 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOuter-Learning Framework for Playing Multi-Player Trick-Taking Card Games: A Case Study in Skat
Dec 17, 2025In multi-player card games such as Skat or Bridge, the early stages of the game, such as bidding, game selection, and initial card selection, are often more critical to the success of the play than refined middle- and end-game play. At the current limits of computation, such early decision-making resorts to using statistical information derived from a large corpus of human expert games. In this paper, we derive and evaluate a general bootstrapping outer-learning framework that improves prediction accuracy by expanding the database of human games with millions of self-playing AI games to generate and merge statistics. We implement perfect feature hash functions to address compacted tables, producing a self-improving card game engine, where newly inferred knowledge is continuously improved during self-learning. The case study in Skat shows that the automated approach can be used to support various decisions in the game.
Solving Multi-Agent Multi-Goal Path Finding Problems in Polynomial Time
Dec 17, 2025In this paper, we plan missions for a fleet of agents in undirected graphs, such as grids, with multiple goals. In contrast to regular multi-agent path-finding, the solver finds and updates the assignment of goals to the agents on its own. In the continuous case for a point agent with motions in the Euclidean plane, the problem can be solved arbitrarily close to optimal. For discrete variants that incur node and edge conflicts, we show that it can be solved in polynomial time, which is unexpected, since traditional vehicle routing on general graphs is NP-hard. We implement a corresponding planner that finds conflict-free optimized routes for the agents. Global assignment strategies greatly reduce the number of conflicts, with the remaining ones resolved by elaborating on the concept of ants-on-the-stick, by solving local assignment problems, by interleaving agent paths, and by kicking agents that have already arrived out of their destinations
Planning with Vision-Language Models and a Use Case in Robot-Assisted Teaching
Jan 29, 2025



Automating the generation of Planning Domain Definition Language (PDDL) with Large Language Model (LLM) opens new research topic in AI planning, particularly for complex real-world tasks. This paper introduces Image2PDDL, a novel framework that leverages Vision-Language Models (VLMs) to automatically convert images of initial states and descriptions of goal states into PDDL problems. By providing a PDDL domain alongside visual inputs, Imasge2PDDL addresses key challenges in bridging perceptual understanding with symbolic planning, reducing the expertise required to create structured problem instances, and improving scalability across tasks of varying complexity. We evaluate the framework on various domains, including standard planning domains like blocksworld and sliding tile puzzles, using datasets with multiple difficulty levels. Performance is assessed on syntax correctness, ensuring grammar and executability, and content correctness, verifying accurate state representation in generated PDDL problems. The proposed approach demonstrates promising results across diverse task complexities, suggesting its potential for broader applications in AI planning. We will discuss a potential use case in robot-assisted teaching of students with Autism Spectrum Disorder.
Heuristic Planner for Communication-Constrained Multi-Agent Multi-Goal Path Planning
Dec 18, 2024


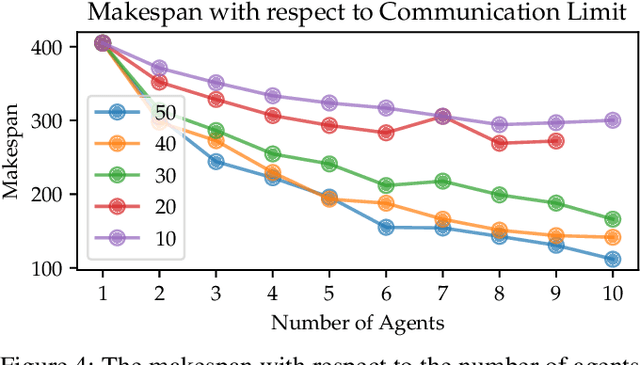
In robotics, coordinating a group of robots is an essential task. This work presents the communication-constrained multi-agent multi-goal path planning problem and proposes a graph-search based algorithm to address this task. Given a fleet of robots, an environment represented by a weighted graph, and a sequence of goals, the aim is to visit all the goals without breaking the communication constraints between the agents, minimizing the completion time. The resulting paths produced by our approach show how the agents can coordinate their individual paths, not only with respect to the next goal but also with respect to all future goals, all the time keeping the communication within the fleet intact.
