 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher Layers Need More LoRA Experts
Feb 13, 2024



Parameter-efficient tuning (PEFT) techniques like low-rank adaptation (LoRA) offer training efficiency on Large Language Models, but their impact on model performance remains limited. Recent efforts integrate LoRA and Mixture-of-Experts (MoE) to improve the performance of PEFT methods. Despite promising results, research on improving the efficiency of LoRA with MoE is still in its early stages. Recent studies have shown that experts in the MoE architecture have different strengths and also exhibit some redundancy. Does this statement also apply to parameter-efficient MoE? In this paper, we introduce a novel parameter-efficient MoE method, \textit{\textbf{M}oE-L\textbf{o}RA with \textbf{L}ayer-wise Expert \textbf{A}llocation (MoLA)} for Transformer-based models, where each model layer has the flexibility to employ a varying number of LoRA experts. We investigate several architectures with varying layer-wise expert configurations. Experiments on six well-known NLP and commonsense QA benchmarks demonstrate that MoLA achieves equal or superior performance compared to all baselines. We find that allocating more LoRA experts to higher layers further enhances the effectiveness of models with a certain number of experts in total. With much fewer parameters, this allocation strategy outperforms the setting with the same number of experts in every layer. This work can be widely used as a plug-and-play parameter-efficient tuning approach for various applications. The code is available at https://github.com/GCYZSL/MoLA.
Evaluation and Mitigation of Agnosia in Multimodal Large Language Models
Sep 07, 2023



While Multimodal Large Language Models (MLLMs) are widely used for a variety of vision-language tasks, one observation is that they sometimes misinterpret visual inputs or fail to follow textual instructions even in straightforward cases, leading to irrelevant responses, mistakes, and ungrounded claims. This observation is analogous to a phenomenon in neuropsychology known as Agnosia, an inability to correctly process sensory modalities and recognize things (e.g., objects, colors, relations). In our study, we adapt this similar concept to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process in neuropsychology, we propose a novel framework EMMA (Evaluation and Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module that automatically creates fine-grained and diverse visual question answering examples to assess the extent of agnosia in MLLMs comprehensively. We also develop a mitigation module to reduce agnosia in MLLMs through multimodal instruction tuning on fine-grained conversations. To verify the effectiveness of our framework, we evaluate and analyze agnosia in seven state-of-the-art MLLMs using 9K test samples. The results reveal that most of them exhibit agnosia across various aspects and degrees. We further develop a fine-grained instruction set and tune MLLMs to mitigate agnosia, which led to notable improvement in accuracy.
A Fast Minimization Algorithm for the Euler Elastica Model Based on a Bilinear Decomposition
Aug 25, 2023



The Euler Elastica (EE) model with surface curvature can generate artifact-free results compared with the traditional total variation regularization model in image processing. However, strong nonlinearity and singularity due to the curvature term in the EE model pose a great challenge for one to design fast and stable algorithms for the EE model. In this paper, we propose a new, fast, hybrid alternating minimization (HALM) algorithm for the EE model based on a bilinear decomposition of the gradient of the underlying image and prove the global convergence of the minimizing sequence generated by the algorithm under mild conditions. The HALM algorithm comprises three sub-minimization problems and each is either solved in the closed form or approximated by fast solvers making the new algorithm highly accurate and efficient. We also discuss the extension of the HALM strategy to deal with general curvature-based variational models, especially with a Lipschitz smooth functional of the curvature. A host of numerical experiments are conducted to show that the new algorithm produces good results with much-improved efficiency compared to other state-of-the-art algorithms for the EE model. As one of the benchmarks, we show that the average running time of the HALM algorithm is at most one-quarter of that of the fast operator-splitting-based Deng-Glowinski-Tai algorithm.
