 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Information Theoretic Active Inverse Reinforcement Learning
Dec 31, 2024As AI systems become increasingly autonomous, aligning their decision-making to human preferences is essential. In domains like autonomous driving or robotics, it is impossible to write down the reward function representing these preferences by hand. Inverse reinforcement learning (IRL) offers a promising approach to infer the unknown reward from demonstrations. However, obtaining human demonstrations can be costly. Active IRL addresses this challenge by strategically selecting the most informative scenarios for human demonstration, reducing the amount of required human effort. Where most prior work allowed querying the human for an action at one state at a time, we motivate and analyse scenarios where we collect longer trajectories. We provide an information-theoretic acquisition function, propose an efficient approximation scheme, and illustrate its performance through a set of gridworld experiments as groundwork for future work expanding to more general settings.
Walking the Values in Bayesian Inverse Reinforcement Learning
Jul 15, 2024
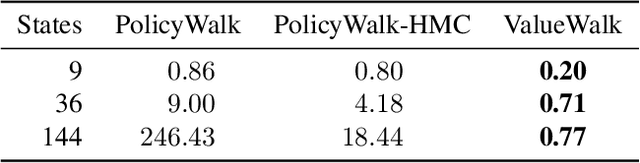


The goal of Bayesian inverse reinforcement learning (IRL) is recovering a posterior distribution over reward functions using a set of demonstrations from an expert optimizing for a reward unknown to the learner. The resulting posterior over rewards can then be used to synthesize an apprentice policy that performs well on the same or a similar task. A key challenge in Bayesian IRL is bridging the computational gap between the hypothesis space of possible rewards and the likelihood, often defined in terms of Q values: vanilla Bayesian IRL needs to solve the costly forward planning problem - going from rewards to the Q values - at every step of the algorithm, which may need to be done thousands of times. We propose to solve this by a simple change: instead of focusing on primarily sampling in the space of rewards, we can focus on primarily working in the space of Q-values, since the computation required to go from Q-values to reward is radically cheaper. Furthermore, this reversion of the computation makes it easy to compute the gradient allowing efficient sampling using Hamiltonian Monte Carlo. We propose ValueWalk - a new Markov chain Monte Carlo method based on this insight - and illustrate its advantages on several tasks.
Negative Human Rights as a Basis for Long-term AI Safety and Regulation
Aug 31, 2022
If future AI systems are to be reliably safe in novel situations, they will need to incorporate general principles guiding them to robustly recognize which outcomes and behaviours would be harmful. Such principles may need to be supported by a binding system of regulation, which would need the underlying principles to be widely accepted. They should also be specific enough for technical implementation. Drawing inspiration from law, this article explains how negative human rights could fulfil the role of such principles and serve as a foundation both for an international regulatory system and for building technical safety constraints for future AI systems.
