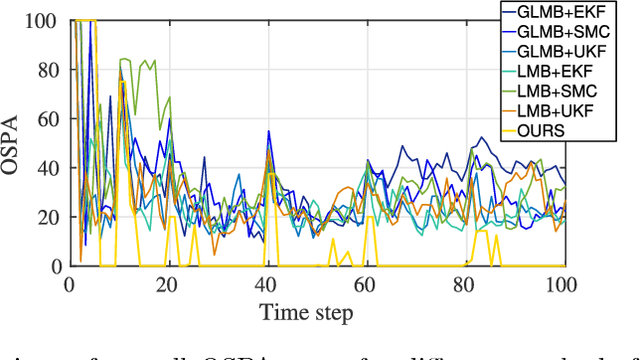
This paper addresses the problem of fixed motion and measurement models for multi-target filtering using an adaptive learning framework. This is performed by defining target tuples with random finite set terminology and utilisation of recurrent neural networks with a long short-term memory architecture. A novel data association algorithm compatible with the predicted tracklet tuples is proposed, enabling the update of occluded targets, in addition to assigning birth, survival and death of targets. The algorithm is evaluated over a commonly used filtering simulation scenario, with highly promising results.
Hide and Seek tracker: Real-time recovery from target loss
Jun 20, 2018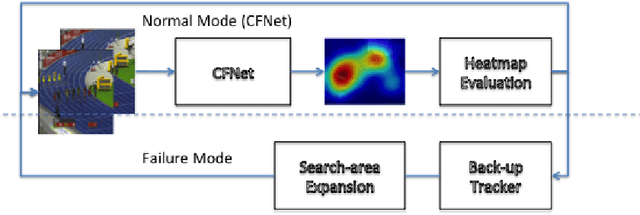

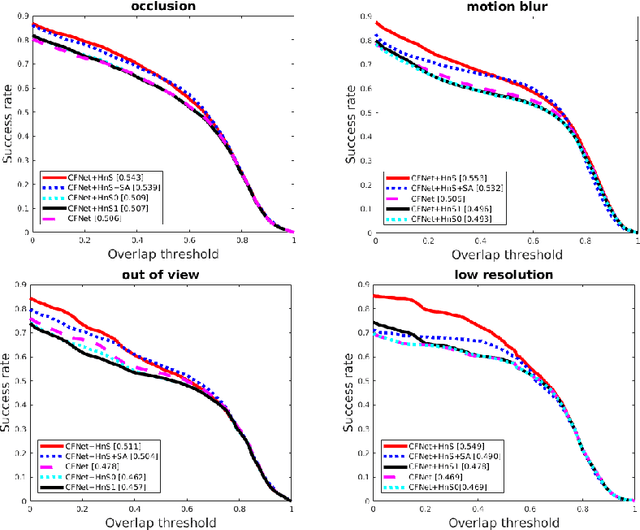
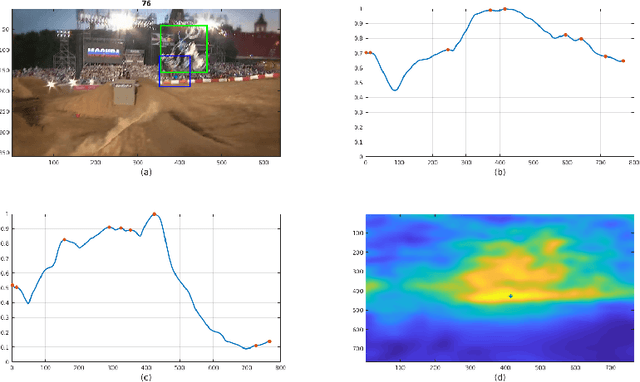
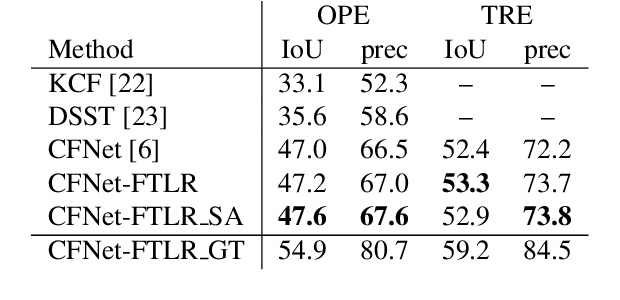
In this paper, we examine the real-time recovery of a video tracker from a target loss, using information that is already available from the original tracker and without a significant computational overhead. More specifically, before using the tracker output to update the target position we estimate the detection confidence. In the case of a low confidence, the position update is rejected and the tracker passes to a single-frame failure mode, during which the patch low-level visual content is used to swiftly update the object position, before recovering from the target loss in the next frame. Orthogonally to this improvement, we further enhance the running average method used for creating the query model in tracking-through-similarity. The experimental evidence provided by evaluation on standard tracking datasets (OTB-50, OTB-100 and OTB-2013) validate that target recovery can be successfully achieved without compromising the real-time update of the target position.
