 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHE-MAN -- Homomorphically Encrypted MAchine learning with oNnx models
Feb 16, 2023



Machine learning (ML) algorithms are increasingly important for the success of products and services, especially considering the growing amount and availability of data. This also holds for areas handling sensitive data, e.g. applications processing medical data or facial images. However, people are reluctant to pass their personal sensitive data to a ML service provider. At the same time, service providers have a strong interest in protecting their intellectual property and therefore refrain from publicly sharing their ML model. Fully homomorphic encryption (FHE) is a promising technique to enable individuals using ML services without giving up privacy and protecting the ML model of service providers at the same time. Despite steady improvements, FHE is still hardly integrated in today's ML applications. We introduce HE-MAN, an open-source two-party machine learning toolset for privacy preserving inference with ONNX models and homomorphically encrypted data. Both the model and the input data do not have to be disclosed. HE-MAN abstracts cryptographic details away from the users, thus expertise in FHE is not required for either party. HE-MAN 's security relies on its underlying FHE schemes. For now, we integrate two different homomorphic encryption schemes, namely Concrete and TenSEAL. Compared to prior work, HE-MAN supports a broad range of ML models in ONNX format out of the box without sacrificing accuracy. We evaluate the performance of our implementation on different network architectures classifying handwritten digits and performing face recognition and report accuracy and latency of the homomorphically encrypted inference. Cryptographic parameters are automatically derived by the tools. We show that the accuracy of HE-MAN is on par with models using plaintext input while inference latency is several orders of magnitude higher compared to the plaintext case.
On the Effect of Adversarial Training Against Invariance-based Adversarial Examples
Feb 16, 2023
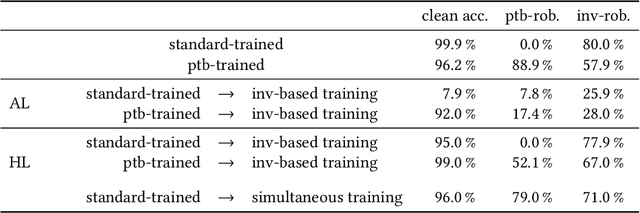


Adversarial examples are carefully crafted attack points that are supposed to fool machine learning classifiers. In the last years, the field of adversarial machine learning, especially the study of perturbation-based adversarial examples, in which a perturbation that is not perceptible for humans is added to the images, has been studied extensively. Adversarial training can be used to achieve robustness against such inputs. Another type of adversarial examples are invariance-based adversarial examples, where the images are semantically modified such that the predicted class of the model does not change, but the class that is determined by humans does. How to ensure robustness against this type of adversarial examples has not been explored yet. This work addresses the impact of adversarial training with invariance-based adversarial examples on a convolutional neural network (CNN). We show that when adversarial training with invariance-based and perturbation-based adversarial examples is applied, it should be conducted simultaneously and not consecutively. This procedure can achieve relatively high robustness against both types of adversarial examples. Additionally, we find that the algorithm used for generating invariance-based adversarial examples in prior work does not correctly determine the labels and therefore we use human-determined labels.