 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Reward Shaping using Human Feedback for Correcting Reward Misspecification
Aug 30, 2023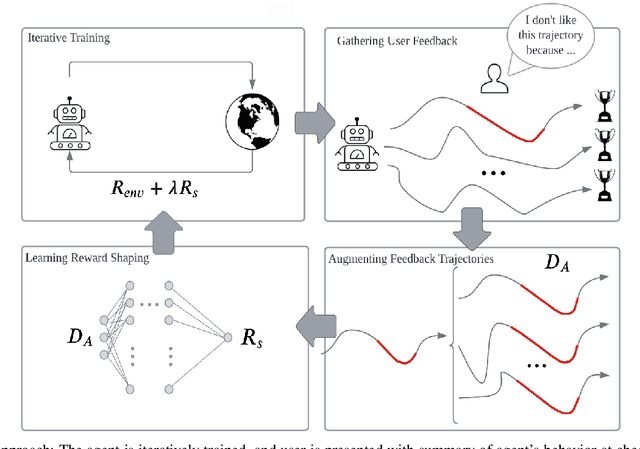

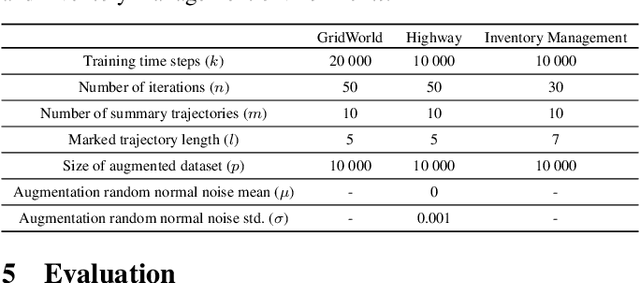
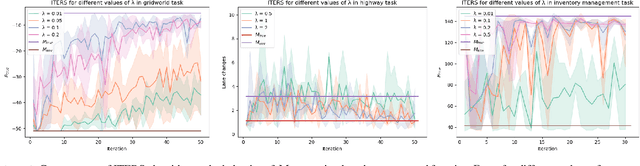
A well-defined reward function is crucial for successful training of an reinforcement learning (RL) agent. However, defining a suitable reward function is a notoriously challenging task, especially in complex, multi-objective environments. Developers often have to resort to starting with an initial, potentially misspecified reward function, and iteratively adjusting its parameters, based on observed learned behavior. In this work, we aim to automate this process by proposing ITERS, an iterative reward shaping approach using human feedback for mitigating the effects of a misspecified reward function. Our approach allows the user to provide trajectory-level feedback on agent's behavior during training, which can be integrated as a reward shaping signal in the following training iteration. We also allow the user to provide explanations of their feedback, which are used to augment the feedback and reduce user effort and feedback frequency. We evaluate ITERS in three environments and show that it can successfully correct misspecified reward functions.
Boolean Decision Rules for Reinforcement Learning Policy Summarisation
Jul 18, 2022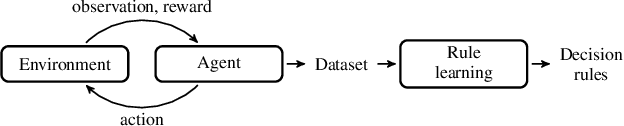

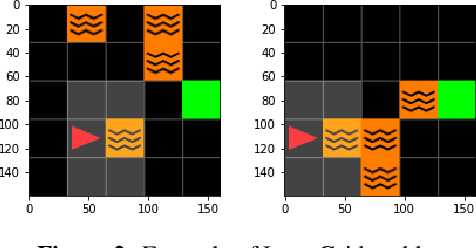
Explainability of Reinforcement Learning (RL) policies remains a challenging research problem, particularly when considering RL in a safety context. Understanding the decisions and intentions of an RL policy offer avenues to incorporate safety into the policy by limiting undesirable actions. We propose the use of a Boolean Decision Rules model to create a post-hoc rule-based summary of an agent's policy. We evaluate our proposed approach using a DQN agent trained on an implementation of a lava gridworld and show that, given a hand-crafted feature representation of this gridworld, simple generalised rules can be created, giving a post-hoc explainable summary of the agent's policy. We discuss possible avenues to introduce safety into a RL agent's policy by using rules generated by this rule-based model as constraints imposed on the agent's policy, as well as discuss how creating simple rule summaries of an agent's policy may help in the debugging process of RL agents.