 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: The Influence of Pruning on the Explainability of CNNs
Feb 17, 2023Modern, state-of-the-art Convolutional Neural Networks (CNNs) in computer vision have millions of parameters. Thus, explaining the complex decisions of such networks to humans is challenging. A technical approach to reduce CNN complexity is network pruning, where less important parameters are deleted. The work presented in this paper investigates whether this technical complexity reduction also helps with perceived explainability. To do so, we conducted a pre-study and two human-grounded experiments, assessing the effects of different pruning ratios on CNN explainability. Overall, we evaluated four different compression rates (i.e., CPR 2, 4, 8, and 32) with 37 500 tasks on Mechanical Turk. Results indicate that lower compression rates have a positive influence on explainability, while higher compression rates show negative effects. Furthermore, we were able to identify sweet spots that increase both the perceived explainability and the model's performance.
On the Effect of Adversarial Training Against Invariance-based Adversarial Examples
Feb 16, 2023
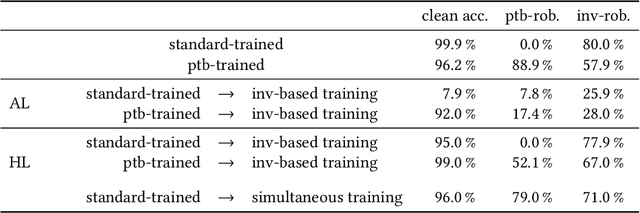


Adversarial examples are carefully crafted attack points that are supposed to fool machine learning classifiers. In the last years, the field of adversarial machine learning, especially the study of perturbation-based adversarial examples, in which a perturbation that is not perceptible for humans is added to the images, has been studied extensively. Adversarial training can be used to achieve robustness against such inputs. Another type of adversarial examples are invariance-based adversarial examples, where the images are semantically modified such that the predicted class of the model does not change, but the class that is determined by humans does. How to ensure robustness against this type of adversarial examples has not been explored yet. This work addresses the impact of adversarial training with invariance-based adversarial examples on a convolutional neural network (CNN). We show that when adversarial training with invariance-based and perturbation-based adversarial examples is applied, it should be conducted simultaneously and not consecutively. This procedure can achieve relatively high robustness against both types of adversarial examples. Additionally, we find that the algorithm used for generating invariance-based adversarial examples in prior work does not correctly determine the labels and therefore we use human-determined labels.
HE-MAN -- Homomorphically Encrypted MAchine learning with oNnx models
Feb 16, 2023



