 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Trajectory Explanations for Multi-Objective Reinforcement Learning
Mar 23, 2026Reinforcement Learning (RL) has demonstrated its ability to solve complex decision-making problems in a variety of domains, by optimizing reward signals obtained through interaction with an environment. However, many real-world scenarios involve multiple, potentially conflicting objectives that cannot be easily represented by a single scalar reward. Multi-Objective Reinforcement Learning (MORL) addresses this limitation by enabling agents to optimize several objectives simultaneously, explicitly reasoning about trade-offs between them. However, the ``black box" nature of the RL models makes the decision process behind chosen objective trade-offs unclear. Current Explainable Reinforcement Learning (XRL) methods are typically designed for single scalar rewards and do not account for explanations with respect to distinct objectives or user preferences. To address this gap, in this paper we propose TREX, a Trajectory based Explainability framework to explain Multi-objective Reinforcement Learning policies, based on trajectory attribution. TREX generates trajectories directly from the learned expert policy, across different user preferences and clusters them into semantically meaningful temporal segments. We quantify the influence of these behavioural segments on the Pareto trade-off by training complementary policies that exclude specific clusters, measuring the resulting relative deviation on the observed rewards and actions compared to the original expert policy. Experiments on multi-objective MuJoCo environments - HalfCheetah, Ant and Swimmer, demonstrate the framework's ability to isolate and quantify the specific behavioural patterns.
Balancing Multiple Objectives in Urban Traffic Control with Reinforcement Learning from AI Feedback
Feb 24, 2026Reward design has been one of the central challenges for real world reinforcement learning (RL) deployment, especially in settings with multiple objectives. Preference-based RL offers an appealing alternative by learning from human preferences over pairs of behavioural outcomes. More recently, RL from AI feedback (RLAIF) has demonstrated that large language models (LLMs) can generate preference labels at scale, mitigating the reliance on human annotators. However, existing RLAIF work typically focuses only on single-objective tasks, leaving the open question of how RLAIF handles systems that involve multiple objectives. In such systems trade-offs among conflicting objectives are difficult to specify, and policies risk collapsing into optimizing for a dominant goal. In this paper, we explore the extension of the RLAIF paradigm to multi-objective self-adaptive systems. We show that multi-objective RLAIF can produce policies that yield balanced trade-offs reflecting different user priorities without laborious reward engineering. We argue that integrating RLAIF into multi-objective RL offers a scalable path toward user-aligned policy learning in domains with inherently conflicting objectives.
Geographically-aware Transformer-based Traffic Forecasting for Urban Motorway Digital Twins
Feb 05, 2026The operational effectiveness of digital-twin technology in motorway traffic management depends on the availability of a continuous flow of high-resolution real-time traffic data. To function as a proactive decision-making support layer within traffic management, a digital twin must also incorporate predicted traffic conditions in addition to real-time observations. Due to the spatio-temporal complexity and the time-variant, non-linear nature of traffic dynamics, predicting motorway traffic remains a difficult problem. Sequence-based deep-learning models offer clear advantages over classical machine learning and statistical models in capturing long-range, temporal dependencies in time-series traffic data, yet limitations in forecasting accuracy and model complexity point to the need for further improvements. To improve motorway traffic forecasting, this paper introduces a Geographically-aware Transformer-based Traffic Forecasting GATTF model, which exploits the geographical relationships between distributed sensors using their mutual information (MI). The model has been evaluated using real-time data from the Geneva motorway network in Switzerland and results confirm that incorporating geographical awareness through MI enhances the accuracy of GATTF forecasting compared to a standard Transformer, without increasing model complexity.
Adapting the Behavior of Reinforcement Learning Agents to Changing Action Spaces and Reward Functions
Jan 28, 2026Reinforcement Learning (RL) agents often struggle in real-world applications where environmental conditions are non-stationary, particularly when reward functions shift or the available action space expands. This paper introduces MORPHIN, a self-adaptive Q-learning framework that enables on-the-fly adaptation without full retraining. By integrating concept drift detection with dynamic adjustments to learning and exploration hyperparameters, MORPHIN adapts agents to changes in both the reward function and on-the-fly expansions of the agent's action space, while preserving prior policy knowledge to prevent catastrophic forgetting. We validate our approach using a Gridworld benchmark and a traffic signal control simulation. The results demonstrate that MORPHIN achieves superior convergence speed and continuous adaptation compared to a standard Q-learning baseline, improving learning efficiency by up to 1.7x.
