 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
Jan 16, 2026Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.
Shapelets-Enriched Selective Forecasting using Time Series Foundation Models
Jan 16, 2026Time series foundation models have recently gained a lot of attention due to their ability to model complex time series data encompassing different domains including traffic, energy, and weather. Although they exhibit strong average zero-shot performance on forecasting tasks, their predictions on certain critical regions of the data are not always reliable, limiting their usability in real-world applications, especially when data exhibits unique trends. In this paper, we propose a selective forecasting framework to identify these critical segments of time series using shapelets. We learn shapelets using shift-invariant dictionary learning on the validation split of the target domain dataset. Utilizing distance-based similarity to these shapelets, we facilitate the user to selectively discard unreliable predictions and be informed of the model's realistic capabilities. Empirical results on diverse benchmark time series datasets demonstrate that our approach leveraging both zero-shot and full-shot fine-tuned models reduces the overall error by an average of 22.17% for zero-shot and 22.62% for full-shot fine-tuned model. Furthermore, our approach using zero-shot and full-shot fine-tuned models, also outperforms its random selection counterparts by up to 21.41% and 21.43% on one of the datasets.
Localizing Persona Representations in LLMs
May 30, 2025We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.
Humble AI in the real-world: the case of algorithmic hiring
May 27, 2025Humble AI (Knowles et al., 2023) argues for cautiousness in AI development and deployments through scepticism (accounting for limitations of statistical learning), curiosity (accounting for unexpected outcomes), and commitment (accounting for multifaceted values beyond performance). We present a real-world case study for humble AI in the domain of algorithmic hiring. Specifically, we evaluate virtual screening algorithms in a widely used hiring platform that matches candidates to job openings. There are several challenges in misrecognition and stereotyping in such contexts that are difficult to assess through standard fairness and trust frameworks; e.g., someone with a non-traditional background is less likely to rank highly. We demonstrate technical feasibility of how humble AI principles can be translated to practice through uncertainty quantification of ranks, entropy estimates, and a user experience that highlights algorithmic unknowns. We describe preliminary discussions with focus groups made up of recruiters. Future user studies seek to evaluate whether the higher cognitive load of a humble AI system fosters a climate of trust in its outcomes.
FactReasoner: A Probabilistic Approach to Long-Form Factuality Assessment for Large Language Models
Feb 25, 2025


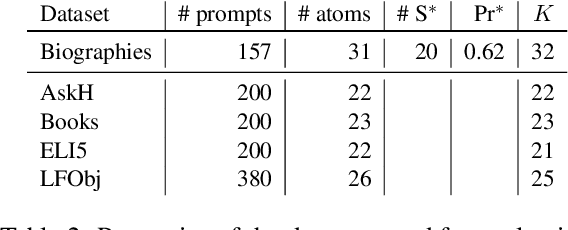
Large language models (LLMs) have demonstrated vast capabilities on generative tasks in recent years, yet they struggle with guaranteeing the factual correctness of the generated content. This makes these models unreliable in realistic situations where factually accurate responses are expected. In this paper, we propose FactReasoner, a new factuality assessor that relies on probabilistic reasoning to assess the factuality of a long-form generated response. Specifically, FactReasoner decomposes the response into atomic units, retrieves relevant contexts for them from an external knowledge source, and constructs a joint probability distribution over the atoms and contexts using probabilistic encodings of the logical relationships (entailment, contradiction) between the textual utterances corresponding to the atoms and contexts. FactReasoner then computes the posterior probability of whether atomic units in the response are supported by the retrieved contexts. Our experiments on labeled and unlabeled benchmark datasets demonstrate clearly that FactReasoner improves considerably over state-of-the-art prompt-based approaches in terms of both factual precision and recall.
BenchmarkCards: Large Language Model and Risk Reporting
Oct 16, 2024
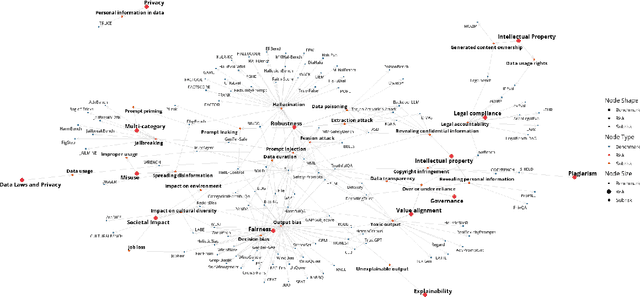