SIL-RRT*: Learning Sampling Distribution through Self Imitation Learning
Nov 26, 2024Efficiently finding safe and feasible trajectories for mobile objects is a critical field in robotics and computer science. In this paper, we propose SIL-RRT*, a novel learning-based motion planning algorithm that extends the RRT* algorithm by using a deep neural network to predict a distribution for sampling at each iteration. We evaluate SIL-RRT* on various 2D and 3D environments and establish that it can efficiently solve high-dimensional motion planning problems with fewer samples than traditional sampling-based algorithms. Moreover, SIL-RRT* is able to scale to more complex environments, making it a promising approach for solving challenging robotic motion planning problems.
CLIP-Motion: Learning Reward Functions for Robotic Actions Using Consecutive Observations
Nov 06, 2023



This paper presents a novel method for learning reward functions for robotic motions by harnessing the power of a CLIP-based model. Traditional reward function design often hinges on manual feature engineering, which can struggle to generalize across an array of tasks. Our approach circumvents this challenge by capitalizing on CLIP's capability to process both state features and image inputs effectively. Given a pair of consecutive observations, our model excels in identifying the motion executed between them. We showcase results spanning various robotic activities, such as directing a gripper to a designated target and adjusting the position of a cube. Through experimental evaluations, we underline the proficiency of our method in precisely deducing motion and its promise to enhance reinforcement learning training in the realm of robotics.
Optimize Planning Heuristics to Rank, not to Estimate Cost-to-Goal
Oct 30, 2023In imitation learning for planning, parameters of heuristic functions are optimized against a set of solved problem instances. This work revisits the necessary and sufficient conditions of strictly optimally efficient heuristics for forward search algorithms, mainly A* and greedy best-first search, which expand only states on the returned optimal path. It then proposes a family of loss functions based on ranking tailored for a given variant of the forward search algorithm. Furthermore, from a learning theory point of view, it discusses why optimizing cost-to-goal \hstar\ is unnecessarily difficult. The experimental comparison on a diverse set of problems unequivocally supports the derived theory.
A Differentiable Loss Function for Learning Heuristics in A*
Sep 12, 2022
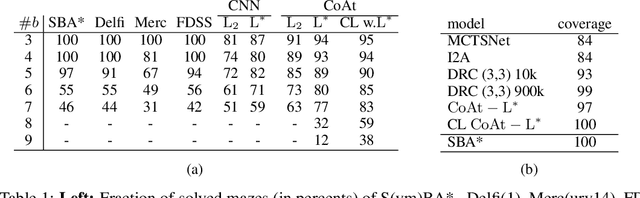
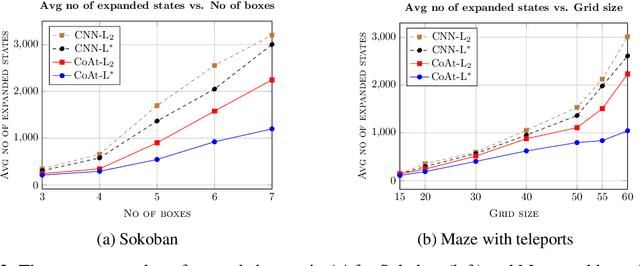
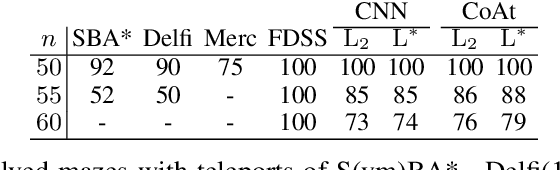