LOWA: Localize Objects in the Wild with Attributes
May 31, 2023

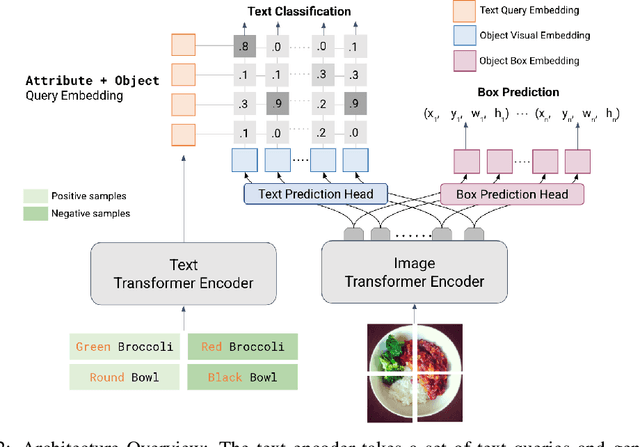
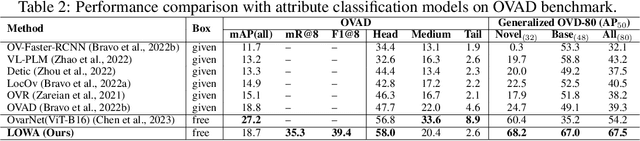
We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
LossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023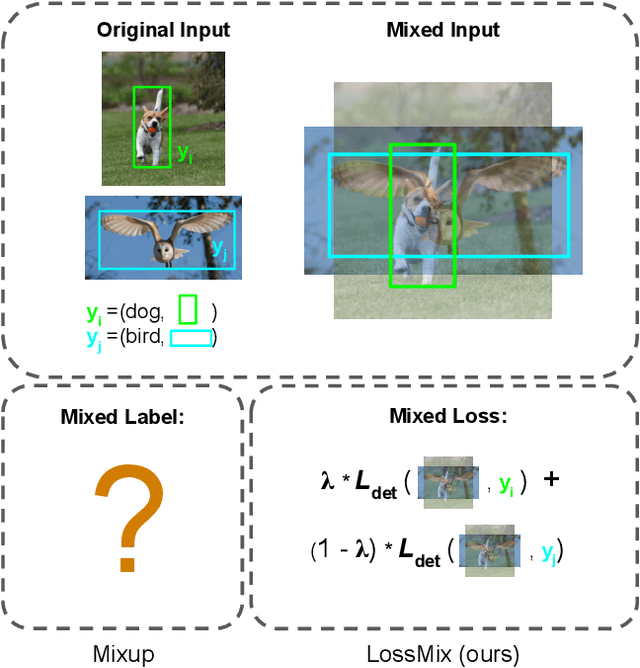
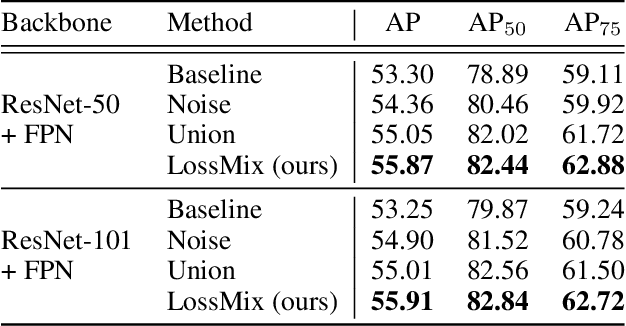
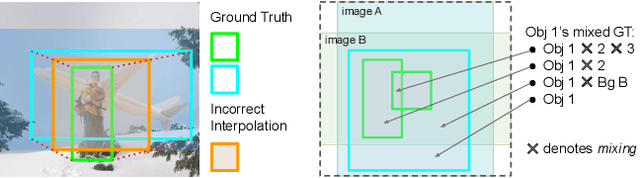
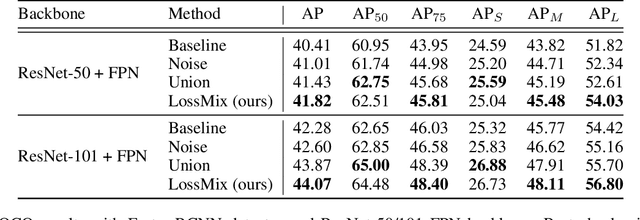
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
Correlation Alignment for Unsupervised Domain Adaptation
Dec 06, 2016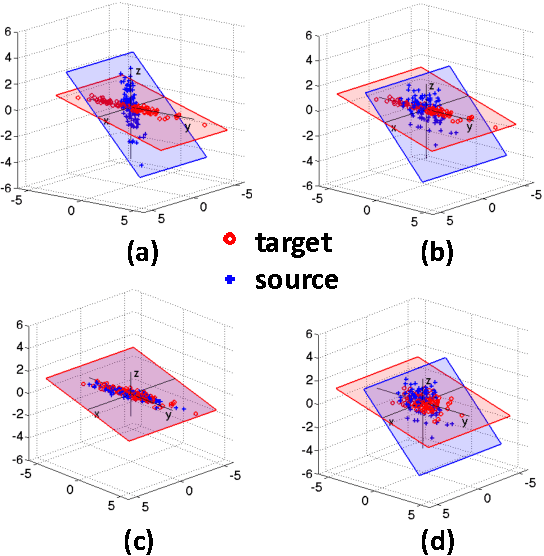
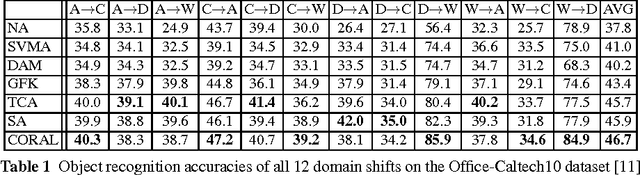
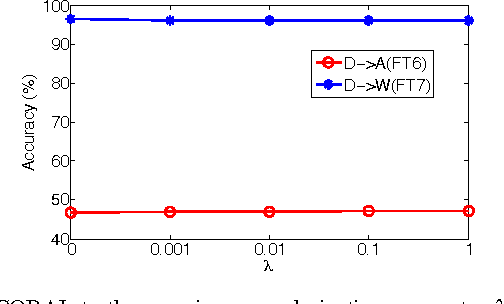
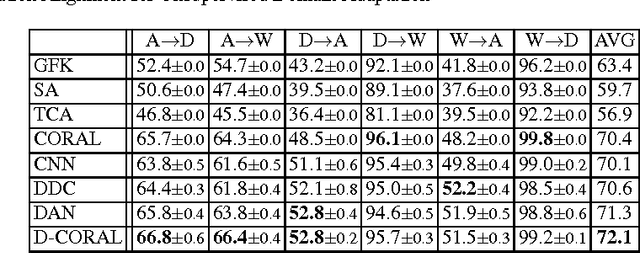
In this chapter, we present CORrelation ALignment (CORAL), a simple yet effective method for unsupervised domain adaptation. CORAL minimizes domain shift by aligning the second-order statistics of source and target distributions, without requiring any target labels. In contrast to subspace manifold methods, it aligns the original feature distributions of the source and target domains, rather than the bases of lower-dimensional subspaces. It is also much simpler than other distribution matching methods. CORAL performs remarkably well in extensive evaluations on standard benchmark datasets. We first describe a solution that applies a linear transformation to source features to align them with target features before