 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Dark Side of Calibration for Modern Neural Networks
Paper and Code
Jun 17, 2021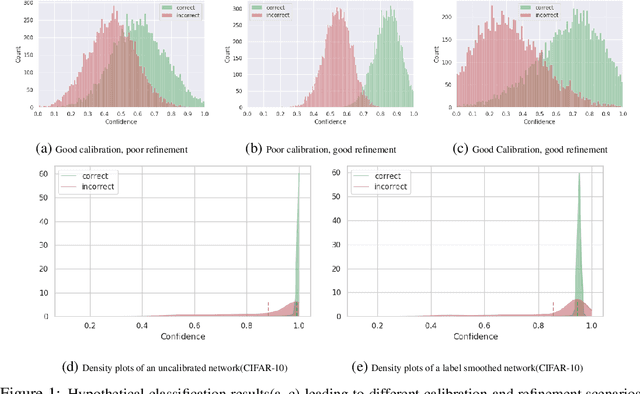

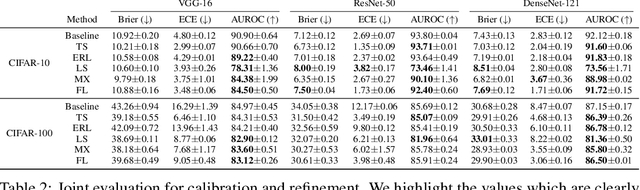
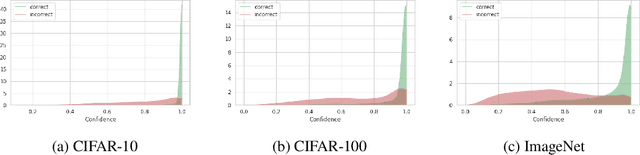
Modern neural networks are highly uncalibrated. It poses a significant challenge for safety-critical systems to utilise deep neural networks (DNNs), reliably. Many recently proposed approaches have demonstrated substantial progress in improving DNN calibration. However, they hardly touch upon refinement, which historically has been an essential aspect of calibration. Refinement indicates separability of a network's correct and incorrect predictions. This paper presents a theoretically and empirically supported exposition for reviewing a model's calibration and refinement. Firstly, we show the breakdown of expected calibration error (ECE), into predicted confidence and refinement. Connecting with this result, we highlight that regularisation based calibration only focuses on naively reducing a model's confidence. This logically has a severe downside to a model's refinement. We support our claims through rigorous empirical evaluations of many state of the art calibration approaches on standard datasets. We find that many calibration approaches with the likes of label smoothing, mixup etc. lower the utility of a DNN by degrading its refinement. Even under natural data shift, this calibration-refinement trade-off holds for the majority of calibration methods. These findings call for an urgent retrospective into some popular pathways taken for modern DNN calibration.