Optimization of heuristic functions for the A* algorithm, realized by deep neural networks, is usually done by minimizing square root loss of estimate of the cost to goal values. This paper argues that this does not necessarily lead to a faster search of A* algorithm since its execution relies on relative values instead of absolute ones. As a mitigation, we propose a L* loss, which upper-bounds the number of excessively expanded states inside the A* search. The L* loss, when used in the optimization of state-of-the-art deep neural networks for automated planning in maze domains like Sokoban and maze with teleports, significantly improves the fraction of solved problems, the quality of founded plans, and reduces the number of expanded states to approximately 50%
Heuristic Search Planning with Deep Neural Networks using Imitation, Attention and Curriculum Learning
Dec 03, 2021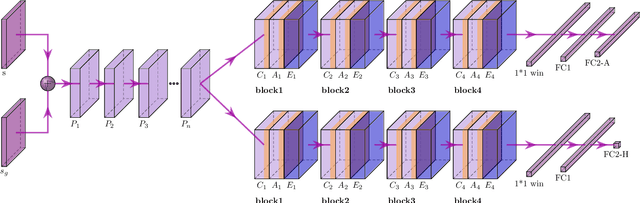
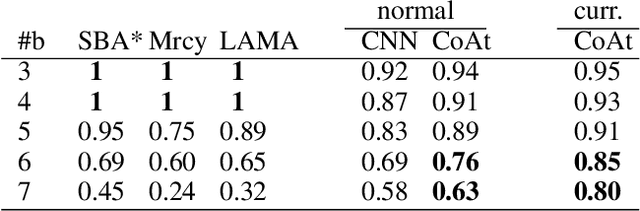
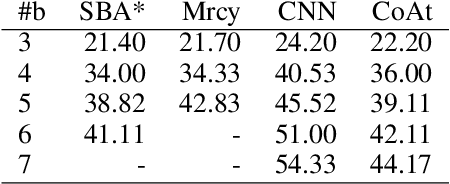
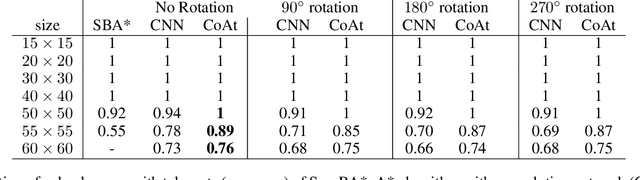
Learning a well-informed heuristic function for hard task planning domains is an elusive problem. Although there are known neural network architectures to represent such heuristic knowledge, it is not obvious what concrete information is learned and whether techniques aimed at understanding the structure help in improving the quality of the heuristics. This paper presents a network model to learn a heuristic capable of relating distant parts of the state space via optimal plan imitation using the attention mechanism, which drastically improves the learning of a good heuristic function. To counter the limitation of the method in the creation of problems of increasing difficulty, we demonstrate the use of curriculum learning, where newly solved problem instances are added to the training set, which, in turn, helps to solve problems of higher complexities and far exceeds the performances of all existing baselines including classical planning heuristics. We demonstrate its effectiveness for grid-type PDDL domains.
Knowledge-Based Paranoia Search in Trick-Taking
Apr 07, 2021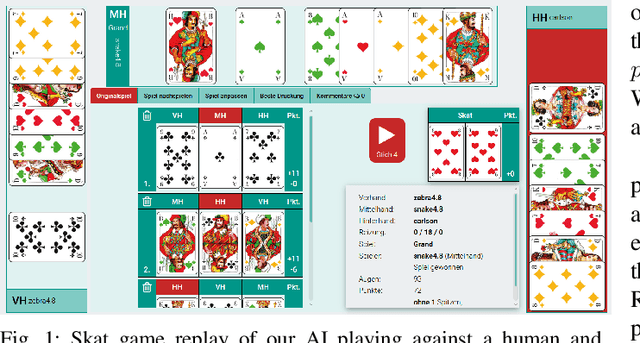



This paper proposes \emph{knowledge-based paraonoia search} (KBPS) to find forced wins during trick-taking in the card game Skat; for some one of the most interesting card games for three players. It combines efficient partial information game-tree search with knowledge representation and reasoning. This worst-case analysis, initiated after a small number of tricks, leads to a prioritized choice of cards. We provide variants of KBPS for the declarer and the opponents, and an approximation to find a forced win against most worlds in the belief space. Replaying thousands of expert games, our evaluation indicates that the AIs with the new algorithms perform better than humans in their play, achieving an average score of over 1,000 points in the agreed standard for evaluating Skat tournaments, the extended Seeger system.