 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025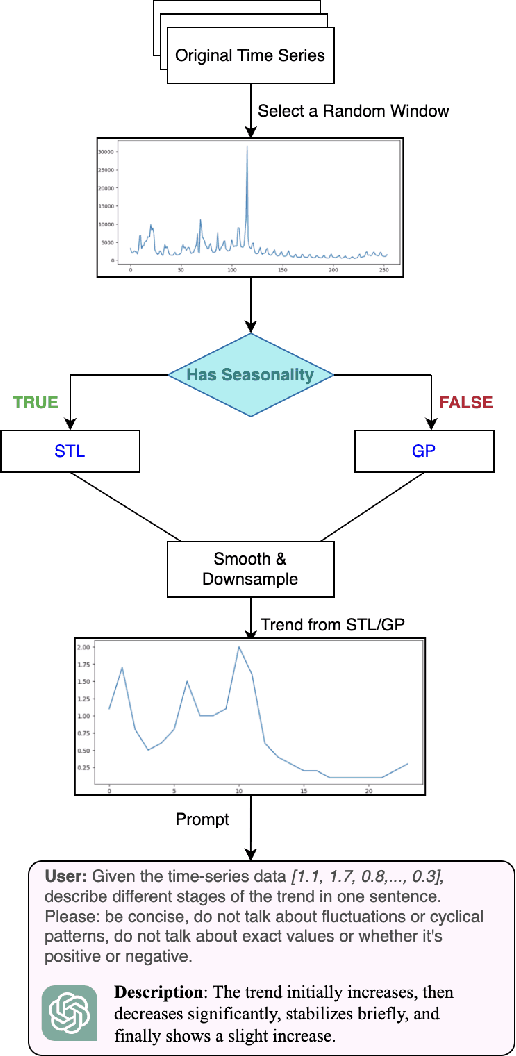
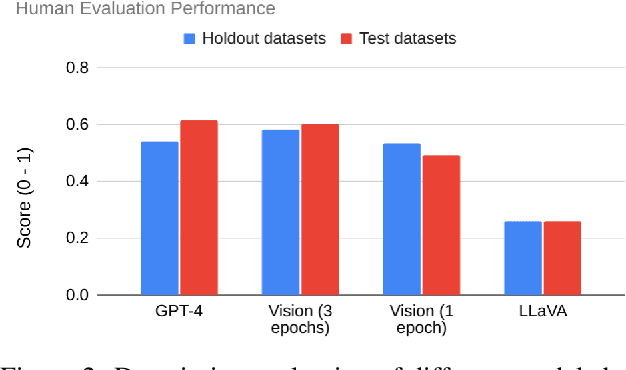
Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
SMIR: Efficient Synthetic Data Pipeline To Improve Multi-Image Reasoning
Jan 07, 2025Vision-Language Models (VLMs) have shown strong performance in understanding single images, aided by numerous high-quality instruction datasets. However, multi-image reasoning tasks are still under-explored in the open-source community due to two main challenges: (1) scaling datasets with multiple correlated images and complex reasoning instructions is resource-intensive and maintaining quality is difficult, and (2) there is a lack of robust evaluation benchmarks for multi-image tasks. To address these issues, we introduce SMIR, an efficient synthetic data-generation pipeline for multi-image reasoning, and a high-quality dataset generated using this pipeline. Our pipeline efficiently extracts highly correlated images using multimodal embeddings, combining visual and descriptive information and leverages open-source LLMs to generate quality instructions. Using this pipeline, we generated 160K synthetic training samples, offering a cost-effective alternative to expensive closed-source solutions. Additionally, we present SMIR-BENCH, a novel multi-image reasoning evaluation benchmark comprising 200 diverse examples across 7 complex multi-image reasoning tasks. SMIR-BENCH is multi-turn and utilizes a VLM judge to evaluate free-form responses, providing a comprehensive assessment of model expressiveness and reasoning capability across modalities. We demonstrate the effectiveness of SMIR dataset by fine-tuning several open-source VLMs and evaluating their performance on SMIR-BENCH. Our results show that models trained on our dataset outperform baseline models in multi-image reasoning tasks up to 8% with a much more scalable data pipeline.
Reinforcing Thinking through Reasoning-Enhanced Reward Models
Dec 31, 2024



