 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023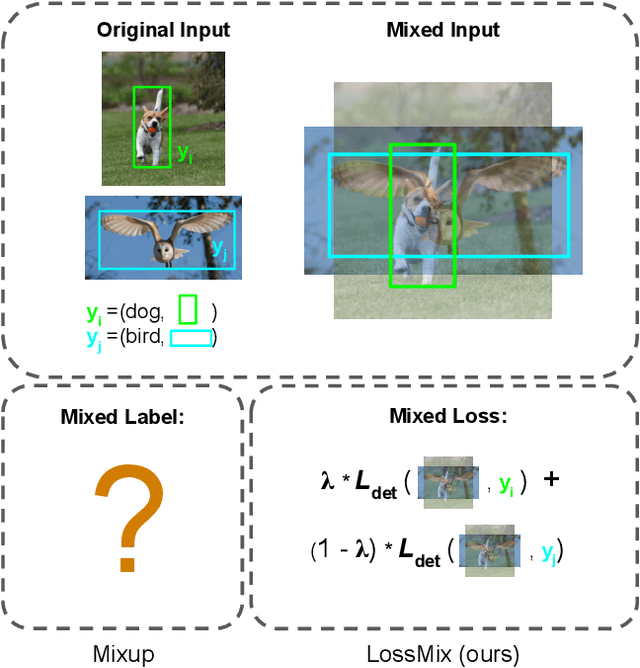
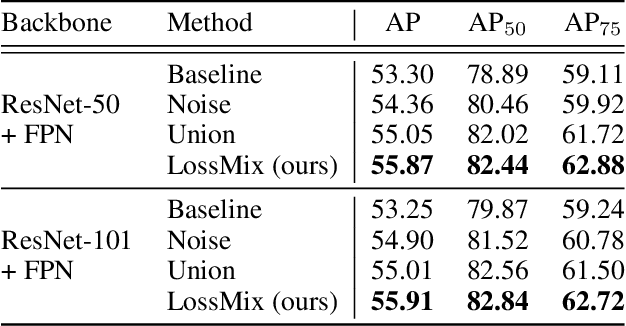
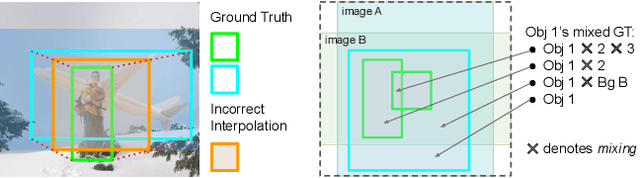
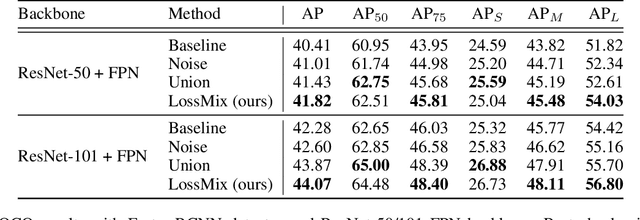
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
Allowing Safe Contact in Robotic Goal-Reaching: Planning and Tracking in Operational and Null Spaces
Oct 31, 2022



In recent years, impressive results have been achieved in robotic manipulation. While many efforts focus on generating collision-free reference signals, few allow safe contact between the robot bodies and the environment. However, in human's daily manipulation, contact between arms and obstacles is prevalent and even necessary. This paper investigates the benefit of allowing safe contact during robotic manipulation and advocates generating and tracking compliance reference signals in both operational and null spaces. In addition, to optimize the collision-allowed trajectories, we present a hybrid solver that integrates sampling- and gradient-based approaches. We evaluate the proposed method on a goal-reaching task in five simulated and real-world environments with different collisional conditions. We show that allowing safe contact improves goal-reaching efficiency and provides feasible solutions in highly collisional scenarios where collision-free constraints cannot be enforced. Moreover, we demonstrate that planning in null space, in addition to operational space, improves trajectory safety.
