 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
Jan 16, 2026Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.
Generate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Semifactual Explanations for Reinforcement Learning
Sep 09, 2024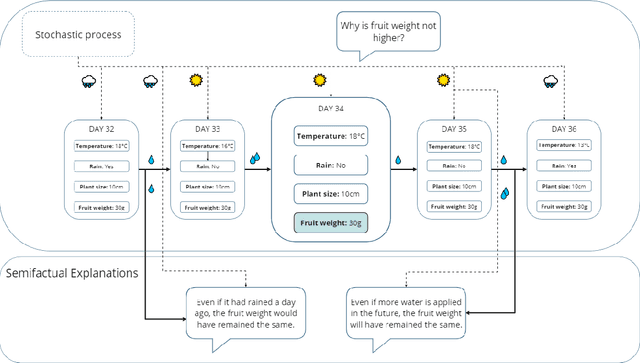
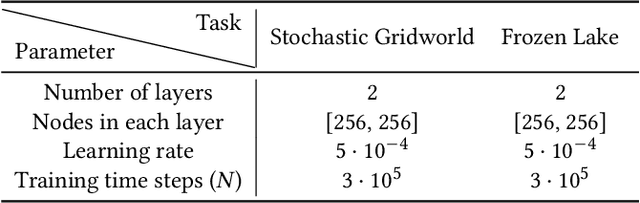
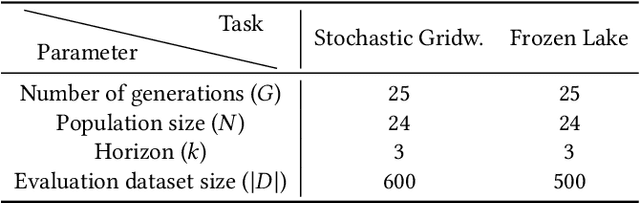
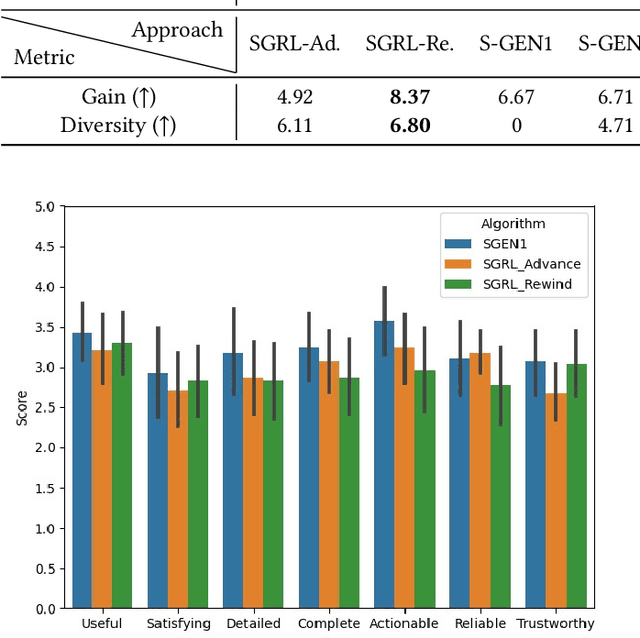
Reinforcement Learning (RL) is a learning paradigm in which the agent learns from its environment through trial and error. Deep reinforcement learning (DRL) algorithms represent the agent's policies using neural networks, making their decisions difficult to interpret. Explaining the behaviour of DRL agents is necessary to advance user trust, increase engagement, and facilitate integration with real-life tasks. Semifactual explanations aim to explain an outcome by providing "even if" scenarios, such as "even if the car were moving twice as slowly, it would still have to swerve to avoid crashing". Semifactuals help users understand the effects of different factors on the outcome and support the optimisation of resources. While extensively studied in psychology and even utilised in supervised learning, semifactuals have not been used to explain the decisions of RL systems. In this work, we develop a first approach to generating semifactual explanations for RL agents. We start by defining five properties of desirable semifactual explanations in RL and then introducing SGRL-Rewind and SGRL-Advance, the first algorithms for generating semifactual explanations in RL. We evaluate the algorithms in two standard RL environments and find that they generate semifactuals that are easier to reach, represent the agent's policy better, and are more diverse compared to baselines. Lastly, we conduct and analyse a user study to assess the participant's perception of semifactual explanations of the agent's actions.
ACTER: Diverse and Actionable Counterfactual Sequences for Explaining and Diagnosing RL Policies
Feb 09, 2024Understanding how failure occurs and how it can be prevented in reinforcement learning (RL) is necessary to enable debugging, maintain user trust, and develop personalized policies. Counterfactual reasoning has often been used to assign blame and understand failure by searching for the closest possible world in which the failure is avoided. However, current counterfactual state explanations in RL can only explain an outcome using just the current state features and offer no actionable recourse on how a negative outcome could have been prevented. In this work, we propose ACTER (Actionable Counterfactual Sequences for Explaining Reinforcement Learning Outcomes), an algorithm for generating counterfactual sequences that provides actionable advice on how failure can be avoided. ACTER investigates actions leading to a failure and uses the evolutionary algorithm NSGA-II to generate counterfactual sequences of actions that prevent it with minimal changes and high certainty even in stochastic environments. Additionally, ACTER generates a set of multiple diverse counterfactual sequences that enable users to correct failure in the way that best fits their preferences. We also introduce three diversity metrics that can be used for evaluating the diversity of counterfactual sequences. We evaluate ACTER in two RL environments, with both discrete and continuous actions, and show that it can generate actionable and diverse counterfactual sequences. We conduct a user study to explore how explanations generated by ACTER help users identify and correct failure.
Iterative Reward Shaping using Human Feedback for Correcting Reward Misspecification
Aug 30, 2023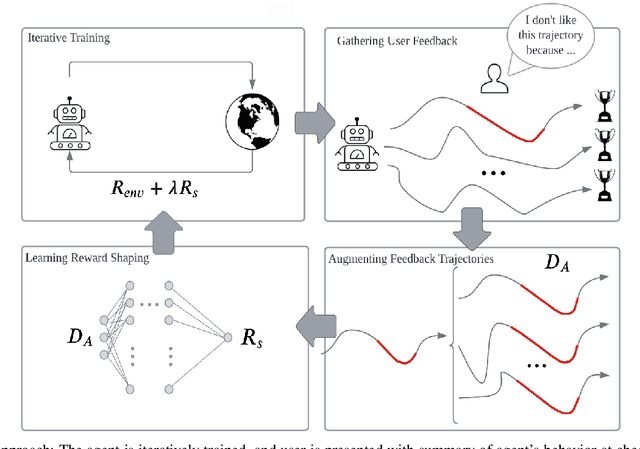