StackSeq2Seq: Dual Encoder Seq2Seq Recurrent Networks
Jan 16, 2018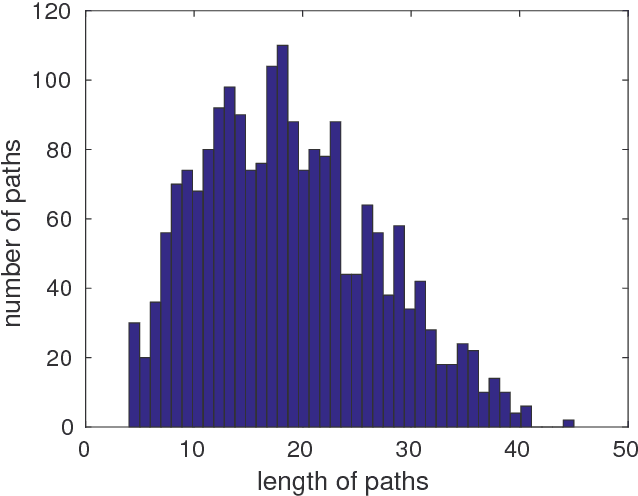

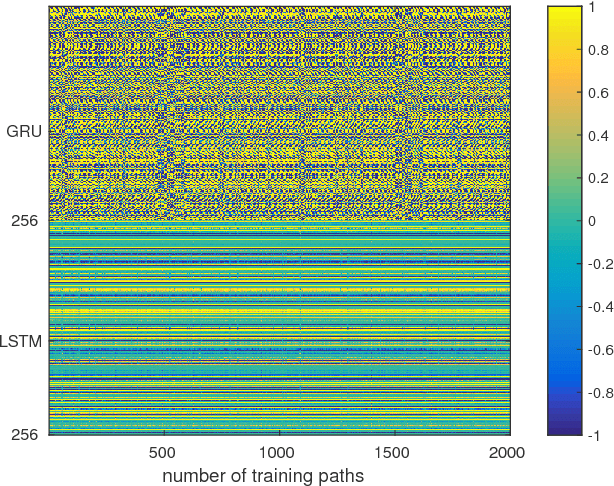
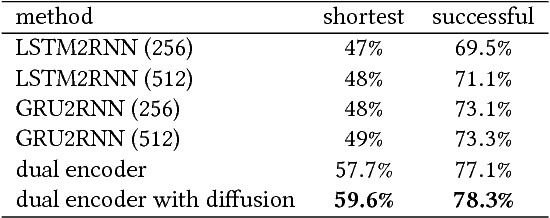
A widely studied non-deterministic polynomial time (NP) hard problem lies in finding a route between the two nodes of a graph. Often meta-heuristics algorithms such as $A^{*}$ are employed on graphs with a large number of nodes. Here, we propose a deep recurrent neural network architecture based on the Sequence-2-Sequence (Seq2Seq) model, widely used, for instance in text translation. Particularly, we illustrate that utilising a context vector that has been learned from two different recurrent networks enables increased accuracies in learning the shortest route of a graph. Additionally, we show that one can boost the performance of the Seq2Seq network by smoothing the loss function using a homotopy continuation of the decoder's loss function.
GeoSeq2Seq: Information Geometric Sequence-to-Sequence Networks
Jan 05, 2018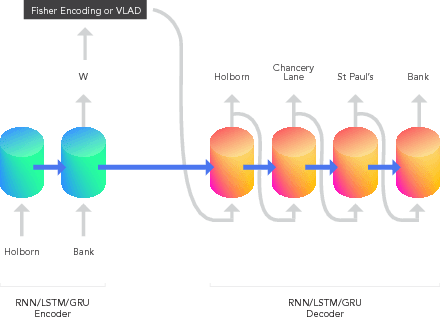
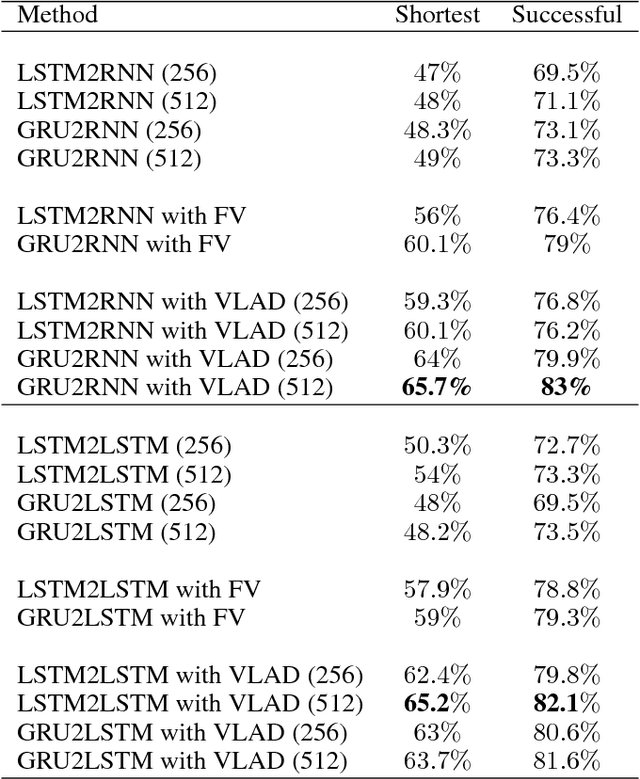
The Fisher information metric is an important foundation of information geometry, wherein it allows us to approximate the local geometry of a probability distribution. Recurrent neural networks such as the Sequence-to-Sequence (Seq2Seq) networks that have lately been used to yield state-of-the-art performance on speech translation or image captioning have so far ignored the geometry of the latent embedding, that they iteratively learn. We propose the information geometric Seq2Seq (GeoSeq2Seq) network which abridges the gap between deep recurrent neural networks and information geometry. Specifically, the latent embedding