 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemifactual Explanations for Reinforcement Learning
Sep 09, 2024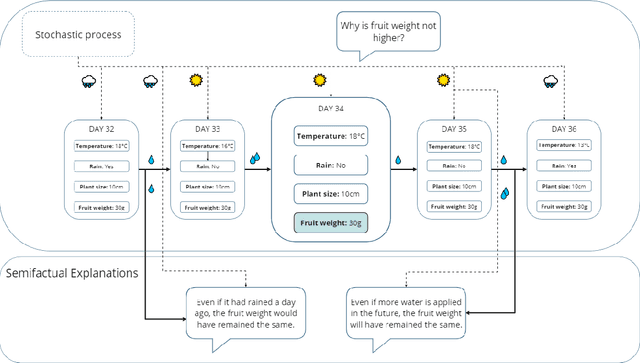
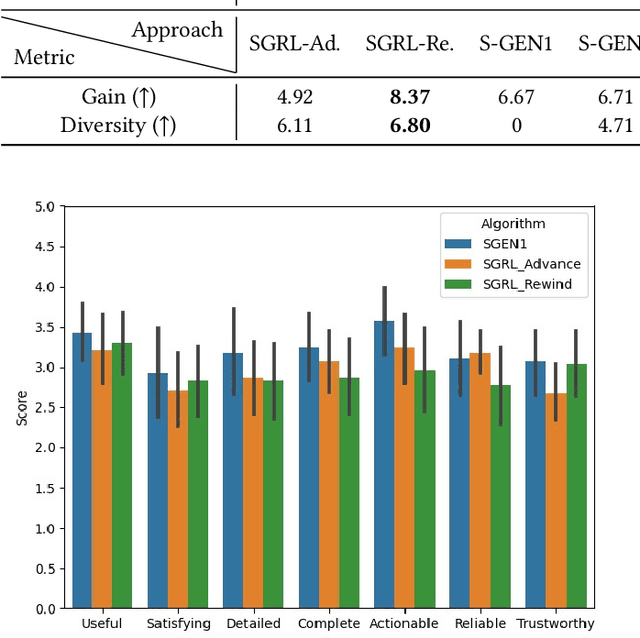
Reinforcement Learning (RL) is a learning paradigm in which the agent learns from its environment through trial and error. Deep reinforcement learning (DRL) algorithms represent the agent's policies using neural networks, making their decisions difficult to interpret. Explaining the behaviour of DRL agents is necessary to advance user trust, increase engagement, and facilitate integration with real-life tasks. Semifactual explanations aim to explain an outcome by providing "even if" scenarios, such as "even if the car were moving twice as slowly, it would still have to swerve to avoid crashing". Semifactuals help users understand the effects of different factors on the outcome and support the optimisation of resources. While extensively studied in psychology and even utilised in supervised learning, semifactuals have not been used to explain the decisions of RL systems. In this work, we develop a first approach to generating semifactual explanations for RL agents. We start by defining five properties of desirable semifactual explanations in RL and then introducing SGRL-Rewind and SGRL-Advance, the first algorithms for generating semifactual explanations in RL. We evaluate the algorithms in two standard RL environments and find that they generate semifactuals that are easier to reach, represent the agent's policy better, and are more diverse compared to baselines. Lastly, we conduct and analyse a user study to assess the participant's perception of semifactual explanations of the agent's actions.
