 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame Theory with Simulation in the Presence of Unpredictable Randomisation
Oct 18, 2024
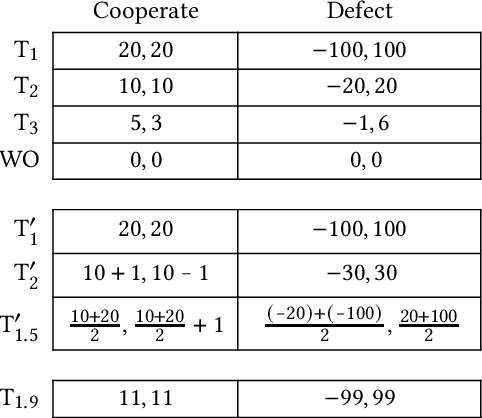
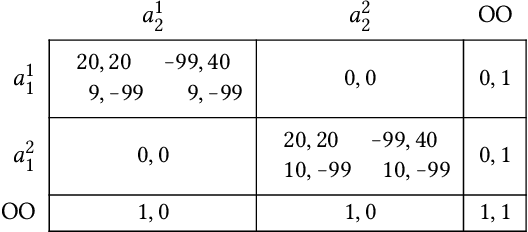

AI agents will be predictable in certain ways that traditional agents are not. Where and how can we leverage this predictability in order to improve social welfare? We study this question in a game-theoretic setting where one agent can pay a fixed cost to simulate the other in order to learn its mixed strategy. As a negative result, we prove that, in contrast to prior work on pure-strategy simulation, enabling mixed-strategy simulation may no longer lead to improved outcomes for both players in all so-called "generalised trust games". In fact, mixed-strategy simulation does not help in any game where the simulatee's action can depend on that of the simulator. We also show that, in general, deciding whether simulation introduces Pareto-improving Nash equilibria in a given game is NP-hard. As positive results, we establish that mixed-strategy simulation can improve social welfare if the simulator has the option to scale their level of trust, if the players face challenges with both trust and coordination, or if maintaining some level of privacy is essential for enabling cooperation.
Recursive Joint Simulation in Games
Feb 12, 2024


Game-theoretic dynamics between AI agents could differ from traditional human-human interactions in various ways. One such difference is that it may be possible to accurately simulate an AI agent, for example because its source code is known. Our aim is to explore ways of leveraging this possibility to achieve more cooperative outcomes in strategic settings. In this paper, we study an interaction between AI agents where the agents run a recursive joint simulation. That is, the agents first jointly observe a simulation of the situation they face. This simulation in turn recursively includes additional simulations (with a small chance of failure, to avoid infinite recursion), and the results of all these nested simulations are observed before an action is chosen. We show that the resulting interaction is strategically equivalent to an infinitely repeated version of the original game, allowing a direct transfer of existing results such as the various folk theorems.
Approximation capability of neural networks on spaces of probability measures and tree-structured domains
Jun 03, 2019
This paper extends the proof of density of neural networks in the space of continuous (or even measurable) functions on Euclidean spaces to functions on compact sets of probability measures. By doing so the work parallels a more then a decade old results on mean-map embedding of probability measures in reproducing kernel Hilbert spaces. The work has wide practical consequences for multi-instance learning, where it theoretically justifies some recently proposed constructions. The result is then extended to Cartesian products, yielding universal approximation theorem for tree-structured domains, which naturally occur in data-exchange formats like JSON, XML, YAML, AVRO, and ProtoBuffer. This has important practical implications, as it enables to automatically create an architecture of neural networks for processing structured data (AutoML paradigms), as demonstrated by an accompanied library for JSON format.