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
Aug 20, 2021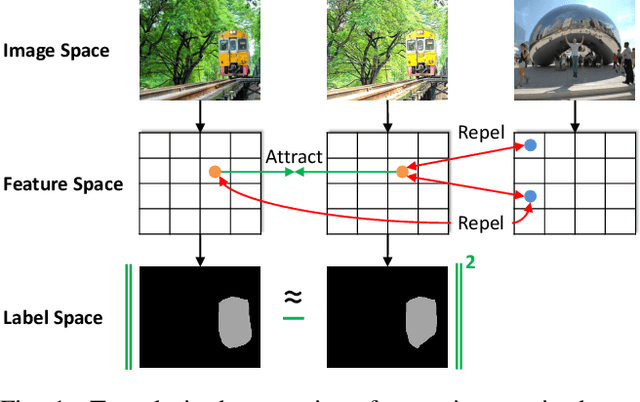
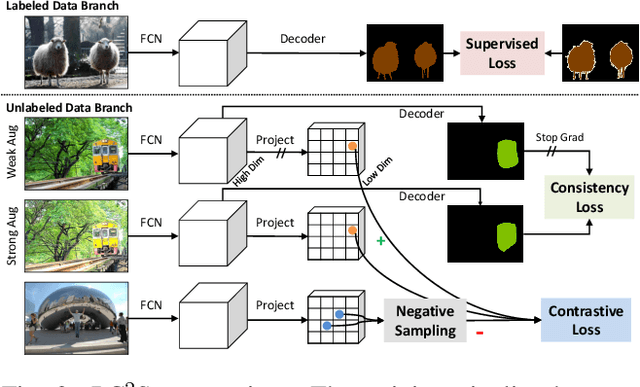
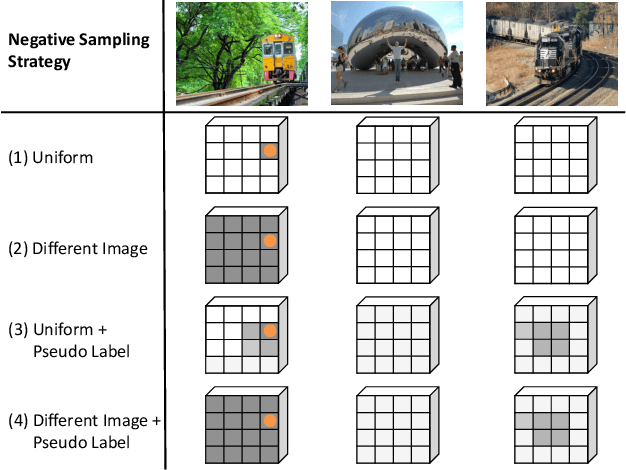

We present a novel semi-supervised semantic segmentation method which jointly achieves two desiderata of segmentation model regularities: the label-space consistency property between image augmentations and the feature-space contrastive property among different pixels. We leverage the pixel-level L2 loss and the pixel contrastive loss for the two purposes respectively. To address the computational efficiency issue and the false negative noise issue involved in the pixel contrastive loss, we further introduce and investigate several negative sampling techniques. Extensive experiments demonstrate the state-of-the-art performance of our method (PC2Seg) with the DeepLab-v3+ architecture, in several challenging semi-supervised settings derived from the VOC, Cityscapes, and COCO datasets.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
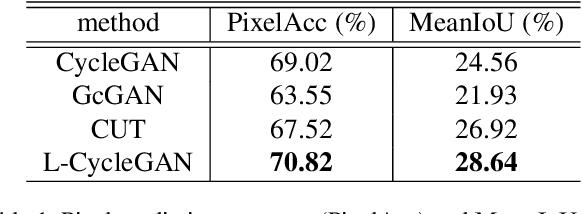

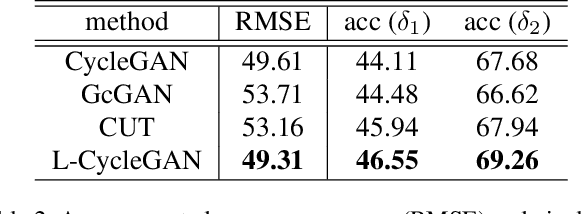
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Model-free Deep Reinforcement Learning for Urban Autonomous Driving
Apr 20, 2019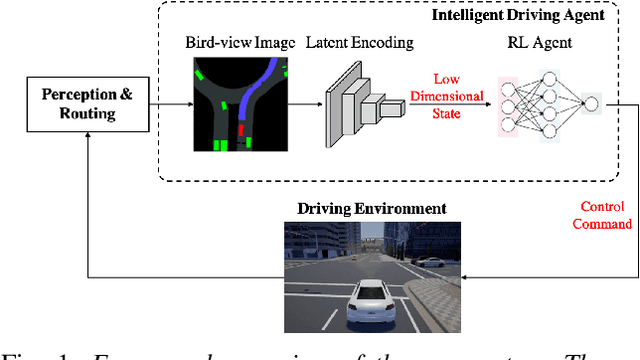
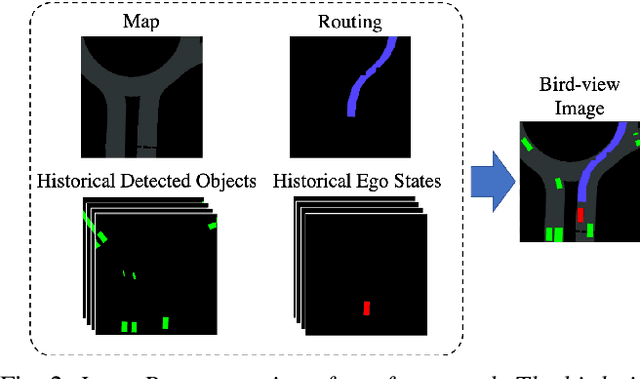
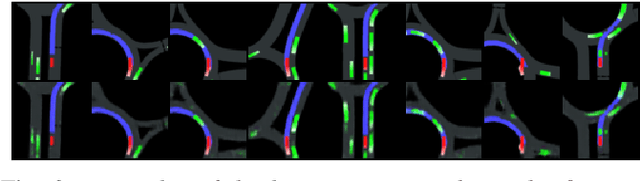
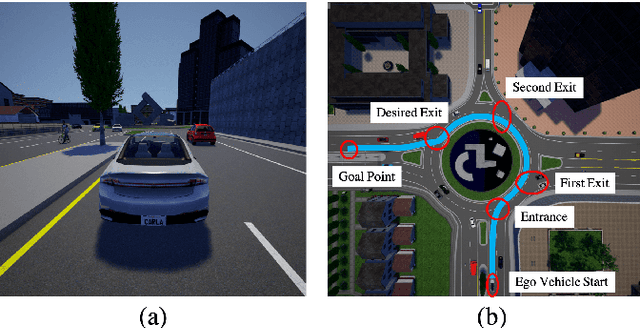
Urban autonomous driving decision making is challenging due to complex road geometry and multi-agent interactions. Current decision making methods are mostly manually designing the driving policy, which might result in sub-optimal solutions and is expensive to develop, generalize and maintain at scale. On the other hand, with reinforcement learning (RL), a policy can be learned and improved automatically without any manual designs. However, current RL methods generally do