Context-Based Tweet Engagement Prediction
Sep 28, 2023



Twitter is currently one of the biggest social media platforms. Its users may share, read, and engage with short posts called tweets. For the ACM Recommender Systems Conference 2020, Twitter published a dataset around 70 GB in size for the annual RecSys Challenge. In 2020, the RecSys Challenge invited participating teams to create models that would predict engagement likelihoods for given user-tweet combinations. The submitted models predicting like, reply, retweet, and quote engagements were evaluated based on two metrics: area under the precision-recall curve (PRAUC) and relative cross-entropy (RCE). In this diploma thesis, we used the RecSys 2020 Challenge dataset and evaluation procedure to investigate how well context alone may be used to predict tweet engagement likelihood. In doing so, we employed the Spark engine on TU Wien's Little Big Data Cluster to create scalable data preprocessing, feature engineering, feature selection, and machine learning pipelines. We manually created just under 200 additional features to describe tweet context. The results indicate that features describing users' prior engagement history and the popularity of hashtags and links in the tweet were the most informative. We also found that factors such as the prediction algorithm, training dataset size, training dataset sampling method, and feature selection significantly affect the results. After comparing the best results of our context-only prediction models with content-only models and with models developed by the Challenge winners, we identified that the context-based models underperformed in terms of the RCE score. This work thus concludes by situating this discrepancy and proposing potential improvements to our implementation, which is shared in a public git repository.
Semi-Abstract Value-Based Argumentation Framework
Sep 25, 2023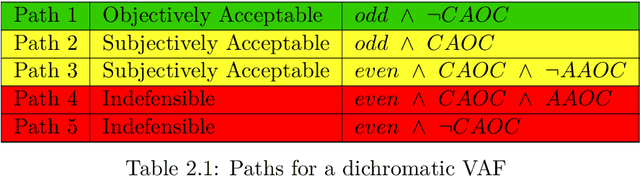
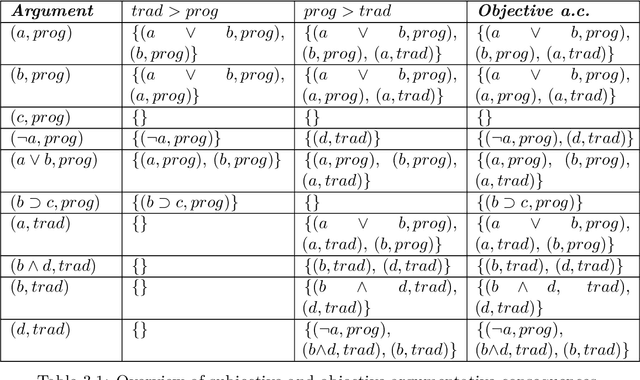
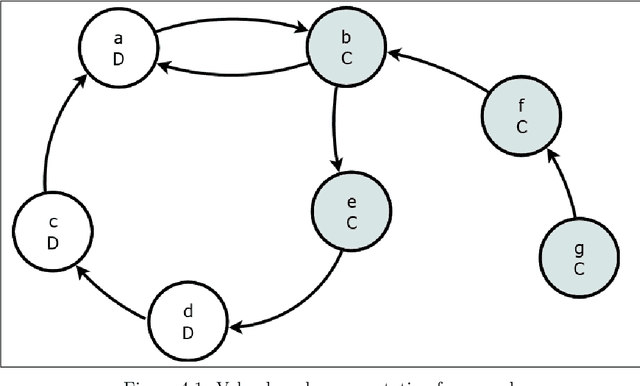

In his seminal paper, Phan Minh Dung (1995) proposed abstract argumentation framework, which models argumentation using directed graphs where structureless arguments are the nodes and attacks among the arguments are the edges. In the following years, many extensions of this framework were introduced. These extensions typically add a certain form of structure to the arguments. This thesis showcases two such extensions -- value-based argumentation framework by Trevor Bench-Capon (2002) and semi-abstract argumentation framework by Esther Anna Corsi and Christian Ferm\"uller (2017). The former introduces a mapping function that links individual arguments to a set of ordered values, enabling a distinction between objectively and subjectively acceptable arguments. The latter links claims of individual arguments to propositional formulae and then applies newly-introduced attack principles in order to make implicit attacks explicit and to enable a definition of a consequence relation that relies on neither the truth values nor the interpretations in the usual sense. The contribution of this thesis is two-fold. Firstly, the new semi-abstract value-based argumentation framework is introduced. This framework maps propositional formulae associated with individual arguments to a set of ordered values. Secondly, a complex moral dilemma is formulated using the original and the value-based argumentation frameworks showcasing the expressivity of these formalisms.