 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep 3D World Models for Multi-Image Super-Resolution Beyond Optical Flow
Jan 30, 2024



Multi-image super-resolution (MISR) allows to increase the spatial resolution of a low-resolution (LR) acquisition by combining multiple images carrying complementary information in the form of sub-pixel offsets in the scene sampling, and can be significantly more effective than its single-image counterpart. Its main difficulty lies in accurately registering and fusing the multi-image information. Currently studied settings, such as burst photography, typically involve assumptions of small geometric disparity between the LR images and rely on optical flow for image registration. We study a MISR method that can increase the resolution of sets of images acquired with arbitrary, and potentially wildly different, camera positions and orientations, generalizing the currently studied MISR settings. Our proposed model, called EpiMISR, moves away from optical flow and explicitly uses the epipolar geometry of the acquisition process, together with transformer-based processing of radiance feature fields to substantially improve over state-of-the-art MISR methods in presence of large disparities in the LR images.
On the Dark Side of Calibration for Modern Neural Networks
Jun 17, 2021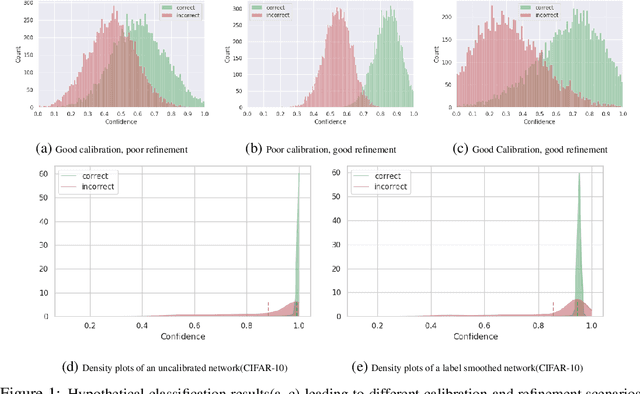

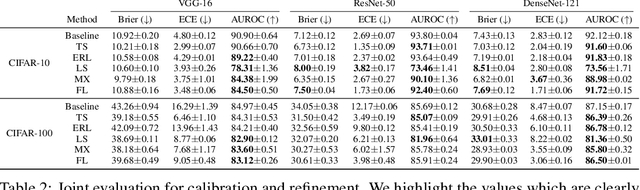
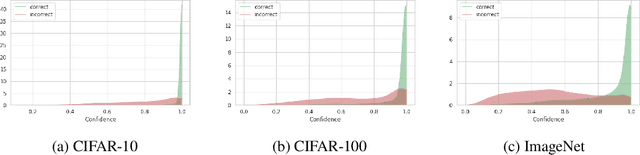
Modern neural networks are highly uncalibrated. It poses a significant challenge for safety-critical systems to utilise deep neural networks (DNNs), reliably. Many recently proposed approaches have demonstrated substantial progress in improving DNN calibration. However, they hardly touch upon refinement, which historically has been an essential aspect of calibration. Refinement indicates separability of a network's correct and incorrect predictions. This paper presents a theoretically and empirically supported exposition for reviewing a model's calibration and refinement. Firstly, we show the breakdown of expected calibration error (ECE), into predicted confidence and refinement. Connecting with this result, we highlight that regularisation based calibration only focuses on naively reducing a model's confidence. This logically has a severe downside to a model's refinement. We support our claims through rigorous empirical evaluations of many state of the art calibration approaches on standard datasets. We find that many calibration approaches with the likes of label smoothing, mixup etc. lower the utility of a DNN by degrading its refinement. Even under natural data shift, this calibration-refinement trade-off holds for the majority of calibration methods. These findings call for an urgent retrospective into some popular pathways taken for modern DNN calibration.
Assessing The Importance Of Colours For CNNs In Object Recognition
Dec 12, 2020
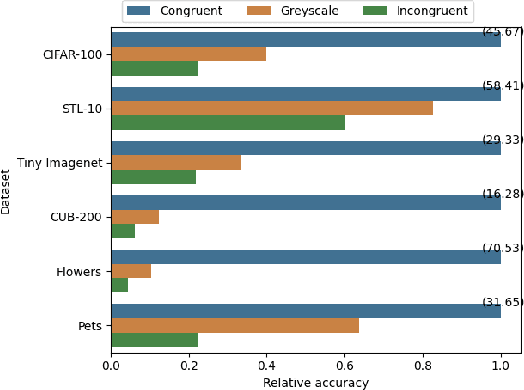

Humans rely heavily on shapes as a primary cue for object recognition. As secondary cues, colours and textures are also beneficial in this regard. Convolutional neural networks (CNNs), an imitation of biological neural networks, have been shown to exhibit conflicting properties. Some studies indicate that CNNs are biased towards textures whereas, another set of studies suggests shape bias for a classification task. However, they do not discuss the role of colours, implying its possible humble role in the task of object recognition. In this paper, we empirically investigate the importance of colours in object recognition for CNNs. We are able to demonstrate that CNNs often rely heavily on colour information while making a prediction. Our results show that the degree of dependency on colours tend to vary from one dataset to another. Moreover, networks tend to rely more on colours if trained from scratch. Pre-training can allow the model to be less colour dependent. To facilitate these findings, we follow the framework often deployed in understanding role of colours in object recognition for humans. We evaluate a model trained with congruent images (images in original colours eg. red strawberries) on congruent, greyscale, and incongruent images (images in unnatural colours eg. blue strawberries). We measure and analyse network's predictive performance (top-1 accuracy) under these different stylisations. We utilise standard datasets of supervised image classification and fine-grained image classification in our experiments.