 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMIR: Efficient Synthetic Data Pipeline To Improve Multi-Image Reasoning
Jan 07, 2025Vision-Language Models (VLMs) have shown strong performance in understanding single images, aided by numerous high-quality instruction datasets. However, multi-image reasoning tasks are still under-explored in the open-source community due to two main challenges: (1) scaling datasets with multiple correlated images and complex reasoning instructions is resource-intensive and maintaining quality is difficult, and (2) there is a lack of robust evaluation benchmarks for multi-image tasks. To address these issues, we introduce SMIR, an efficient synthetic data-generation pipeline for multi-image reasoning, and a high-quality dataset generated using this pipeline. Our pipeline efficiently extracts highly correlated images using multimodal embeddings, combining visual and descriptive information and leverages open-source LLMs to generate quality instructions. Using this pipeline, we generated 160K synthetic training samples, offering a cost-effective alternative to expensive closed-source solutions. Additionally, we present SMIR-BENCH, a novel multi-image reasoning evaluation benchmark comprising 200 diverse examples across 7 complex multi-image reasoning tasks. SMIR-BENCH is multi-turn and utilizes a VLM judge to evaluate free-form responses, providing a comprehensive assessment of model expressiveness and reasoning capability across modalities. We demonstrate the effectiveness of SMIR dataset by fine-tuning several open-source VLMs and evaluating their performance on SMIR-BENCH. Our results show that models trained on our dataset outperform baseline models in multi-image reasoning tasks up to 8% with a much more scalable data pipeline.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
LoLCATs: On Low-Rank Linearizing of Large Language Models
Oct 14, 2024

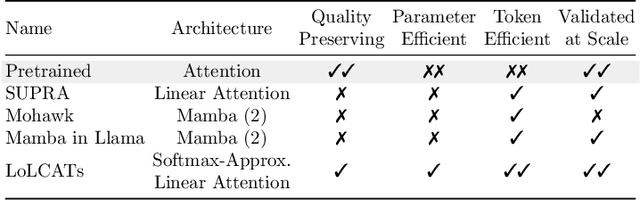

Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. We base these steps on two findings. First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer"). Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model
Jun 03, 2024
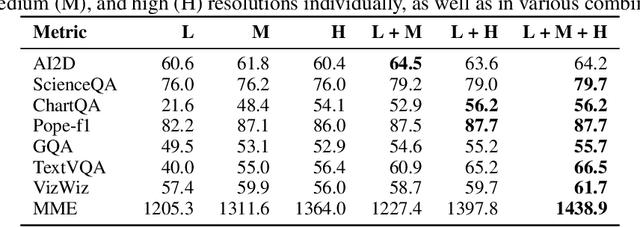
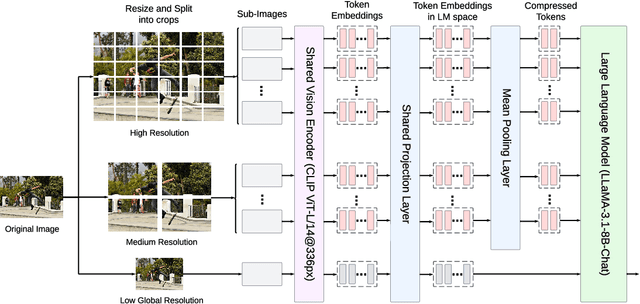

Recent advances in large multimodal models (LMMs) suggest that higher image resolution enhances the fine-grained understanding of image details, crucial for tasks such as visual commonsense reasoning and analyzing biomedical images. However, increasing input resolution poses two main challenges: 1) It extends the context length required by the language model, leading to inefficiencies and hitting the model's context limit; 2) It increases the complexity of visual features, necessitating more training data or more complex architecture. We introduce Dragonfly, a new LMM architecture that enhances fine-grained visual understanding and reasoning about image regions to address these challenges. Dragonfly employs two key strategies: multi-resolution visual encoding and zoom-in patch selection. These strategies allow the model to process high-resolution images efficiently while maintaining reasonable context length. Our experiments on eight popular benchmarks demonstrate that Dragonfly achieves competitive or better performance compared to other architectures, highlighting the effectiveness of our design. Additionally, we finetuned Dragonfly on biomedical instructions, achieving state-of-the-art results on multiple biomedical tasks requiring fine-grained visual understanding, including 92.3% accuracy on the Path-VQA dataset (compared to 83.3% for Med-Gemini) and the highest reported results on biomedical image captioning. To support model training, we curated a visual instruction-tuning dataset with 5.5 million image-instruction samples in the general domain and 1.4 million samples in the biomedical domain. We also conducted ablation studies to characterize the impact of various architectural designs and image resolutions, providing insights for future research on visual instruction alignment. The codebase and model are available at https://github.com/togethercomputer/Dragonfly.
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Jun 27, 2023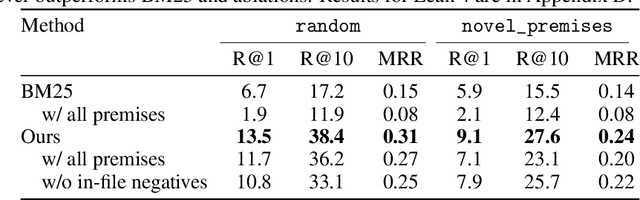
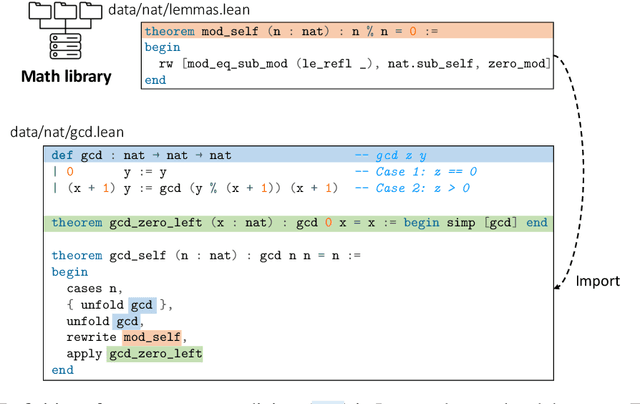

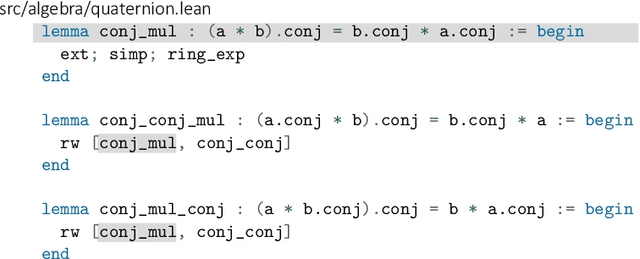
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): the first LLM-based prover that is augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 96,962 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.