Planning for Goal-Oriented Dialogue Systems
Oct 17, 2019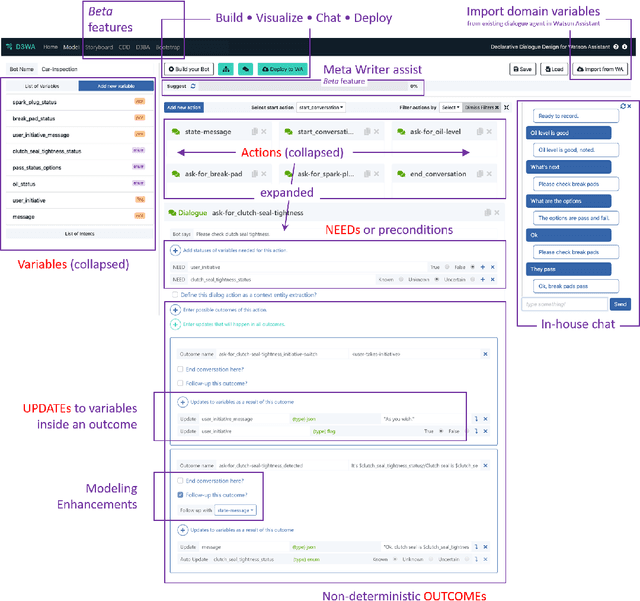
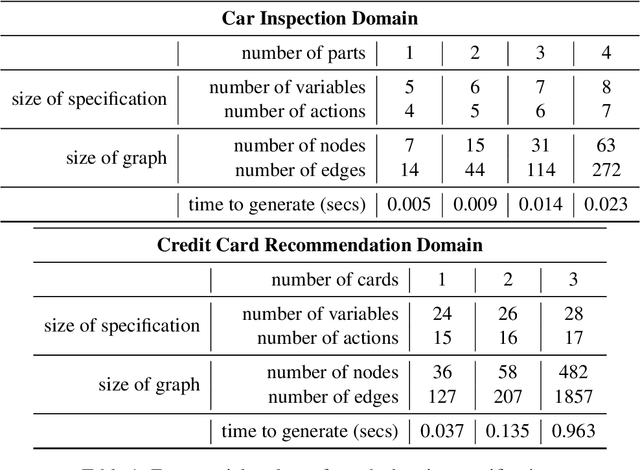
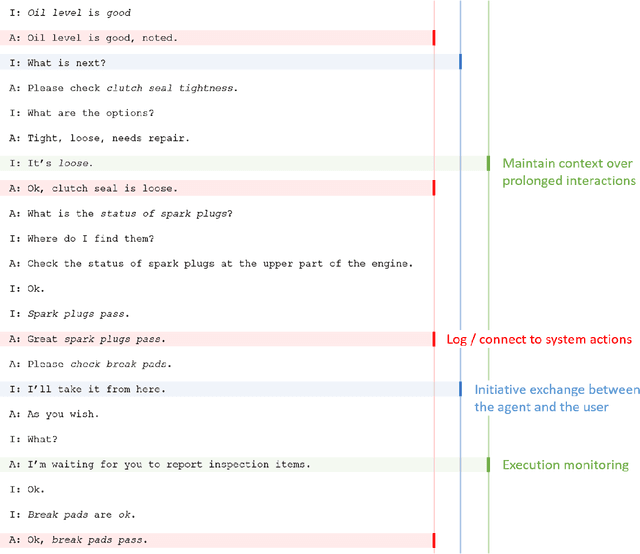
Generating complex multi-turn goal-oriented dialogue agents is a difficult problem that has seen a considerable focus from many leaders in the tech industry, including IBM, Google, Amazon, and Microsoft. This is in large part due to the rapidly growing market demand for dialogue agents capable of goal-oriented behaviour. Due to the business process nature of these conversations, end-to-end machine learning systems are generally not a viable option, as the generated dialogue agents must be deployable and verifiable on behalf of the businesses authoring them. In this work, we propose a paradigm shift in the creation of goal-oriented complex dialogue systems that dramatically eliminates the need for a designer to manually specify a dialogue tree, which nearly all current systems have to resort to when the interaction pattern falls outside standard patterns such as slot filling. We propose a declarative representation of the dialogue agent to be processed by state-of-the-art planning technology. Our proposed approach covers all aspects of the process; from model solicitation to the execution of the generated plans/dialogue agents. Along the way, we introduce novel planning encodings for declarative dialogue synthesis, a variety of interfaces for working with the specification as a dialogue architect, and a robust executor for generalized contingent plans. We have created prototype implementations of all components, and in this paper, we further demonstrate the resulting system empirically.
Generating Dialogue Agents via Automated Planning
Feb 02, 2019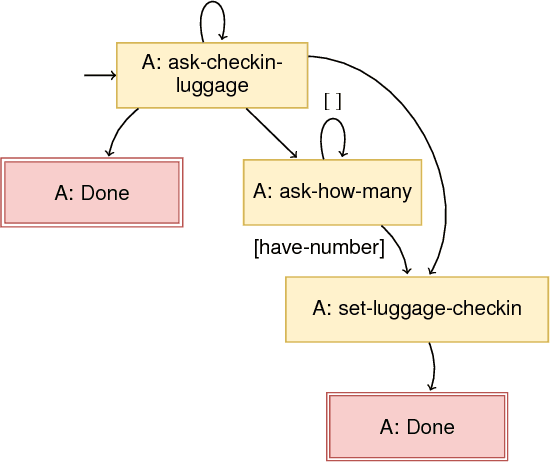
Dialogue systems have many applications such as customer support or question answering. Typically they have been limited to shallow single turn interactions. However more advanced applications such as career coaching or planning a trip require a much more complex multi-turn dialogue. Current limitations of conversational systems have made it difficult to support applications that require personalization, customization and context dependent interactions. We tackle this challenging problem by using domain-independent AI planning to automatically create dialogue plans, customized to guide a dialogue towards achieving a given goal. The input includes a library of atomic dialogue actions, an initial state of the dialogue, and a goal. Dialogue plans are plugged into a dialogue system capable to orchestrate their execution. Use cases demonstrate the viability of the approach. Our work on dialogue planning has been integrated into a product, and it is in the process of being deployed into another.