classifier training. For linear classifiers, we propose to equivalently apply CORAL to the classifier weights, leading to added efficiency when the number of classifiers is small but the number and dimensionality of target examples are very high. The resulting CORAL Linear Discriminant Analysis (CORAL-LDA) outperforms LDA by a large margin on standard domain adaptation benchmarks. Finally, we extend CORAL to learn a nonlinear transformation that aligns correlations of layer activations in deep neural networks (DNNs). The resulting Deep CORAL approach works seamlessly with DNNs and achieves state-of-the-art performance on standard benchmark datasets. Our code is available at:~\url{https://github.com/VisionLearningGroup/CORAL}
Deep CORAL: Correlation Alignment for Deep Domain Adaptation
Jul 06, 2016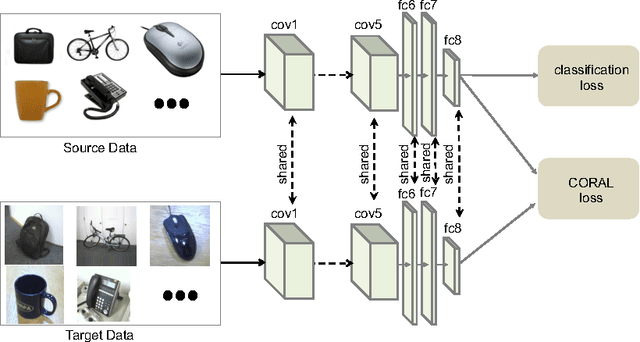
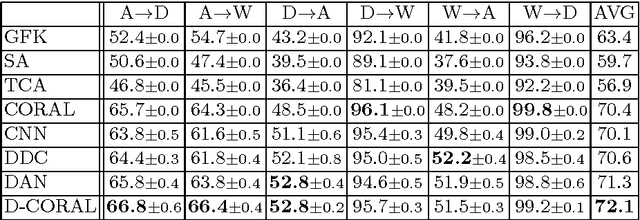
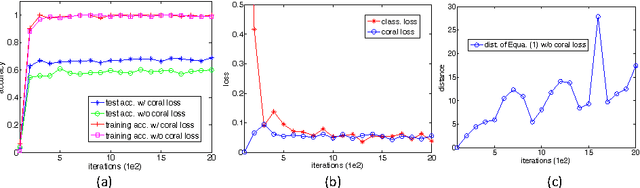
Deep neural networks are able to learn powerful representations from large quantities of labeled input data, however they cannot always generalize well across changes in input distributions. Domain adaptation algorithms have been proposed to compensate for the degradation in performance due to domain shift. In this paper, we address the case when the target domain is unlabeled, requiring unsupervised adaptation. CORAL is a "frustratingly easy" unsupervised domain adaptation method that aligns the second-order