 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Proving Test Set Contamination in Black Box Language Models
Oct 26, 2023Large language models are trained on vast amounts of internet data, prompting concerns and speculation that they have memorized public benchmarks. Going from speculation to proof of contamination is challenging, as the pretraining data used by proprietary models are often not publicly accessible. We show that it is possible to provide provable guarantees of test set contamination in language models without access to pretraining data or model weights. Our approach leverages the fact that when there is no data contamination, all orderings of an exchangeable benchmark should be equally likely. In contrast, the tendency for language models to memorize example order means that a contaminated language model will find certain canonical orderings to be much more likely than others. Our test flags potential contamination whenever the likelihood of a canonically ordered benchmark dataset is significantly higher than the likelihood after shuffling the examples. We demonstrate that our procedure is sensitive enough to reliably prove test set contamination in challenging situations, including models as small as 1.4 billion parameters, on small test sets of only 1000 examples, and datasets that appear only a few times in the pretraining corpus. Using our test, we audit five popular publicly accessible language models for test set contamination and find little evidence for pervasive contamination.
Distributionally Robust Language Modeling
Sep 04, 2019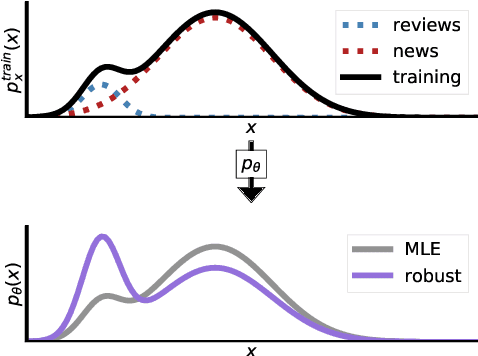

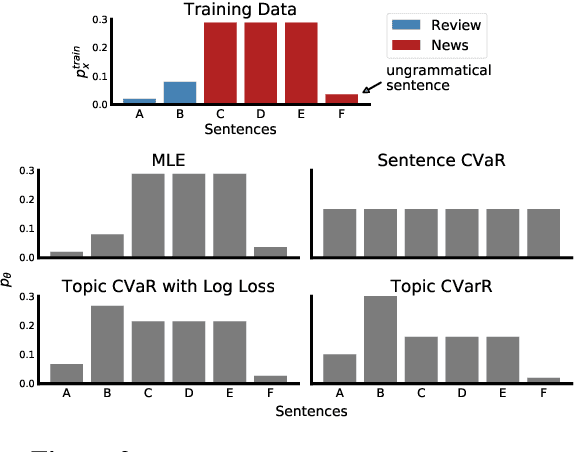
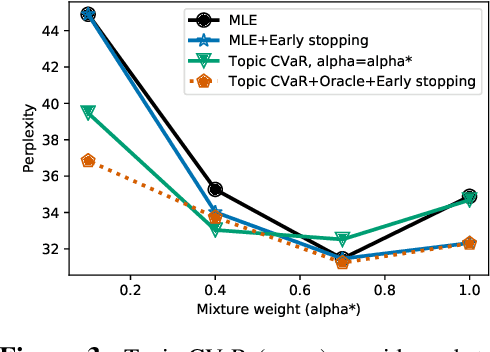
Language models are generally trained on data spanning a wide range of topics (e.g., news, reviews, fiction), but they might be applied to an a priori unknown target distribution (e.g., restaurant reviews). In this paper, we first show that training on text outside the test distribution can degrade test performance when using standard maximum likelihood (MLE) training. To remedy this without the knowledge of the test distribution, we propose an approach which trains a model that performs well over a wide range of potential test distributions. In particular, we derive a new distributionally robust optimization (DRO) procedure which minimizes the loss of the model over the worst-case mixture of topics with sufficient overlap with the training distribution. Our approach, called topic conditional value at risk (topic CVaR), obtains a 5.5 point perplexity reduction over MLE when the language models are trained on a mixture of Yelp reviews and news and tested only on reviews.
A Retrieve-and-Edit Framework for Predicting Structured Outputs
Dec 04, 2018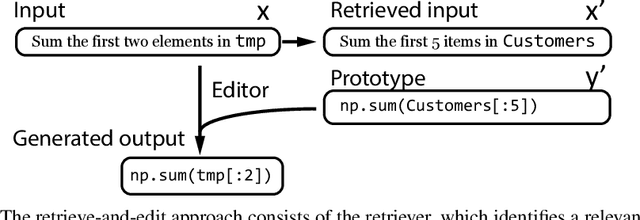



For the task of generating complex outputs such as source code, editing existing outputs can be easier than generating complex outputs from scratch. With this motivation, we propose an approach that first retrieves a training example based on the input (e.g., natural language description) and then edits it to the desired output (e.g., code). Our contribution is a computationally efficient method for learning a retrieval model that embeds the input in a task-dependent way without relying on a hand-crafted metric or incurring the expense of jointly training the retriever with the editor. Our retrieve-and-edit framework can be applied on top of any base model. We show that on a new autocomplete task for GitHub Python code and the Hearthstone cards benchmark, retrieve-and-edit significantly boosts the performance of a vanilla sequence-to-sequence model on both tasks.
Generating Sentences by Editing Prototypes
Sep 07, 2018We propose a new generative model of sentences that first samples a prototype sentence from the training corpus and then edits it into a new sentence. Compared to traditional models that generate from scratch either left-to-right or by first sampling a latent sentence vector, our prototype-then-edit model improves perplexity on language modeling and generates higher quality outputs according to human evaluation. Furthermore, the model gives rise to a latent edit vector that captures interpretable semantics such as sentence similarity and sentence-level analogies.