 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelay-Aware Diffusion Policy: Bridging the Observation-Execution Gap in Dynamic Tasks
Dec 08, 2025
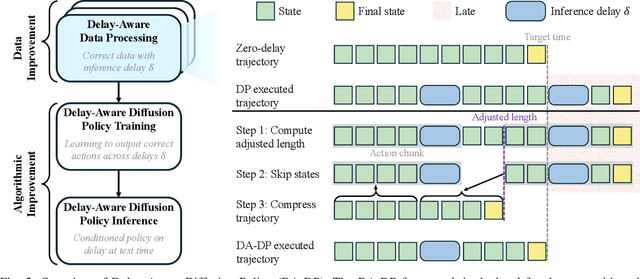


As a robot senses and selects actions, the world keeps changing. This inference delay creates a gap of tens to hundreds of milliseconds between the observed state and the state at execution. In this work, we take the natural generalization from zero delay to measured delay during training and inference. We introduce Delay-Aware Diffusion Policy (DA-DP), a framework for explicitly incorporating inference delays into policy learning. DA-DP corrects zero-delay trajectories to their delay-compensated counterparts, and augments the policy with delay conditioning. We empirically validate DA-DP on a variety of tasks, robots, and delays and find its success rate more robust to delay than delay-unaware methods. DA-DP is architecture agnostic and transfers beyond diffusion policies, offering a general pattern for delay-aware imitation learning. More broadly, DA-DP encourages evaluation protocols that report performance as a function of measured latency, not just task difficulty.
Co-Learning Empirical Games and World Models
May 23, 2023Game-based decision-making involves reasoning over both world dynamics and strategic interactions among the agents. Typically, empirical models capturing these respective aspects are learned and used separately. We investigate the potential gain from co-learning these elements: a world model for dynamics and an empirical game for strategic interactions. Empirical games drive world models toward a broader consideration of possible game dynamics induced by a diversity of strategy profiles. Conversely, world models guide empirical games to efficiently discover new strategies through planning. We demonstrate these benefits first independently, then in combination as realized by a new algorithm, Dyna-PSRO, that co-learns an empirical game and a world model. When compared to PSRO -- a baseline empirical-game building algorithm, Dyna-PSRO is found to compute lower regret solutions on partially observable general-sum games. In our experiments, Dyna-PSRO also requires substantially fewer experiences than PSRO, a key algorithmic advantage for settings where collecting player-game interaction data is a cost-limiting factor.
Population-based Evaluation in Repeated Rock-Paper-Scissors as a Benchmark for Multiagent Reinforcement Learning
Mar 02, 2023



Progress in fields of machine learning and adversarial planning has benefited significantly from benchmark domains, from checkers and the classic UCI data sets to Go and Diplomacy. In sequential decision-making, agent evaluation has largely been restricted to few interactions against experts, with the aim to reach some desired level of performance (e.g. beating a human professional player). We propose a benchmark for multiagent learning based on repeated play of the simple game Rock, Paper, Scissors along with a population of forty-three tournament entries, some of which are intentionally sub-optimal. We describe metrics to measure the quality of agents based both on average returns and exploitability. We then show that several RL, online learning, and language model approaches can learn good counter-strategies and generalize well, but ultimately lose to the top-performing bots, creating an opportunity for research in multiagent learning.