offered by a recurrent network is encoded as a Fisher kernel of a parametric Gaussian Mixture Model, a formalism common in computer vision. We utilise such a network to predict the shortest routes between two nodes of a graph by learning the adjacency matrix using the GeoSeq2Seq formalism; our results show that for such a problem the probabilistic representation of the latent embedding supersedes the non-probabilistic embedding by 10-15\%.
Approximating meta-heuristics with homotopic recurrent neural networks
Sep 07, 2017
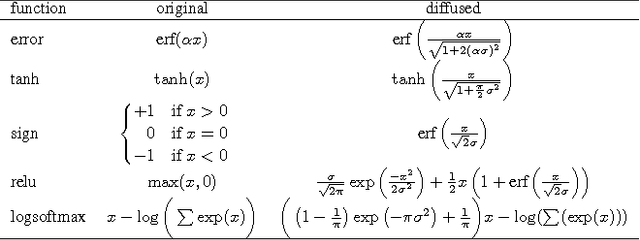
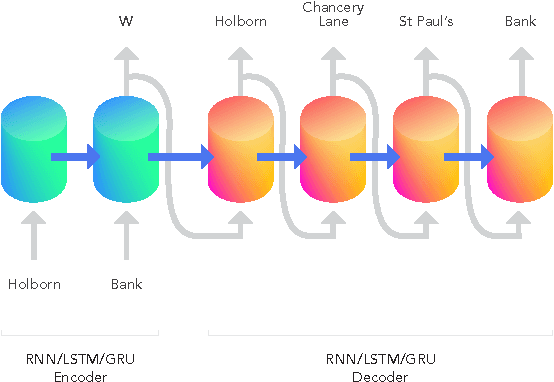
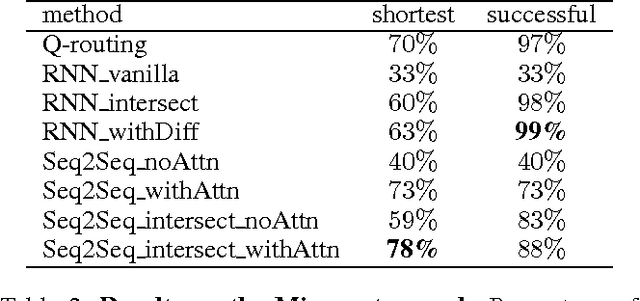
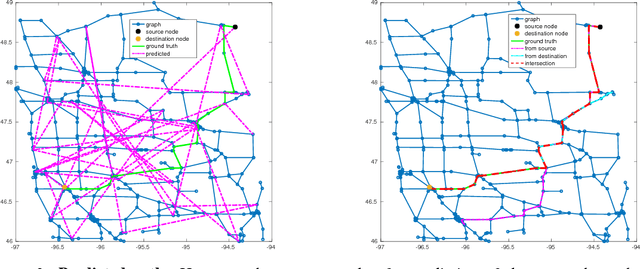
Much combinatorial optimisation problems constitute a non-polynomial (NP) hard optimisation problem, i.e., they can not be solved in polynomial time. One such problem is finding the shortest route between two nodes on a graph. Meta-heuristic algorithms such as $A^{*}$ along with mixed-integer programming (MIP) methods are often employed for these problems. Our work demonstrates that it is possible to approximate solutions generated by a meta-heuristic algorithm using a deep recurrent neural network. We compare different methodologies based on reinforcement learning (RL) and recurrent neural networks (RNN) to gauge their respective quality of approximation. We show the viability of recurrent neural network solutions on a graph that has over 300 nodes and argue that a sequence-to-sequence network rather than other recurrent networks has improved approximation quality. Additionally, we argue that homotopy continuation -- that increases chances of hitting an extremum -- further improves the estimate generated by a vanilla RNN.