 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye-Tracking-while-Reading: A Living Survey of Datasets with Open Library Support
Feb 23, 2026Eye-tracking-while-reading corpora are a valuable resource for many different disciplines and use cases. Use cases range from studying the cognitive processes underlying reading to machine-learning-based applications, such as gaze-based assessments of reading comprehension. The past decades have seen an increase in the number and size of eye-tracking-while-reading datasets as well as increasing diversity with regard to the stimulus languages covered, the linguistic background of the participants, or accompanying psychometric or demographic data. The spread of data across different disciplines and the lack of data sharing standards across the communities lead to many existing datasets that cannot be easily reused due to a lack of interoperability. In this work, we aim at creating more transparency and clarity with regards to existing datasets and their features across different disciplines by i) presenting an extensive overview of existing datasets, ii) simplifying the sharing of newly created datasets by publishing a living overview online, https://dili-lab.github.io/datasets.html, presenting over 45 features for each dataset, and iii) integrating all publicly available datasets into the Python package pymovements which offers an eye-tracking datasets library. By doing so, we aim to strengthen the FAIR principles in eye-tracking-while-reading research and promote good scientific practices, such as reproducing and replicating studies.
Reporting Eye-Tracking Data Quality: Towards a New Standard
Mar 31, 2024Eye-tracking datasets are often shared in the format used by their creators for their original analyses, usually resulting in the exclusion of data considered irrelevant to the primary purpose. In order to increase re-usability of existing eye-tracking datasets for more diverse and initially not considered use cases, this work advocates a new approach of sharing eye-tracking data. Instead of publishing filtered and pre-processed datasets, the eye-tracking data at all pre-processing stages should be published together with data quality reports. In order to transparently report data quality and enable cross-dataset comparisons, we develop data quality reporting standards and metrics that can be automatically applied to a dataset, and integrate them into the open-source Python package pymovements (https://github.com/aeye-lab/pymovements).
PoTeC: A German Naturalistic Eye-tracking-while-reading Corpus
Mar 01, 2024The Potsdam Textbook Corpus (PoTeC) is a naturalistic eye-tracking-while-reading corpus containing data from 75 participants reading 12 scientific texts. PoTeC is the first naturalistic eye-tracking-while-reading corpus that contains eye-movements from domain-experts as well as novices in a within-participant manipulation: It is based on a 2x2x2 fully-crossed factorial design which includes the participants' level of study and the participants' discipline of study as between-subject factors and the text domain as a within-subject factor. The participants' reading comprehension was assessed by a series of text comprehension questions and their domain knowledge was tested by text-independent background questions for each of the texts. The materials are annotated for a variety of linguistic features at different levels. We envision PoTeC to be used for a wide range of studies including but not limited to analyses of expert and non-expert reading strategies. The corpus and all the accompanying data at all stages of the preprocessing pipeline and all code used to preprocess the data are made available via GitHub: https://github.com/DiLi-Lab/PoTeC.
ScanDL: A Diffusion Model for Generating Synthetic Scanpaths on Texts
Oct 24, 2023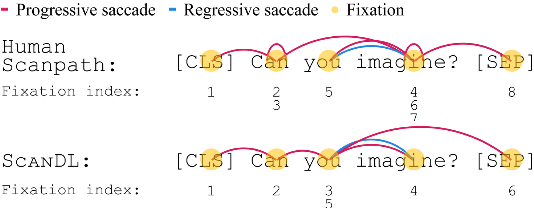
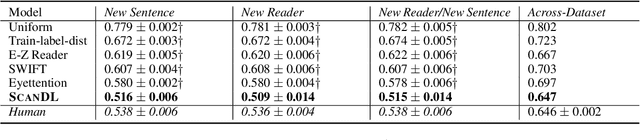


Eye movements in reading play a crucial role in psycholinguistic research studying the cognitive mechanisms underlying human language processing. More recently, the tight coupling between eye movements and cognition has also been leveraged for language-related machine learning tasks such as the interpretability, enhancement, and pre-training of language models, as well as the inference of reader- and text-specific properties. However, scarcity of eye movement data and its unavailability at application time poses a major challenge for this line of research. Initially, this problem was tackled by resorting to cognitive models for synthesizing eye movement data. However, for the sole purpose of generating human-like scanpaths, purely data-driven machine-learning-based methods have proven to be more suitable. Following recent advances in adapting diffusion processes to discrete data, we propose ScanDL, a novel discrete sequence-to-sequence diffusion model that generates synthetic scanpaths on texts. By leveraging pre-trained word representations and jointly embedding both the stimulus text and the fixation sequence, our model captures multi-modal interactions between the two inputs. We evaluate ScanDL within- and across-dataset and demonstrate that it significantly outperforms state-of-the-art scanpath generation methods. Finally, we provide an extensive psycholinguistic analysis that underlines the model's ability to exhibit human-like reading behavior. Our implementation is made available at https://github.com/DiLi-Lab/ScanDL.