 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable and Class-Revealing Signal Feature Extraction via Scattering Transform and Constrained Zeroth-Order Optimization
Feb 08, 2025We propose a new method to extract discriminant and explainable features from a particular machine learning model, i.e., a combination of the scattering transform and the multiclass logistic regression. Although this model is well-known for its ability to learn various signal classes with high classification rate, it remains elusive to understand why it can generate such successful classification, mainly due to the nonlinearity of the scattering transform. In order to uncover the meaning of the scattering transform coefficients selected by the multiclass logistic regression (with the Lasso penalty), we adopt zeroth-order optimization algorithms to search an input pattern that maximizes the class probability of a class of interest given the learned model. In order to do so, it turns out that imposing sparsity and smoothness of input patterns is important. We demonstrate the effectiveness of our proposed method using a couple of synthetic time-series classification problems.
Less is More: The Influence of Pruning on the Explainability of CNNs
Feb 17, 2023Modern, state-of-the-art Convolutional Neural Networks (CNNs) in computer vision have millions of parameters. Thus, explaining the complex decisions of such networks to humans is challenging. A technical approach to reduce CNN complexity is network pruning, where less important parameters are deleted. The work presented in this paper investigates whether this technical complexity reduction also helps with perceived explainability. To do so, we conducted a pre-study and two human-grounded experiments, assessing the effects of different pruning ratios on CNN explainability. Overall, we evaluated four different compression rates (i.e., CPR 2, 4, 8, and 32) with 37 500 tasks on Mechanical Turk. Results indicate that lower compression rates have a positive influence on explainability, while higher compression rates show negative effects. Furthermore, we were able to identify sweet spots that increase both the perceived explainability and the model's performance.
The Scattering Transform Network with Generalized Morse Wavelets and Its Application to Music Genre Classification
Jun 16, 2022
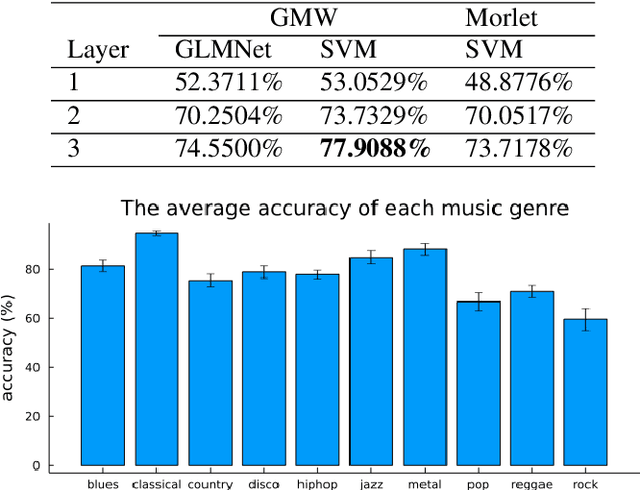
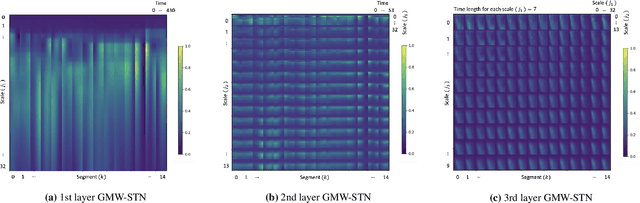
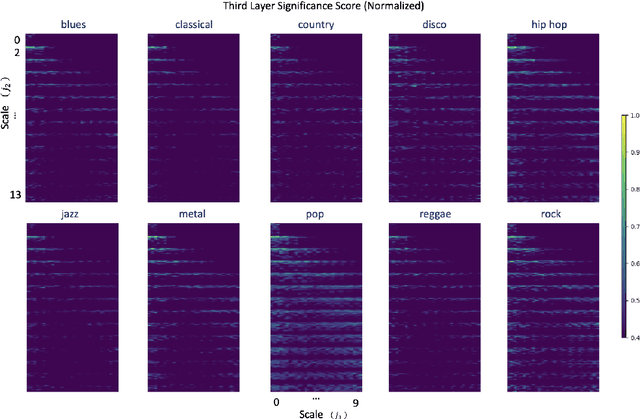
We propose to use the Generalized Morse Wavelets (GMWs) instead of commonly-used Morlet (or Gabor) wavelets in the Scattering Transform Network (STN), which we call the GMW-STN, for signal classification problems. The GMWs form a parameterized family of truly analytic wavelets while the Morlet wavelets are only approximately analytic. The analyticity of underlying wavelet filters in the STN is particularly important for nonstationary oscillatory signals such as music signals because it improves interpretability of the STN representations by providing multiscale amplitude and phase (and consequently frequency) information of input signals. We demonstrate the superiority of the GMW-STN over the conventional STN in music genre classification using the so-called GTZAN database. Moreover, we show the performance improvement of the GMW-STN by increasing its number of layers to three over the typical two-layer STN.}
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.