Large Language Models (LLMs) exhibit great potential in complex multi-step reasoning through inference-time thinking but still struggle with deciding when to stop thinking due to limited self-awareness about their knowledge boundaries. While human preference alignment has shown extraordinary opportunities, expensive labeling challenges adherence to scaling law. Language model self-critique, as an alternative to using human-labeled reasoning data, is questioned with its inherited biases. This work addresses these challenges by distilling the LLM's own reasoning processes into synthetic behavioral data, eliminating the need for manual labeling of intermediate steps. Building on this concept, we propose Distillation-Reinforcement-Reasoning (DRR), a three-step framework that leverages the LLM's inherent behaviors as external feedback by first generating behavioral data using the Reasoner (LLM) to reflect its reasoning capabilities, then training a lightweight discriminative reward model (DM) on behavioral data, and finally deploying the DM at inference time to assist the Reasoner's decision-making. Experiments on multiple benchmarks show that the DRR framework outperforms self-critique approaches without relying on additional complex data annotation. Benefiting from lightweight design, ease of replication, and adaptability, DRR is applicable to a wide range of LLM-centric tasks.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Hybrid Primal Sketch: Combining Analogy, Qualitative Representations, and Computer Vision for Scene Understanding
Jul 05, 2024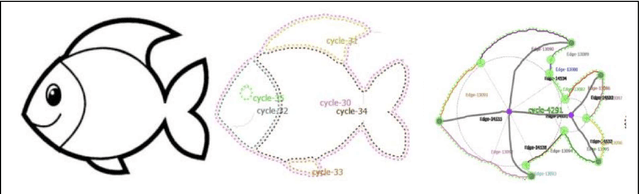
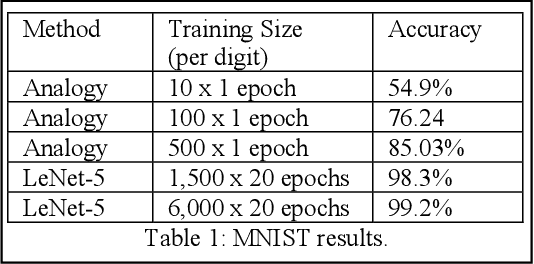
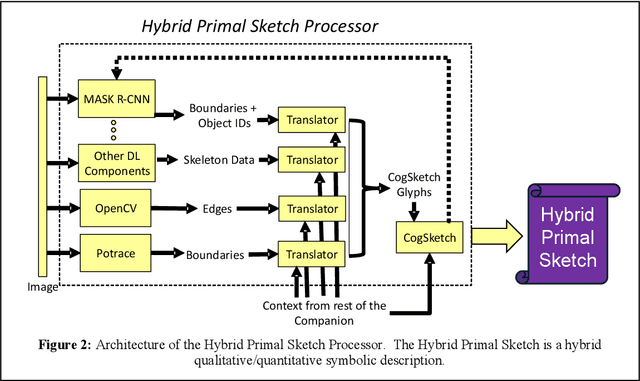
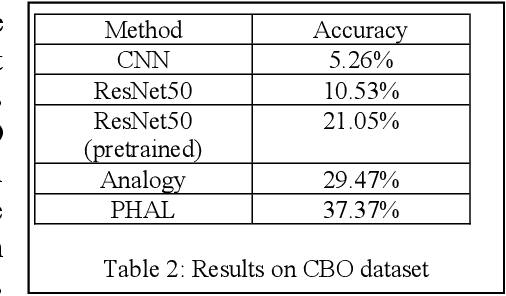
One of the purposes of perception is to bridge between sensors and conceptual understanding. Marr's Primal Sketch combined initial edge-finding with multiple downstream processes to capture aspects of visual perception such as grouping and stereopsis. Given the progress made in multiple areas of AI since then, we have developed a new framework inspired by Marr's work, the Hybrid Primal Sketch, which combines computer vision components into an ensemble to produce sketch-like entities which are then further processed by CogSketch, our model of high-level human vision, to produce both more detailed shape representations and scene representations which can be used for data-efficient learning via analogical generalization. This paper describes our theoretical framework, summarizes several previous experiments, and outlines a new experiment in progress on diagram understanding.
Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model
Jun 03, 2024
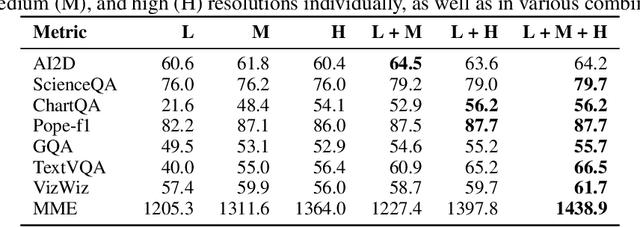
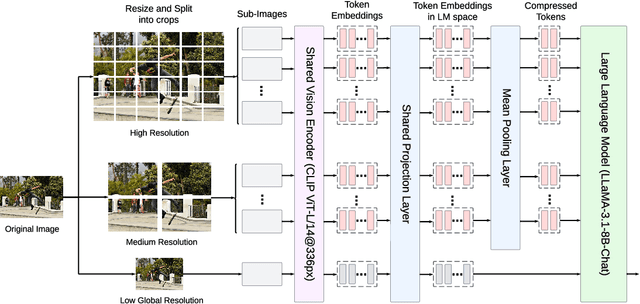