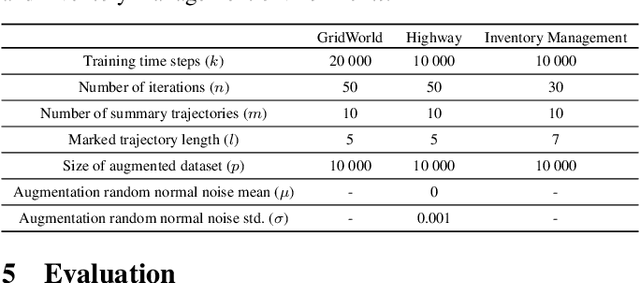
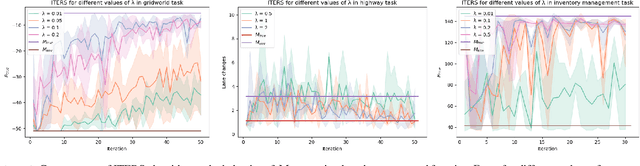
A well-defined reward function is crucial for successful training of an reinforcement learning (RL) agent. However, defining a suitable reward function is a notoriously challenging task, especially in complex, multi-objective environments. Developers often have to resort to starting with an initial, potentially misspecified reward function, and iteratively adjusting its parameters, based on observed learned behavior. In this work, we aim to automate this process by proposing ITERS, an iterative reward shaping approach using human feedback for mitigating the effects of a misspecified reward function. Our approach allows the user to provide trajectory-level feedback on agent's behavior during training, which can be integrated as a reward shaping signal in the following training iteration. We also allow the user to provide explanations of their feedback, which are used to augment the feedback and reduce user effort and feedback frequency. We evaluate ITERS in three environments and show that it can successfully correct misspecified reward functions.
RACCER: Towards Reachable and Certain Counterfactual Explanations for Reinforcement Learning
Mar 08, 2023While reinforcement learning (RL) algorithms have been successfully applied to numerous tasks, their reliance on neural networks makes their behavior difficult to understand and trust. Counterfactual explanations are human-friendly explanations that offer users actionable advice on how to alter the model inputs to achieve the desired output from a black-box system. However, current approaches to generating counterfactuals in RL ignore the stochastic and sequential nature of RL tasks and can produce counterfactuals which are difficult to obtain or do not deliver the desired outcome. In this work, we propose RACCER, the first RL-specific approach to generating counterfactual explanations for the behaviour of RL agents. We first propose and implement a set of RL-specific counterfactual properties that ensure easily reachable counterfactuals with highly-probable desired outcomes. We use a heuristic tree search of agent's execution trajectories to find the most suitable counterfactuals based on the defined properties. We evaluate RACCER in two tasks as well as conduct a user study to show that RL-specific counterfactuals help users better understand agent's behavior compared to the current state-of-the-art approaches.
Causal Counterfactuals for Improving the Robustness of Reinforcement Learning
Nov 02, 2022



