 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark of Data Preprocessing Methods for Imbalanced Classification
Mar 06, 2023



Severe class imbalance is one of the main conditions that make machine learning in cybersecurity difficult. A variety of dataset preprocessing methods have been introduced over the years. These methods modify the training dataset by oversampling, undersampling or a combination of both to improve the predictive performance of classifiers trained on this dataset. Although these methods are used in cybersecurity occasionally, a comprehensive, unbiased benchmark comparing their performance over a variety of cybersecurity problems is missing. This paper presents a benchmark of 16 preprocessing methods on six cybersecurity datasets together with 17 public imbalanced datasets from other domains. We test the methods under multiple hyperparameter configurations and use an AutoML system to train classifiers on the preprocessed datasets, which reduces potential bias from specific hyperparameter or classifier choices. Special consideration is also given to evaluating the methods using appropriate performance measures that are good proxies for practical performance in real-world cybersecurity systems. The main findings of our study are: 1) Most of the time, a data preprocessing method that improves classification performance exists. 2) Baseline approach of doing nothing outperformed a large portion of methods in the benchmark. 3) Oversampling methods generally outperform undersampling methods. 4) The most significant performance gains are brought by the standard SMOTE algorithm and more complicated methods provide mainly incremental improvements at the cost of often worse computational performance.
On Model Evaluation under Non-constant Class Imbalance
Jan 15, 2020

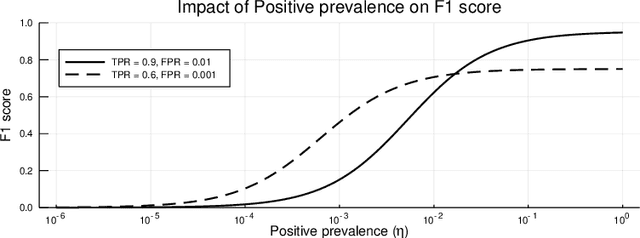
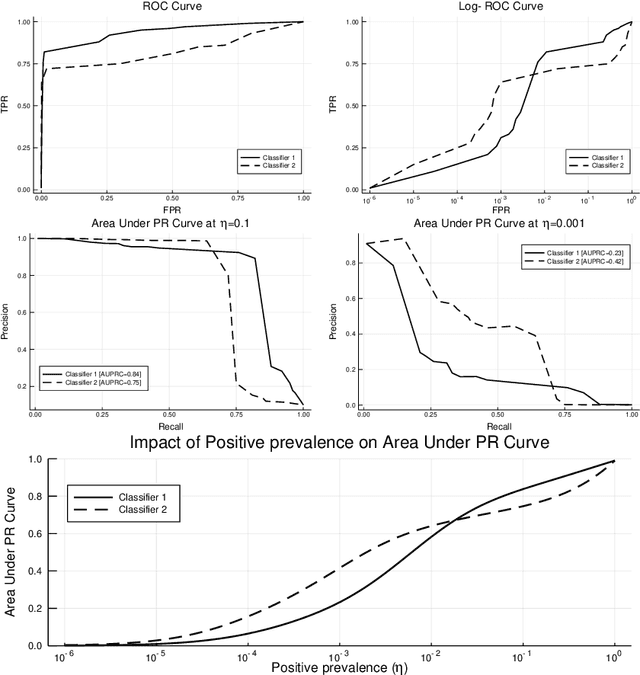
Many real-world classification problems are significantly class-imbalanced to detriment of the class of interest. The standard set of proper evaluation metrics is well-known but the usual assumption is that the test dataset imbalance equals the real-world imbalance. In practice, this assumption is often broken for various reasons. The reported results are then often too optimistic and may lead to wrong conclusions about industrial impact and suitability of proposed techniques. We introduce methods focusing on evaluation under non-constant class imbalance. We show that not only the absolute values of commonly used metrics, but even the order of classifiers in relation to the evaluation metric used is affected by the change of the imbalance rate. Finally, we demonstrate that using subsampling in order to get a test dataset with class imbalance equal to the one observed in the wild is not necessary, and eventually can lead to significant errors in classifier's performance estimate.