statistics of the source and target distributions with a linear transformation. Here, we extend CORAL to learn a nonlinear transformation that aligns correlations of layer activations in deep neural networks (Deep CORAL). Experiments on standard benchmark datasets show state-of-the-art performance.
Return of Frustratingly Easy Domain Adaptation
Dec 09, 2015

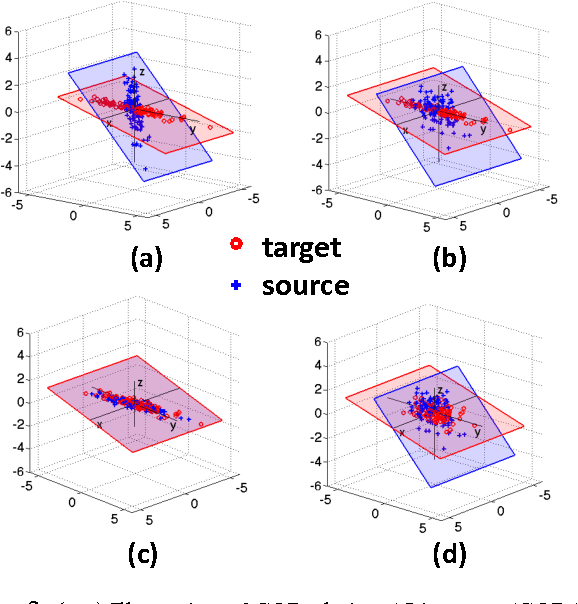
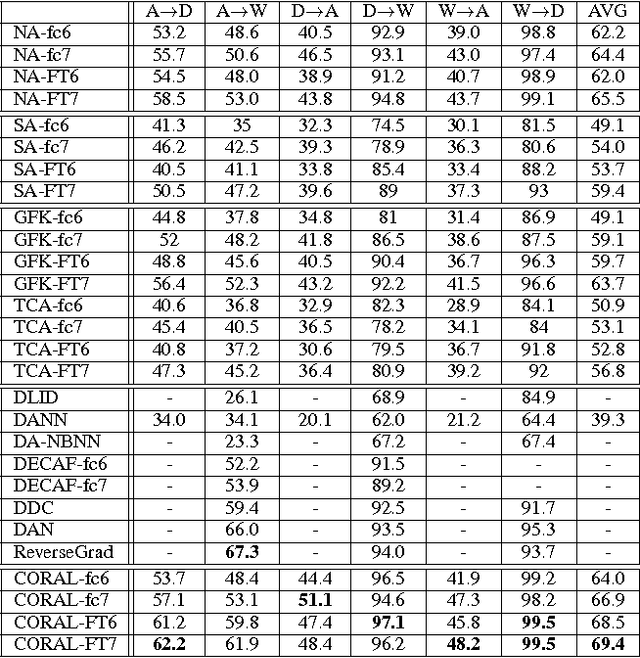
Unlike human learning, machine learning often fails to handle changes between training (source) and test (target) input distributions. Such domain shifts, common in practical scenarios, severely damage the performance of conventional machine learning methods. Supervised domain adaptation methods have been proposed for the case when the target data have labels, including some that perform very well despite being "frustratingly easy" to implement. However, in practice, the target domain is often unlabeled, requiring unsupervised adaptation. We propose a simple, effective, and efficient method for unsupervised domain adaptation called CORrelation ALignment (CORAL). CORAL minimizes domain shift by aligning the second-order statistics of source and target distributions, without requiring any target labels. Even though it is extraordinarily simple--it can be implemented in four lines of Matlab code--CORAL performs remarkably well in extensive evaluations on standard benchmark datasets.
