 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Explanations in Interactive Machine Learning: An Overview
Jul 29, 2022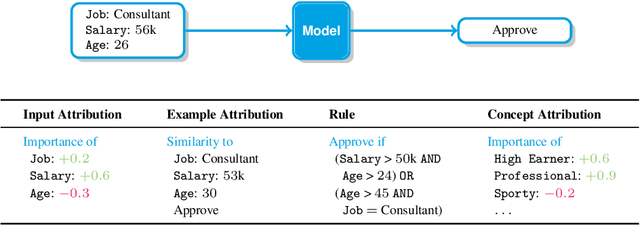
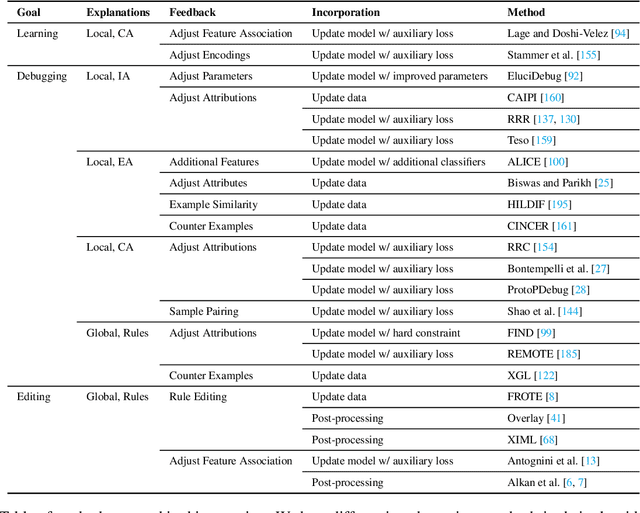
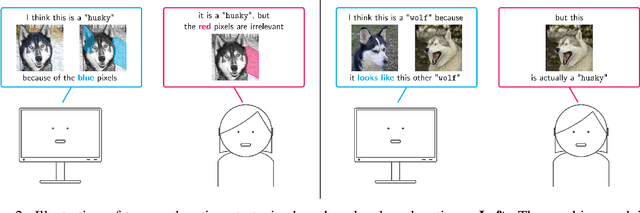

Explanations have gained an increasing level of interest in the AI and Machine Learning (ML) communities in order to improve model transparency and allow users to form a mental model of a trained ML model. However, explanations can go beyond this one way communication as a mechanism to elicit user control, because once users understand, they can then provide feedback. The goal of this paper is to present an overview of research where explanations are combined with interactive capabilities as a mean to learn new models from scratch and to edit and debug existing ones. To this end, we draw a conceptual map of the state-of-the-art, grouping relevant approaches based on their intended purpose and on how they structure the interaction, highlighting similarities and differences between them. We also discuss open research issues and outline possible directions forward, with the hope of spurring further research on this blooming research topic.
User Driven Model Adjustment via Boolean Rule Explanations
Mar 28, 2022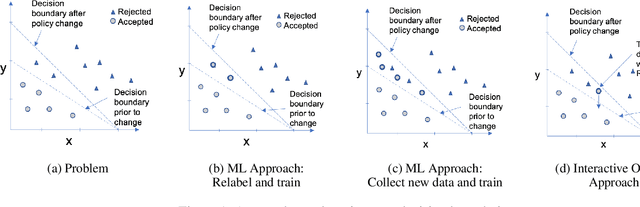