not work well on complex urban scenarios. In this paper, we propose a framework to enable model-free deep reinforcement learning in challenging urban autonomous driving scenarios. We design a specific input representation and use visual encoding to capture the low-dimensional latent states. Several state-of-the-art model-free deep RL algorithms are implemented into our framework, with several tricks to improve their performance. We evaluate our method in a challenging roundabout task with dense surrounding vehicles in a high-definition driving simulator. The result shows that our method can solve the task well and is significantly better than the baseline.
Deep Imitation Learning for Autonomous Driving in Generic Urban Scenarios with Enhanced Safety
Mar 02, 2019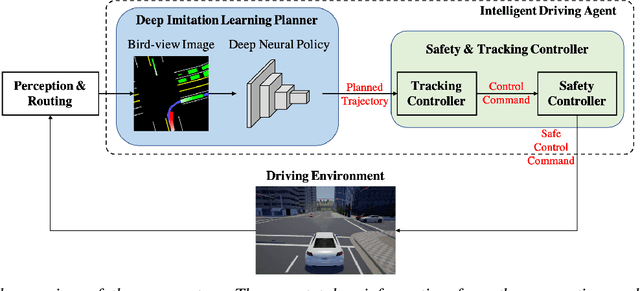
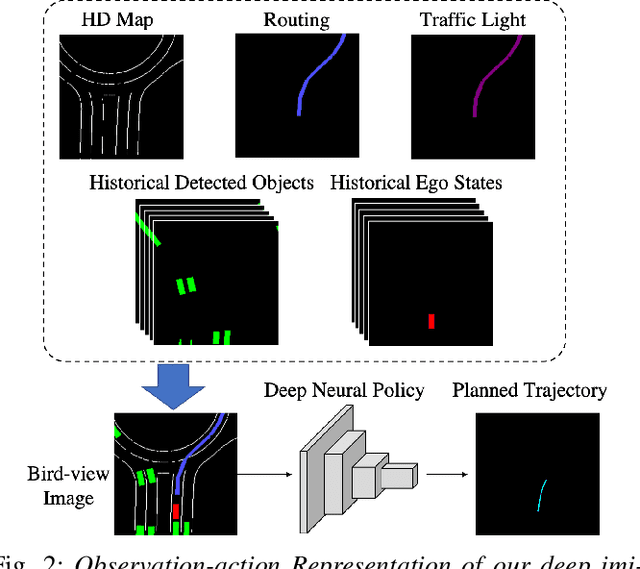
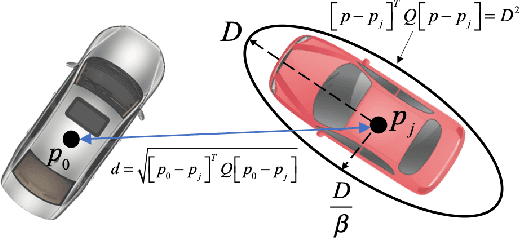

The decision and planning system for autonomous driving in urban environments is hard to design. Most current methods are to manually design the driving policy, which can be sub-optimal and expensive to develop and maintain at scale. Instead, with imitation learning we only need to collect data and then the computer will learn and improve the driving policy automatically. However, existing imitation learning methods for autonomous driving are hardly performing well for complex urban scenarios. Moreover, the safety is not guaranteed when we use a deep neural network policy. In this paper, we proposed a framework to learn the driving policy in urban scenarios efficiently given offline connected driving data, with a safety controller incorporated to guarantee safety at test time. The experiments show that our method can achieve high performance in realistic three-dimensional simulations of urban driving scenarios, with only hours of data collection and training on a single consumer GPU.