Large language models (LLMs) offer powerful capabilities but also introduce significant risks. One way to mitigate these risks is through comprehensive pre-deployment evaluations using benchmarks designed to test for specific vulnerabilities. However, the rapidly expanding body of LLM benchmark literature lacks a standardized method for documenting crucial benchmark details, hindering consistent use and informed selection. BenchmarkCards addresses this gap by providing a structured framework specifically for documenting LLM benchmark properties rather than defining the entire evaluation process itself. BenchmarkCards do not prescribe how to measure or interpret benchmark results (e.g., defining ``correctness'') but instead offer a standardized way to capture and report critical characteristics like targeted risks and evaluation methodologies, including properties such as bias and fairness. This structured metadata facilitates informed benchmark selection, enabling researchers to choose appropriate benchmarks and promoting transparency and reproducibility in LLM evaluation.
WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia
Jun 19, 2024
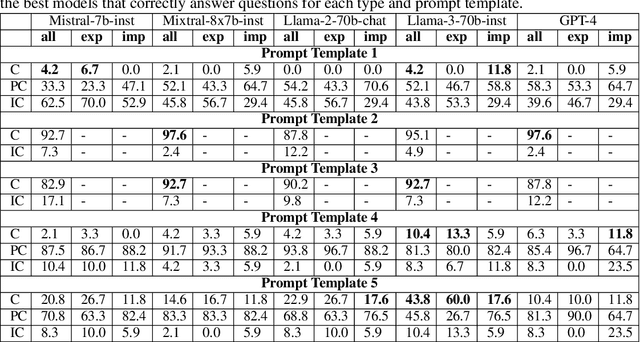
Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models struggle to generate answers that accurately reflect the conflicting nature of the context, especially for implicit conflicts requiring reasoning. Since human evaluation is costly, we also introduce an automated model that estimates LLM performance using a strong open-source language model, achieving an F-score of 0.8. Using this automated metric, we evaluate more than 1,500 answers from seven LLMs across all WikiContradict instances. To facilitate future work, we release WikiContradict on: https://ibm.biz/wikicontradict.
Ranking Large Language Models without Ground Truth
Feb 21, 2024



Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Explaining Knock-on Effects of Bias Mitigation
Dec 01, 2023In machine learning systems, bias mitigation approaches aim to make outcomes fairer across privileged and unprivileged groups. Bias mitigation methods work in different ways and have known "waterfall" effects, e.g., mitigating bias at one place may manifest bias elsewhere. In this paper, we aim to characterise impacted cohorts when mitigation interventions are applied. To do so, we treat intervention effects as a classification task and learn an explainable meta-classifier to identify cohorts that have altered outcomes. We examine a range of bias mitigation strategies that work at various stages of the model life cycle. We empirically demonstrate that our meta-classifier is able to uncover impacted cohorts. Further, we show that all tested mitigation strategies negatively impact a non-trivial fraction of cases, i.e., people who receive unfavourable outcomes solely on account of mitigation efforts. This is despite improvement in fairness metrics. We use these results as a basis to argue for more careful audits of static mitigation interventions that go beyond aggregate metrics.
Iterative Reward Shaping using Human Feedback for Correcting Reward Misspecification
Aug 30, 2023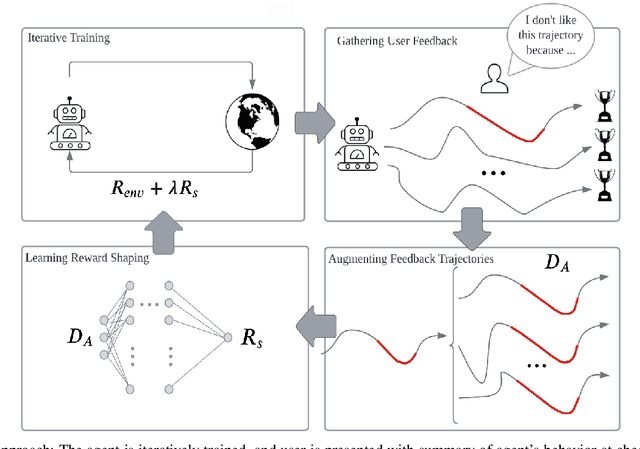

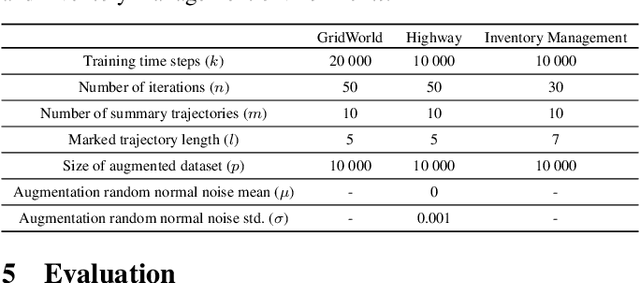
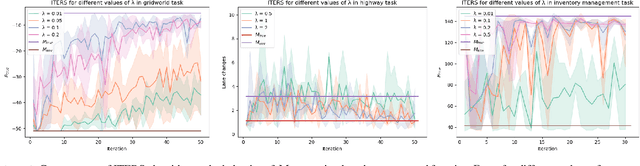
A well-defined reward function is crucial for successful training of an reinforcement learning (RL) agent. However, defining a suitable reward function is a notoriously challenging task, especially in complex, multi-objective environments. Developers often have to resort to starting with an initial, potentially misspecified reward function, and iteratively adjusting its parameters, based on observed learned behavior. In this work, we aim to automate this process by proposing ITERS, an iterative reward shaping approach using human feedback for mitigating the effects of a misspecified reward function. Our approach allows the user to provide trajectory-level feedback on agent's behavior during training, which can be integrated as a reward shaping signal in the following training iteration. We also allow the user to provide explanations of their feedback, which are used to augment the feedback and reduce user effort and feedback frequency. We evaluate ITERS in three environments and show that it can successfully correct misspecified reward functions.