Shapelets-Enriched Selective Forecasting using Time Series Foundation Models
Jan 16, 2026Time series foundation models have recently gained a lot of attention due to their ability to model complex time series data encompassing different domains including traffic, energy, and weather. Although they exhibit strong average zero-shot performance on forecasting tasks, their predictions on certain critical regions of the data are not always reliable, limiting their usability in real-world applications, especially when data exhibits unique trends. In this paper, we propose a selective forecasting framework to identify these critical segments of time series using shapelets. We learn shapelets using shift-invariant dictionary learning on the validation split of the target domain dataset. Utilizing distance-based similarity to these shapelets, we facilitate the user to selectively discard unreliable predictions and be informed of the model's realistic capabilities. Empirical results on diverse benchmark time series datasets demonstrate that our approach leveraging both zero-shot and full-shot fine-tuned models reduces the overall error by an average of 22.17% for zero-shot and 22.62% for full-shot fine-tuned model. Furthermore, our approach using zero-shot and full-shot fine-tuned models, also outperforms its random selection counterparts by up to 21.41% and 21.43% on one of the datasets.
Continual Reinforcement Learning for Cyber-Physical Systems: Lessons Learned and Open Challenges
Nov 19, 2025
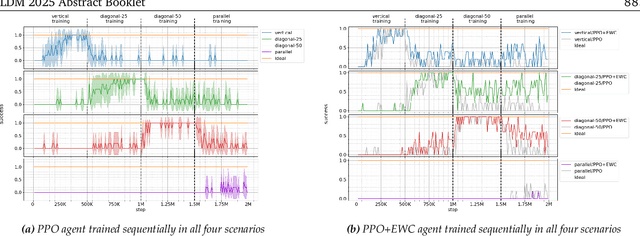
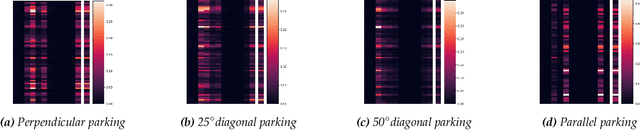
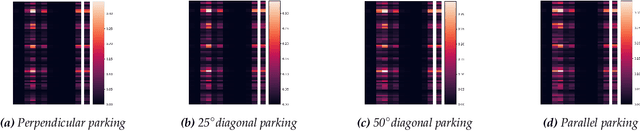
Continual learning (CL) is a branch of machine learning that aims to enable agents to adapt and generalise previously learned abilities so that these can be reapplied to new tasks or environments. This is particularly useful in multi-task settings or in non-stationary environments, where the dynamics can change over time. This is particularly relevant in cyber-physical systems such as autonomous driving. However, despite recent advances in CL, successfully applying it to reinforcement learning (RL) is still an open problem. This paper highlights open challenges in continual RL (CRL) based on experiments in an autonomous driving environment. In this environment, the agent must learn to successfully park in four different scenarios corresponding to parking spaces oriented at varying angles. The agent is successively trained in these four scenarios one after another, representing a CL environment, using Proximal Policy Optimisation (PPO). These experiments exposed a number of open challenges in CRL: finding suitable abstractions of the environment, oversensitivity to hyperparameters, catastrophic forgetting, and efficient use of neural network capacity. Based on these identified challenges, we present open research questions that are important to be addressed for creating robust CRL systems. In addition, the identified challenges call into question the suitability of neural networks for CL. We also identify the need for interdisciplinary research, in particular between computer science and neuroscience.