Recent advances in large multimodal models (LMMs) suggest that higher image resolution enhances the fine-grained understanding of image details, crucial for tasks such as visual commonsense reasoning and analyzing biomedical images. However, increasing input resolution poses two main challenges: 1) It extends the context length required by the language model, leading to inefficiencies and hitting the model's context limit; 2) It increases the complexity of visual features, necessitating more training data or more complex architecture. We introduce Dragonfly, a new LMM architecture that enhances fine-grained visual understanding and reasoning about image regions to address these challenges. Dragonfly employs two key strategies: multi-resolution visual encoding and zoom-in patch selection. These strategies allow the model to process high-resolution images efficiently while maintaining reasonable context length. Our experiments on eight popular benchmarks demonstrate that Dragonfly achieves competitive or better performance compared to other architectures, highlighting the effectiveness of our design. Additionally, we finetuned Dragonfly on biomedical instructions, achieving state-of-the-art results on multiple biomedical tasks requiring fine-grained visual understanding, including 92.3% accuracy on the Path-VQA dataset (compared to 83.3% for Med-Gemini) and the highest reported results on biomedical image captioning. To support model training, we curated a visual instruction-tuning dataset with 5.5 million image-instruction samples in the general domain and 1.4 million samples in the biomedical domain. We also conducted ablation studies to characterize the impact of various architectural designs and image resolutions, providing insights for future research on visual instruction alignment. The codebase and model are available at https://github.com/togethercomputer/Dragonfly.
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
May 15, 2024



Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
Higher Layers Need More LoRA Experts
Feb 13, 2024



Parameter-efficient tuning (PEFT) techniques like low-rank adaptation (LoRA) offer training efficiency on Large Language Models, but their impact on model performance remains limited. Recent efforts integrate LoRA and Mixture-of-Experts (MoE) to improve the performance of PEFT methods. Despite promising results, research on improving the efficiency of LoRA with MoE is still in its early stages. Recent studies have shown that experts in the MoE architecture have different strengths and also exhibit some redundancy. Does this statement also apply to parameter-efficient MoE? In this paper, we introduce a novel parameter-efficient MoE method, \textit{\textbf{M}oE-L\textbf{o}RA with \textbf{L}ayer-wise Expert \textbf{A}llocation (MoLA)} for Transformer-based models, where each model layer has the flexibility to employ a varying number of LoRA experts. We investigate several architectures with varying layer-wise expert configurations. Experiments on six well-known NLP and commonsense QA benchmarks demonstrate that MoLA achieves equal or superior performance compared to all baselines. We find that allocating more LoRA experts to higher layers further enhances the effectiveness of models with a certain number of experts in total. With much fewer parameters, this allocation strategy outperforms the setting with the same number of experts in every layer. This work can be widely used as a plug-and-play parameter-efficient tuning approach for various applications. The code is available at https://github.com/GCYZSL/MoLA.
Evaluation and Mitigation of Agnosia in Multimodal Large Language Models
Sep 07, 2023



While Multimodal Large Language Models (MLLMs) are widely used for a variety of vision-language tasks, one observation is that they sometimes misinterpret visual inputs or fail to follow textual instructions even in straightforward cases, leading to irrelevant responses, mistakes, and ungrounded claims. This observation is analogous to a phenomenon in neuropsychology known as Agnosia, an inability to correctly process sensory modalities and recognize things (e.g., objects, colors, relations). In our study, we adapt this similar concept to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process in neuropsychology, we propose a novel framework EMMA (Evaluation and Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module that automatically creates fine-grained and diverse visual question answering examples to assess the extent of agnosia in MLLMs comprehensively. We also develop a mitigation module to reduce agnosia in MLLMs through multimodal instruction tuning on fine-grained conversations. To verify the effectiveness of our framework, we evaluate and analyze agnosia in seven state-of-the-art MLLMs using 9K test samples. The results reveal that most of them exhibit agnosia across various aspects and degrees. We further develop a fine-grained instruction set and tune MLLMs to mitigate agnosia, which led to notable improvement in accuracy.