A Boo(n) for Evaluating Architecture Performance
Jul 23, 2018

We point out important problems with the common practice of using the best single model performance for comparing deep learning architectures, and we propose a method that corrects these flaws. Each time a model is trained, one gets a different result due to random factors in the training process, which include random parameter initialization and random data shuffling. Reporting the best single model performance does not appropriately address this stochasticity. We propose a normalized expected best-out-of-$n$ performance ($\text{Boo}_n$) as a way to correct these problems.
* ICML 2018
Knowledge Base Completion: Baselines Strike Back
May 30, 2017
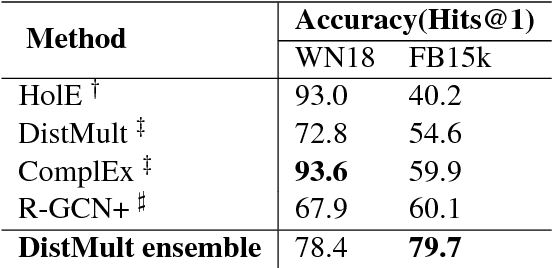
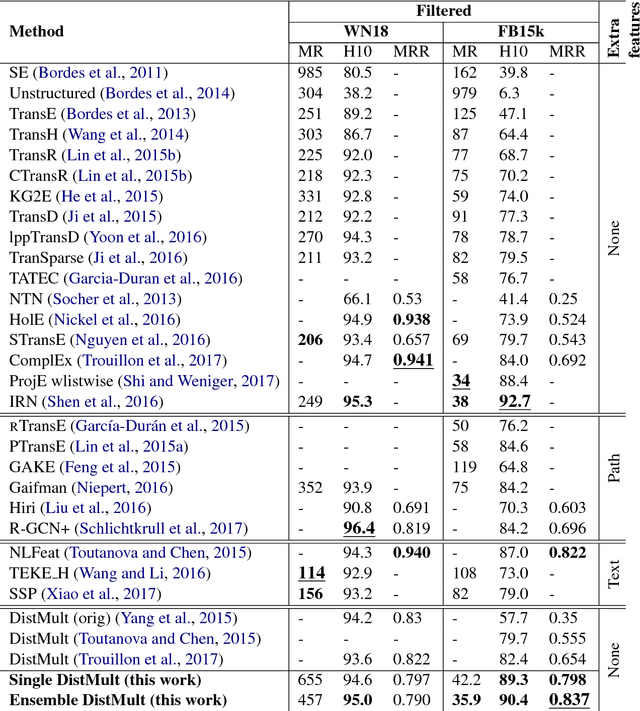
Many papers have been published on the knowledge base completion task in the past few years. Most of these introduce novel architectures for relation learning that are evaluated on standard datasets such as FB15k and WN18. This paper shows that the accuracy of almost all models published on the FB15k can be outperformed by an appropriately tuned baseline - our reimplementation of the DistMult model. Our findings cast doubt on the claim that the performance improvements of recent models are due to architectural changes as opposed to hyper-parameter tuning or different training objectives. This should prompt future research to re-consider how the performance of models is evaluated and reported.
Embracing data abundance: BookTest Dataset for Reading Comprehension
Oct 04, 2016
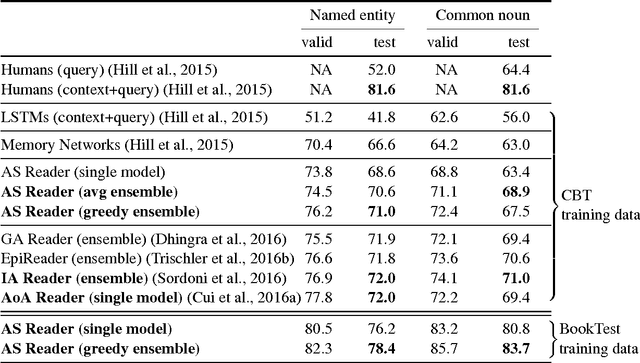

There is a practically unlimited amount of natural language data available. Still, recent work in text comprehension has focused on datasets which are small relative to current computing possibilities. This article is making a case for the community to move to larger data and as a step in that direction it is proposing the BookTest, a new dataset similar to the popular Children's Book Test (CBT), however more than 60 times larger. We show that training on the new data improves the accuracy of our Attention-Sum Reader model on the original CBT test data by a much larger margin than many recent attempts to improve the model architecture. On one version of the dataset our ensemble even exceeds the human baseline provided by Facebook. We then show in our own human study that there is still space for further improvement.