Reinforcement learning (RL) is applied in a wide variety of fields. RL enables agents to learn tasks autonomously by interacting with the environment. The more critical the tasks are, the higher the demand for the robustness of the RL systems. Causal RL combines RL and causal inference to make RL more robust. Causal RL agents use a causal representation to capture the invariant causal mechanisms that can be transferred from one task to another. Currently, there is limited research in Causal RL, and existing solutions are usually not complete or feasible for real-world applications. In this work, we propose CausalCF, the first complete Causal RL solution incorporating ideas from Causal Curiosity and CoPhy. Causal Curiosity provides an approach for using interventions, and CoPhy is modified to enable the RL agent to perform counterfactuals. We apply CausalCF to complex robotic tasks and show that it improves the RL agent's robustness using a realistic simulation environment called CausalWorld.
ReCCoVER: Detecting Causal Confusion for Explainable Reinforcement Learning
Mar 21, 2022

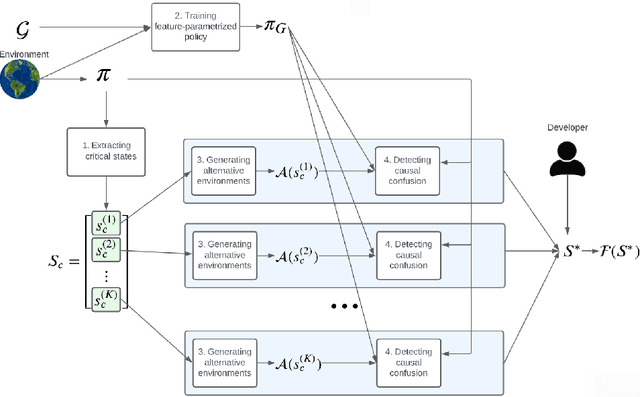

Despite notable results in various fields over the recent years, deep reinforcement learning (DRL) algorithms lack transparency, affecting user trust and hindering their deployment to high-risk tasks. Causal confusion refers to a phenomenon where an agent learns spurious correlations between features which might not hold across the entire state space, preventing safe deployment to real tasks where such correlations might be broken. In this work, we examine whether an agent relies on spurious correlations in critical states, and propose an alternative subset of features on which it should base its decisions instead, to make it less susceptible to causal confusion. Our goal is to increase transparency of DRL agents by exposing the influence of learned spurious correlations on its decisions, and offering advice to developers about feature selection in different parts of state space, to avoid causal confusion. We propose ReCCoVER, an algorithm which detects causal confusion in agent's reasoning before deployment, by executing its policy in alternative environments where certain correlations between features do not hold. We demonstrate our approach in taxi and grid world environments, where ReCCoVER detects states in which an agent relies on spurious correlations and offers a set of features that should be considered instead.
Contrastive Explanations for Comparing Preferences of Reinforcement Learning Agents
Dec 17, 2021


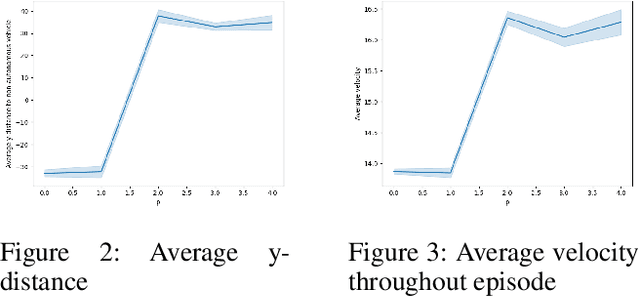
In complex tasks where the reward function is not straightforward and consists of a set of objectives, multiple reinforcement learning (RL) policies that perform task adequately, but employ different strategies can be trained by adjusting the impact of individual objectives on reward function. Understanding the differences in strategies between policies is necessary to enable users to choose between offered policies, and can help developers understand different behaviors that emerge from various reward functions and training hyperparameters in RL systems. In this work we compare behavior of two policies trained on the same task, but with different preferences in objectives. We propose a method for distinguishing between differences in behavior that stem from different abilities from those that are a consequence of opposing preferences of two RL agents. Furthermore, we use only data on preference-based differences in order to generate contrasting explanations about agents' preferences. Finally, we test and evaluate our approach on an autonomous driving task and compare the behavior of a safety-oriented policy and one that prefers speed.