 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Object Detectors from 3D Models
Oct 12, 2015
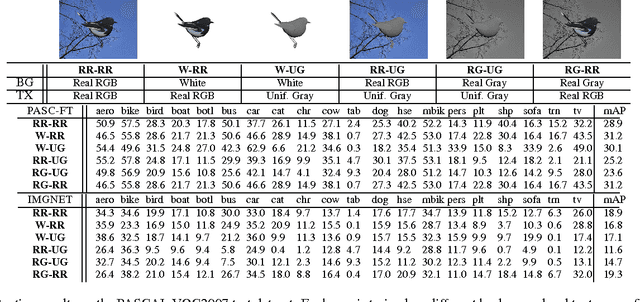
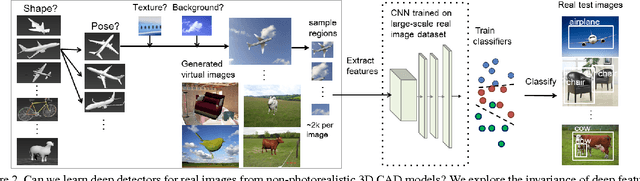
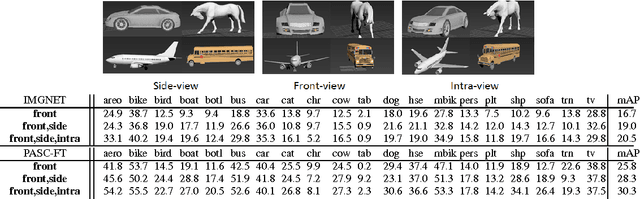
Crowdsourced 3D CAD models are becoming easily accessible online, and can potentially generate an infinite number of training images for almost any object category.We show that augmenting the training data of contemporary Deep Convolutional Neural Net (DCNN) models with such synthetic data can be effective, especially when real training data is limited or not well matched to the target domain. Most freely available CAD models capture 3D shape but are often missing other low level cues, such as realistic object texture, pose, or background. In a detailed analysis, we use synthetic CAD-rendered images to probe the ability of DCNN to learn without these cues, with surprising findings. In particular, we show that when the DCNN is fine-tuned on the target detection task, it exhibits a large degree of invariance to missing low-level cues, but, when pretrained on generic ImageNet classification, it learns better when the low-level cues are simulated. We show that our synthetic DCNN training approach significantly outperforms previous methods on the PASCAL VOC2007 dataset when learning in the few-shot scenario and improves performance in a domain shift scenario on the Office benchmark.
What Do Deep CNNs Learn About Objects?
Apr 09, 2015

Deep convolutional neural networks learn extremely powerful image representations, yet most of that power is hidden in the millions of deep-layer parameters. What exactly do these parameters represent? Recent work has started to analyse CNN representations, finding that, e.g., they are invariant to some 2D transformations Fischer et al. (2014), but are confused by particular types of image noise Nguyen et al. (2014). In this work, we delve deeper and ask: how invariant are CNNs to object-class variations caused by 3D shape, pose, and photorealism?