Learning Deep Object Detectors from 3D Models
Oct 12, 2015
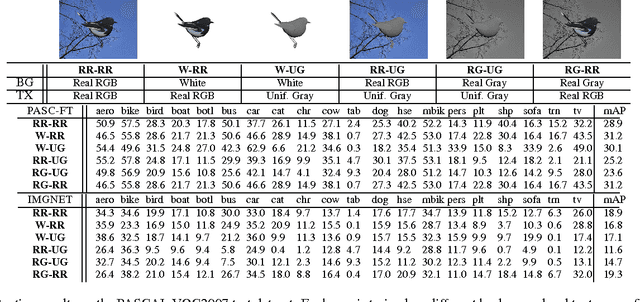
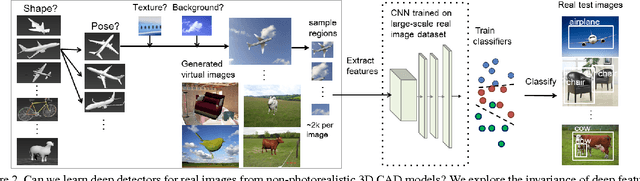
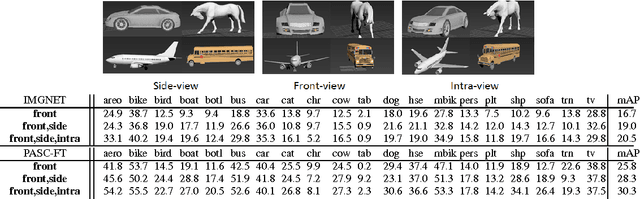
Crowdsourced 3D CAD models are becoming easily accessible online, and can potentially generate an infinite number of training images for almost any object category.We show that augmenting the training data of contemporary Deep Convolutional Neural Net (DCNN) models with such synthetic data can be effective, especially when real training data is limited or not well matched to the target domain. Most freely available CAD models capture 3D shape but are often missing other low level cues, such as realistic object texture, pose, or background. In a detailed analysis, we use synthetic CAD-rendered images to probe the ability of DCNN to learn without these cues, with surprising findings. In particular, we show that when the DCNN is fine-tuned on the target detection task, it exhibits a large degree of invariance to missing low-level cues, but, when pretrained on generic ImageNet classification, it learns better when the low-level cues are simulated. We show that our synthetic DCNN training approach significantly outperforms previous methods on the PASCAL VOC2007 dataset when learning in the few-shot scenario and improves performance in a domain shift scenario on the Office benchmark.
What Do Deep CNNs Learn About Objects?
Apr 09, 2015

Deep convolutional neural networks learn extremely powerful image representations, yet most of that power is hidden in the millions of deep-layer parameters. What exactly do these parameters represent? Recent work has started to analyse CNN representations, finding that, e.g., they are invariant to some 2D transformations Fischer et al. (2014), but are confused by particular types of image noise Nguyen et al. (2014). In this work, we delve deeper and ask: how invariant are CNNs to object-class variations caused by 3D shape, pose, and photorealism?