 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMBA: Safe Model-Based & Active Reinforcement Learning
Paper and Code
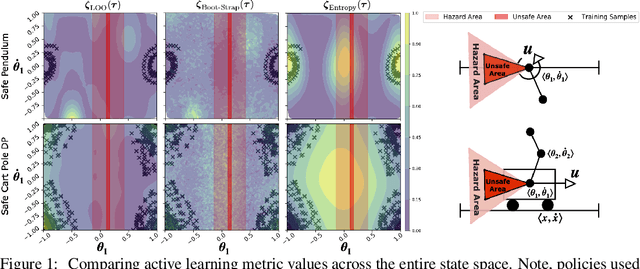
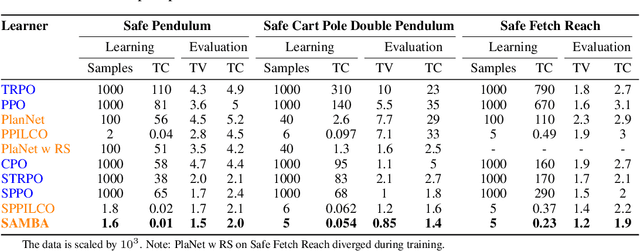
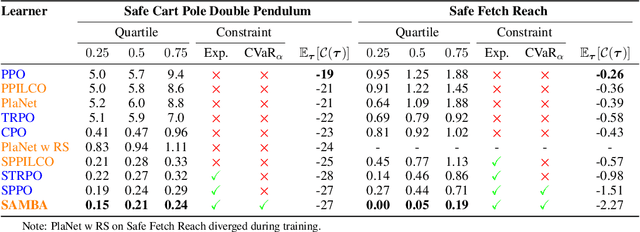
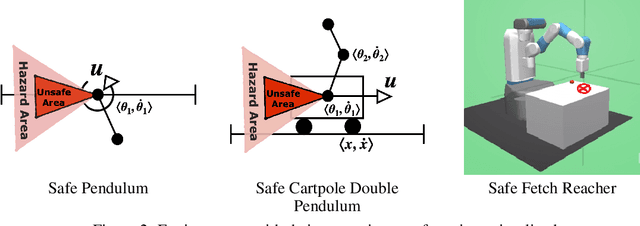
In this paper, we propose SAMBA, a novel framework for safe reinforcement learning that combines aspects from probabilistic modelling, information theory, and statistics. Our method builds upon PILCO to enable active exploration using novel(semi-)metrics for out-of-sample Gaussian process evaluation optimised through a multi-objective problem that supports conditional-value-at-risk constraints. We evaluate our algorithm on a variety of safe dynamical system benchmarks involving both low and high-dimensional state representations. Our results show orders of magnitude reductions in samples and violations compared to state-of-the-art methods. Lastly, we provide intuition as to the effectiveness of the framework by a detailed analysis of our active metrics and safety constraints.