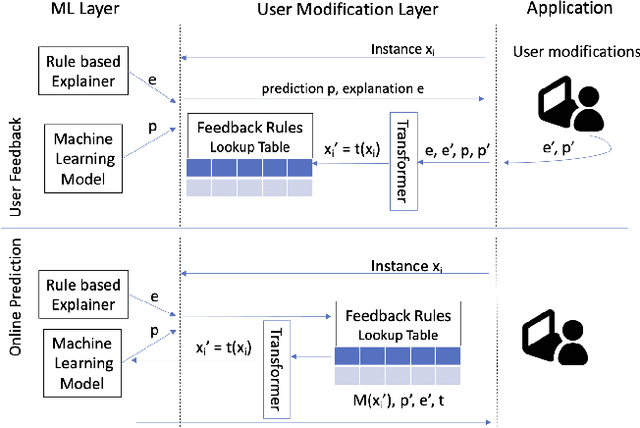

AI solutions are heavily dependant on the quality and accuracy of the input training data, however the training data may not always fully reflect the most up-to-date policy landscape or may be missing business logic. The advances in explainability have opened the possibility of allowing users to interact with interpretable explanations of ML predictions in order to inject modifications or constraints that more accurately reflect current realities of the system. In this paper, we present a solution which leverages the predictive power of ML models while allowing the user to specify modifications to decision boundaries. Our interactive overlay approach achieves this goal without requiring model retraining, making it appropriate for systems that need to apply instant changes to their decision making. We demonstrate that user feedback rules can be layered with the ML predictions to provide immediate changes which in turn supports learning with less data.
FROTE: Feedback Rule-Driven Oversampling for Editing Models
Jan 06, 2022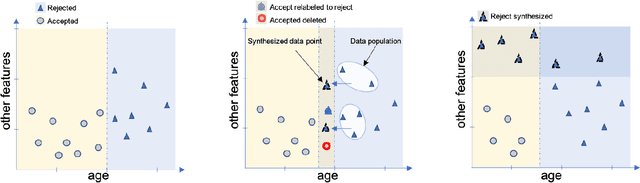
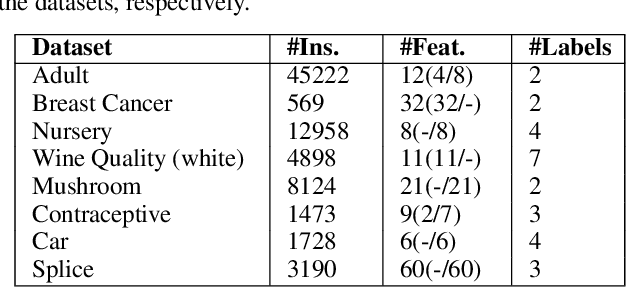
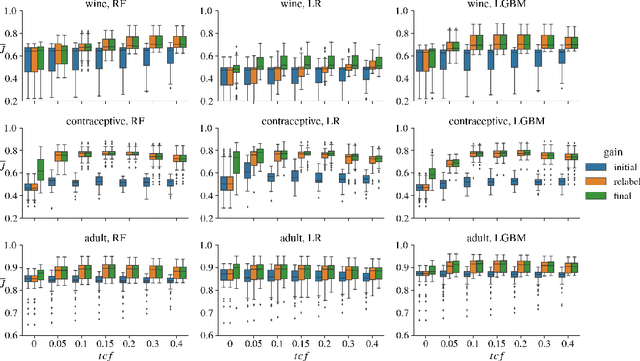
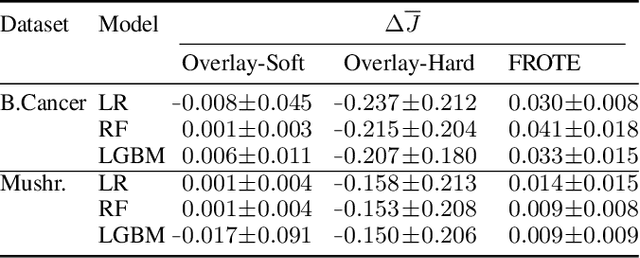
Machine learning models may involve decision boundaries that change over time due to updates to rules and regulations, such as in loan approvals or claims management. However, in such scenarios, it may take time for sufficient training data to accumulate in order to retrain the model to reflect the new decision boundaries. While work has been done to reinforce existing decision boundaries, very little has been done to cover these scenarios where decision boundaries of the ML models should change in order to reflect new rules. In this paper, we focus on user-provided feedback rules as a way to expedite the ML models update process, and we formally introduce the problem of pre-processing training data to edit an ML model in response to feedback rules such that once the model is retrained on the pre-processed data, its decision boundaries align more closely with the rules. To solve this problem, we propose a novel data augmentation method, the Feedback Rule-Based Oversampling Technique. Extensive experiments using different ML models and real world datasets demonstrate the effectiveness of the method, in particular the benefit of augmentation and the ability to handle many feedback rules.