Applying Neural Monte Carlo Tree Search to Unsignalized Multi-intersection Scheduling for Autonomous Vehicles
Oct 24, 2024



Dynamic scheduling of access to shared resources by autonomous systems is a challenging problem, characterized as being NP-hard. The complexity of this task leads to a combinatorial explosion of possibilities in highly dynamic systems where arriving requests must be continuously scheduled subject to strong safety and time constraints. An example of such a system is an unsignalized intersection, where automated vehicles' access to potential conflict zones must be dynamically scheduled. In this paper, we apply Neural Monte Carlo Tree Search (NMCTS) to the challenging task of scheduling platoons of vehicles crossing unsignalized intersections. Crucially, we introduce a transformation model that maps successive sequences of potentially conflicting road-space reservation requests from platoons of vehicles into a series of board-game-like problems and use NMCTS to search for solutions representing optimal road-space allocation schedules in the context of past allocations. To optimize search, we incorporate a prioritized re-sampling method with parallel NMCTS (PNMCTS) to improve the quality of training data. To optimize training, a curriculum learning strategy is used to train the agent to schedule progressively more complex boards culminating in overlapping boards that represent busy intersections. In a busy single four-way unsignalized intersection simulation, PNMCTS solved 95\% of unseen scenarios, reducing crossing time by 43\% in light and 52\% in heavy traffic versus first-in, first-out control. In a 3x3 multi-intersection network, the proposed method maintained free-flow in light traffic when all intersections are under control of PNMCTS and outperformed state-of-the-art RL-based traffic-light controllers in average travel time by 74.5\% and total throughput by 16\% in heavy traffic.
Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient
Oct 11, 2024



Model-based reinforcement learning (RL) offers a solution to the data inefficiency that plagues most model-free RL algorithms. However, learning a robust world model often demands complex and deep architectures, which are expensive to compute and train. Within the world model, dynamics models are particularly crucial for accurate predictions, and various dynamics-model architectures have been explored, each with its own set of challenges. Currently, recurrent neural network (RNN) based world models face issues such as vanishing gradients and difficulty in capturing long-term dependencies effectively. In contrast, use of transformers suffers from the well-known issues of self-attention mechanisms, where both memory and computational complexity scale as $O(n^2)$, with $n$ representing the sequence length. To address these challenges we propose a state space model (SSM) based world model, specifically based on Mamba, that achieves $O(n)$ memory and computational complexity while effectively capturing long-term dependencies and facilitating the use of longer training sequences efficiently. We also introduce a novel sampling method to mitigate the suboptimality caused by an incorrect world model in the early stages of training, combining it with the aforementioned technique to achieve a normalised score comparable to other state-of-the-art model-based RL algorithms using only a 7 million trainable parameter world model. This model is accessible and can be trained on an off-the-shelf laptop. Our code is available at https://github.com/realwenlongwang/drama.git.