Machine learning (ML) algorithms are increasingly important for the success of products and services, especially considering the growing amount and availability of data. This also holds for areas handling sensitive data, e.g. applications processing medical data or facial images. However, people are reluctant to pass their personal sensitive data to a ML service provider. At the same time, service providers have a strong interest in protecting their intellectual property and therefore refrain from publicly sharing their ML model. Fully homomorphic encryption (FHE) is a promising technique to enable individuals using ML services without giving up privacy and protecting the ML model of service providers at the same time. Despite steady improvements, FHE is still hardly integrated in today's ML applications. We introduce HE-MAN, an open-source two-party machine learning toolset for privacy preserving inference with ONNX models and homomorphically encrypted data. Both the model and the input data do not have to be disclosed. HE-MAN abstracts cryptographic details away from the users, thus expertise in FHE is not required for either party. HE-MAN 's security relies on its underlying FHE schemes. For now, we integrate two different homomorphic encryption schemes, namely Concrete and TenSEAL. Compared to prior work, HE-MAN supports a broad range of ML models in ONNX format out of the box without sacrificing accuracy. We evaluate the performance of our implementation on different network architectures classifying handwritten digits and performing face recognition and report accuracy and latency of the homomorphically encrypted inference. Cryptographic parameters are automatically derived by the tools. We show that the accuracy of HE-MAN is on par with models using plaintext input while inference latency is several orders of magnitude higher compared to the plaintext case.
Pruning in the Face of Adversaries
Aug 19, 2021
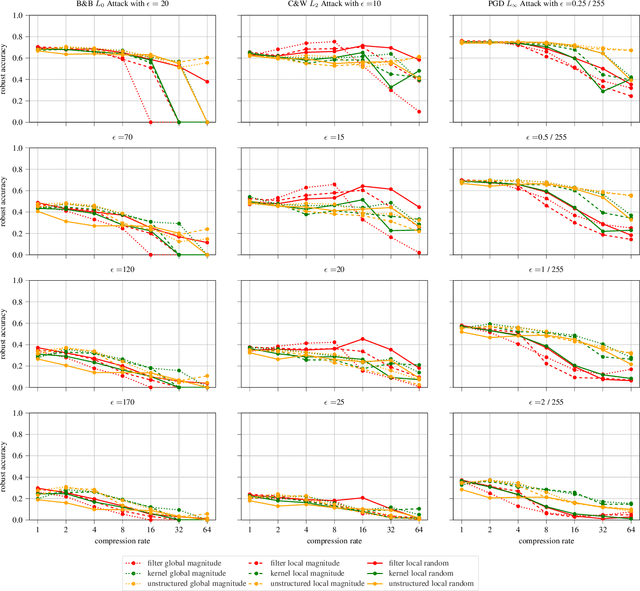
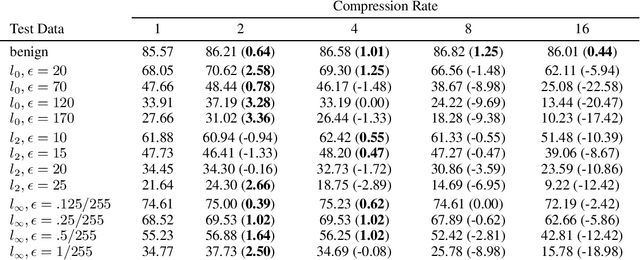
The vulnerability of deep neural networks against adversarial examples - inputs with small imperceptible perturbations - has gained a lot of attention in the research community recently. Simultaneously, the number of parameters of state-of-the-art deep learning models has been growing massively, with implications on the memory and computational resources required to train and deploy such models. One approach to control the size of neural networks is retrospectively reducing the number of parameters, so-called neural network pruning. Available research on the impact of neural network pruning on the adversarial robustness is fragmentary and often does not adhere to established principles of robustness evaluation. We close this gap by evaluating the robustness of pruned models against L-0, L-2 and L-infinity attacks for a wide range of attack strengths, several architectures, data sets, pruning methods, and compression rates. Our results confirm that neural network pruning and adversarial robustness are not mutually exclusive. Instead, sweet spots can be found that are favorable in terms of model size and adversarial robustness. Furthermore, we extend our analysis to situations that incorporate additional assumptions on the adversarial scenario and show that depending on the situation, different strategies are optimal.
When Should You Defend Your Classifier -- A Game-theoretical Analysis of Countermeasures against Adversarial Examples
Aug 17, 2021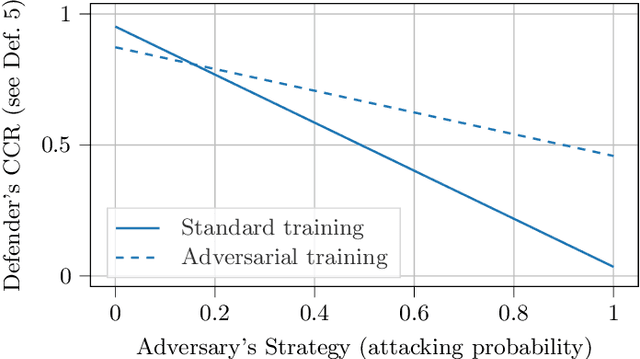
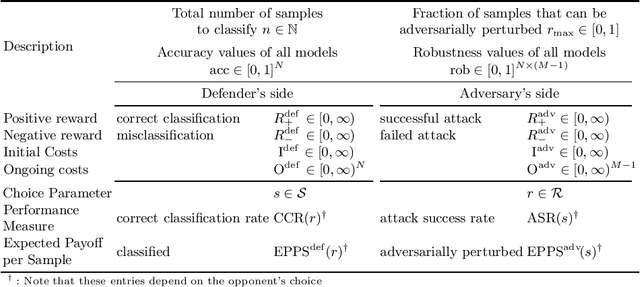

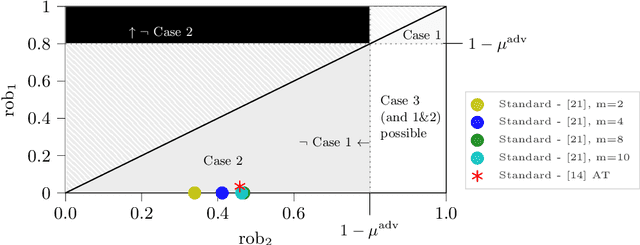
Adversarial machine learning, i.e., increasing the robustness of machine learning algorithms against so-called adversarial examples, is now an established field. Yet, newly proposed methods are evaluated and compared under unrealistic scenarios where costs for adversary and defender are not considered and either all samples are attacked or no sample is attacked. We scrutinize these assumptions and propose the advanced adversarial classification game, which incorporates all relevant parameters of an adversary and a defender in adversarial classification. Especially, we take into account economic factors on both sides and the fact that all so far proposed countermeasures against adversarial examples reduce accuracy on benign samples. Analyzing the scenario in detail, where both players have two pure strategies, we identify all best responses and conclude that in practical settings, the most influential factor might be the maximum amount of adversarial examples.
Machine Unlearning: Linear Filtration for Logit-based Classifiers
Feb 07, 2020



Recently enacted legislation grants individuals certain rights to decide in what fashion their personal data may be used, and in particular a "right to be forgotten". This poses a challenge to machine learning: how to proceed when an individual retracts permission to use data which has been part of the training process of a model? From this question emerges the field of machine unlearning, which could be broadly described as the investigation of how to "delete training data from models". Our work complements this direction of research for the specific setting of class-wide deletion requests for classification models (e.g. deep neural networks). As a first step, we propose linear filtration as a computationally efficient sanitization method. Our experiments demonstrate benefits in an adversarial setting over naive deletion schemes.