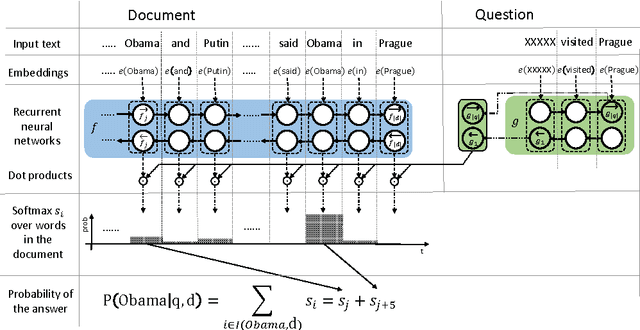
Text Understanding with the Attention Sum Reader Network
Jun 24, 2016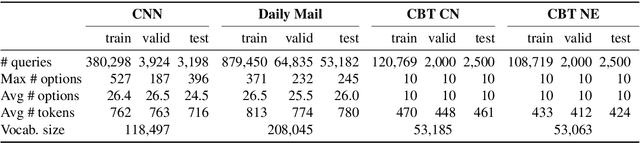
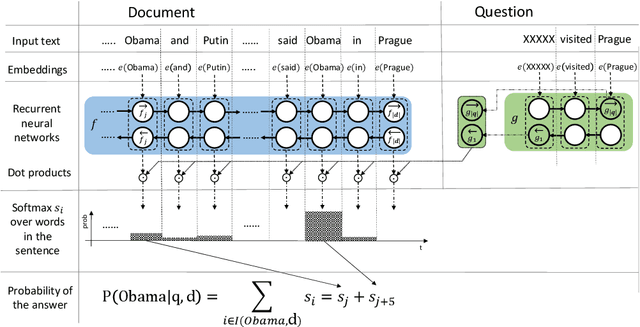
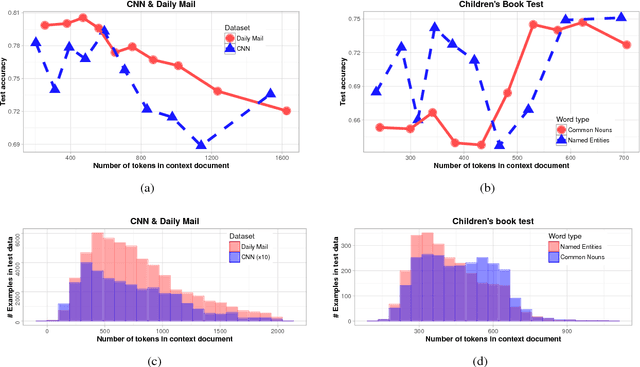
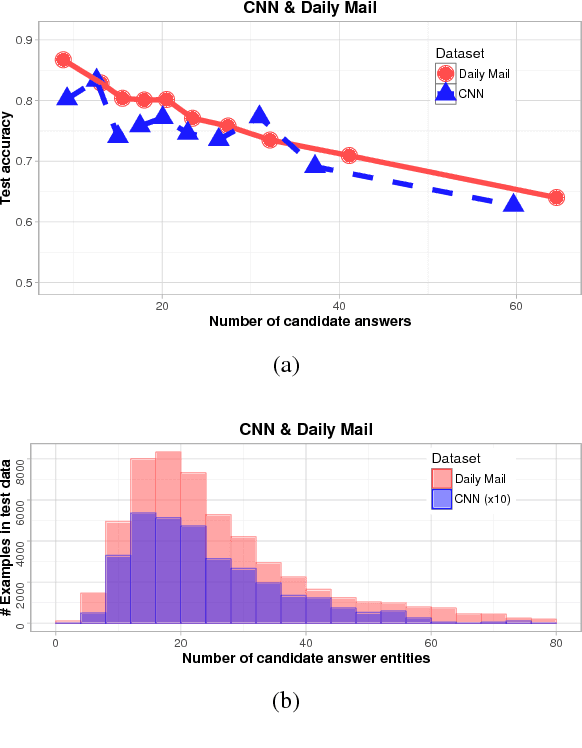
Several large cloze-style context-question-answer datasets have been introduced recently: the CNN and Daily Mail news data and the Children's Book Test. Thanks to the size of these datasets, the associated text comprehension task is well suited for deep-learning techniques that currently seem to outperform all alternative approaches. We present a new, simple model that uses attention to directly pick the answer from the context as opposed to computing the answer using a blended representation of words in the document as is usual in similar models. This makes the model particularly suitable for question-answering problems where the answer is a single word from the document. Ensemble of our models sets new state of the art on all evaluated datasets.