Semifactual Explanations for Reinforcement Learning
Sep 09, 2024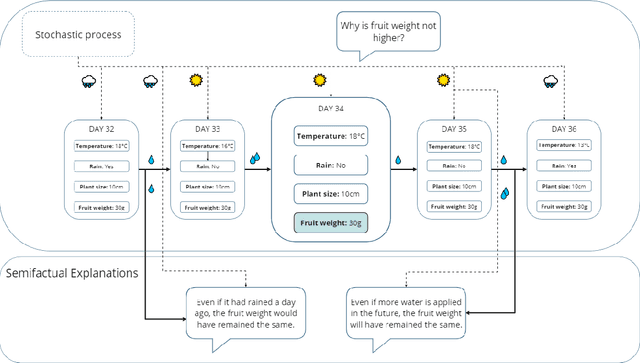
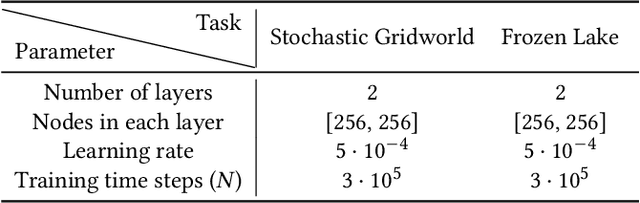
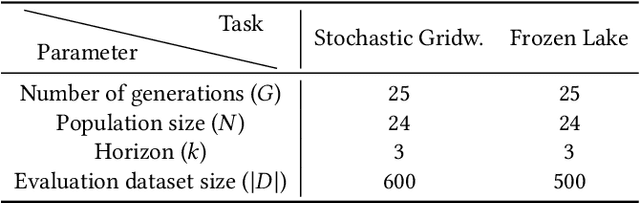
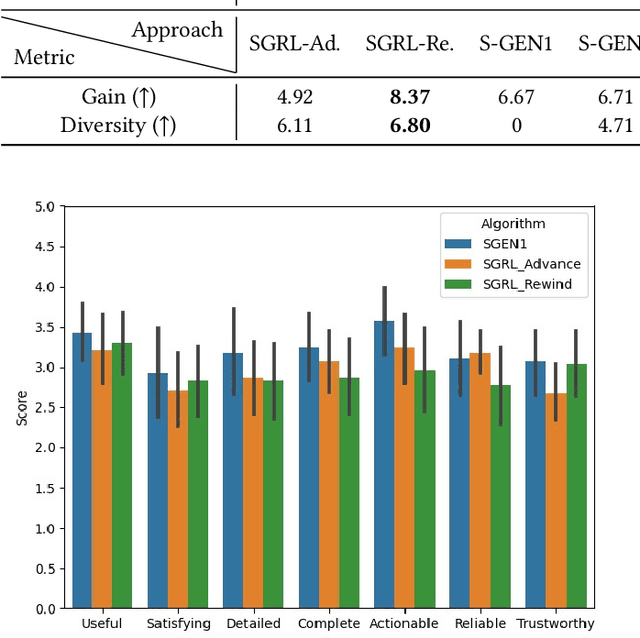
Reinforcement Learning (RL) is a learning paradigm in which the agent learns from its environment through trial and error. Deep reinforcement learning (DRL) algorithms represent the agent's policies using neural networks, making their decisions difficult to interpret. Explaining the behaviour of DRL agents is necessary to advance user trust, increase engagement, and facilitate integration with real-life tasks. Semifactual explanations aim to explain an outcome by providing "even if" scenarios, such as "even if the car were moving twice as slowly, it would still have to swerve to avoid crashing". Semifactuals help users understand the effects of different factors on the outcome and support the optimisation of resources. While extensively studied in psychology and even utilised in supervised learning, semifactuals have not been used to explain the decisions of RL systems. In this work, we develop a first approach to generating semifactual explanations for RL agents. We start by defining five properties of desirable semifactual explanations in RL and then introducing SGRL-Rewind and SGRL-Advance, the first algorithms for generating semifactual explanations in RL. We evaluate the algorithms in two standard RL environments and find that they generate semifactuals that are easier to reach, represent the agent's policy better, and are more diverse compared to baselines. Lastly, we conduct and analyse a user study to assess the participant's perception of semifactual explanations of the agent's actions.
ACTER: Diverse and Actionable Counterfactual Sequences for Explaining and Diagnosing RL Policies
Feb 09, 2024Understanding how failure occurs and how it can be prevented in reinforcement learning (RL) is necessary to enable debugging, maintain user trust, and develop personalized policies. Counterfactual reasoning has often been used to assign blame and understand failure by searching for the closest possible world in which the failure is avoided. However, current counterfactual state explanations in RL can only explain an outcome using just the current state features and offer no actionable recourse on how a negative outcome could have been prevented. In this work, we propose ACTER (Actionable Counterfactual Sequences for Explaining Reinforcement Learning Outcomes), an algorithm for generating counterfactual sequences that provides actionable advice on how failure can be avoided. ACTER investigates actions leading to a failure and uses the evolutionary algorithm NSGA-II to generate counterfactual sequences of actions that prevent it with minimal changes and high certainty even in stochastic environments. Additionally, ACTER generates a set of multiple diverse counterfactual sequences that enable users to correct failure in the way that best fits their preferences. We also introduce three diversity metrics that can be used for evaluating the diversity of counterfactual sequences. We evaluate ACTER in two RL environments, with both discrete and continuous actions, and show that it can generate actionable and diverse counterfactual sequences. We conduct a user study to explore how explanations generated by ACTER help users identify and correct failure.