 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFARTrack: Fast Autoregressive Visual Tracking with High Performance
Feb 03, 2026Inference speed and tracking performance are two critical evaluation metrics in the field of visual tracking. However, high-performance trackers often suffer from slow processing speeds, making them impractical for deployment on resource-constrained devices. To alleviate this issue, we propose FARTrack, a Fast Auto-Regressive Tracking framework. Since autoregression emphasizes the temporal nature of the trajectory sequence, it can maintain high performance while achieving efficient execution across various devices. FARTrack introduces Task-Specific Self-Distillation and Inter-frame Autoregressive Sparsification, designed from the perspectives of shallow-yet-accurate distillation and redundant-to-essential token optimization, respectively. Task-Specific Self-Distillation achieves model compression by distilling task-specific tokens layer by layer, enhancing the model's inference speed while avoiding suboptimal manual teacher-student layer pairs assignments. Meanwhile, Inter-frame Autoregressive Sparsification sequentially condenses multiple templates, avoiding additional runtime overhead while learning a temporally-global optimal sparsification strategy. FARTrack demonstrates outstanding speed and competitive performance. It delivers an AO of 70.6% on GOT-10k in real-time. Beyond, our fastest model achieves a speed of 343 FPS on the GPU and 121 FPS on the CPU.
GeoPep: A geometry-aware masked language model for protein-peptide binding site prediction
Oct 30, 2025Multimodal approaches that integrate protein structure and sequence have achieved remarkable success in protein-protein interface prediction. However, extending these methods to protein-peptide interactions remains challenging due to the inherent conformational flexibility of peptides and the limited availability of structural data that hinder direct training of structure-aware models. To address these limitations, we introduce GeoPep, a novel framework for peptide binding site prediction that leverages transfer learning from ESM3, a multimodal protein foundation model. GeoPep fine-tunes ESM3's rich pre-learned representations from protein-protein binding to address the limited availability of protein-peptide binding data. The fine-tuned model is further integrated with a parameter-efficient neural network architecture capable of learning complex patterns from sparse data. Furthermore, the model is trained using distance-based loss functions that exploit 3D structural information to enhance binding site prediction. Comprehensive evaluations demonstrate that GeoPep significantly outperforms existing methods in protein-peptide binding site prediction by effectively capturing sparse and heterogeneous binding patterns.
Align-KD: Distilling Cross-Modal Alignment Knowledge for Mobile Vision-Language Model
Dec 02, 2024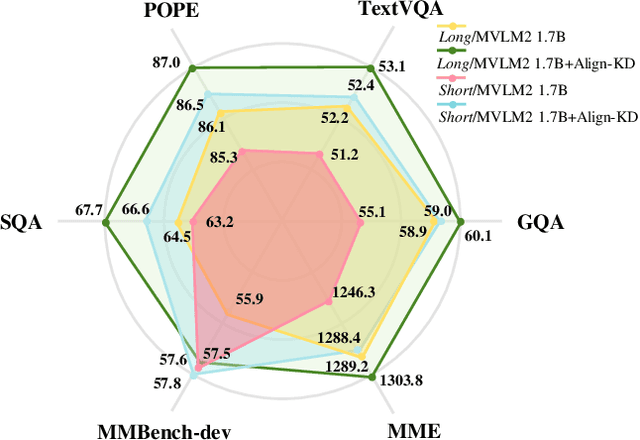
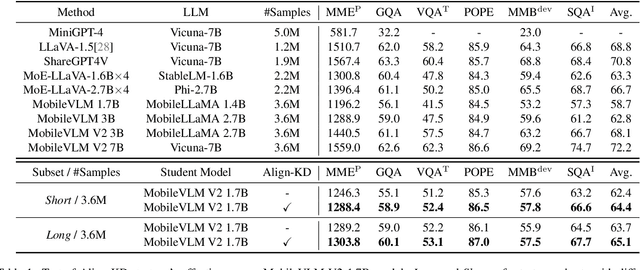
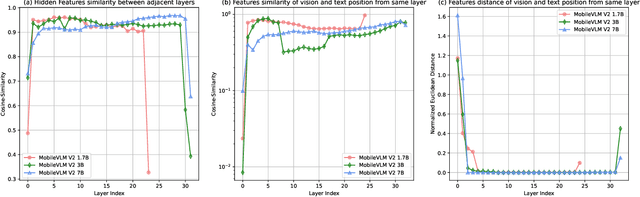
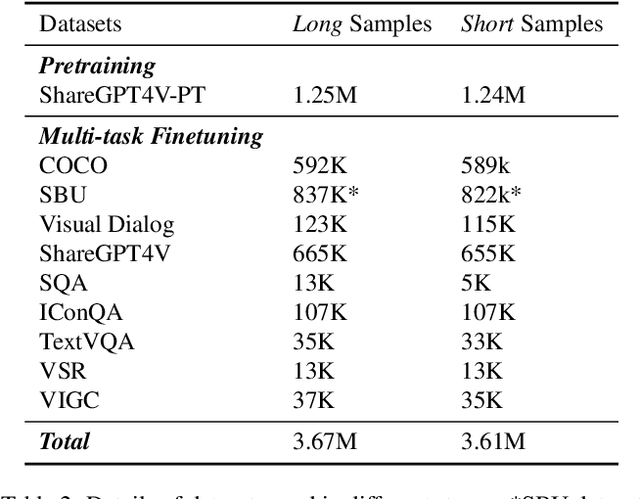
Vision-Language Models (VLMs) bring powerful understanding and reasoning capabilities to multimodal tasks. Meanwhile, the great need for capable aritificial intelligence on mobile devices also arises, such as the AI assistant software. Some efforts try to migrate VLMs to edge devices to expand their application scope. Simplifying the model structure is a common method, but as the model shrinks, the trade-off between performance and size becomes more and more difficult. Knowledge distillation (KD) can help models improve comprehensive capabilities without increasing size or data volume. However, most of the existing large model distillation techniques only consider applications on single-modal LLMs, or only use teachers to create new data environments for students. None of these methods take into account the distillation of the most important cross-modal alignment knowledge in VLMs. We propose a method called Align-KD to guide the student model to learn the cross-modal matching that occurs at the shallow layer. The teacher also helps student learn the projection of vision token into text embedding space based on the focus of text. Under the guidance of Align-KD, the 1.7B MobileVLM V2 model can learn rich knowledge from the 7B teacher model with light design of training loss, and achieve an average score improvement of 2.0 across 6 benchmarks under two training subsets respectively. Code is available at: https://github.com/fqhank/Align-KD.
Full-Stage Pseudo Label Quality Enhancement for Weakly-supervised Temporal Action Localization
Jul 12, 2024Weakly-supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos using only video-level supervision. Latest WSTAL methods introduce pseudo label learning framework to bridge the gap between classification-based training and inferencing targets at localization, and achieve cutting-edge results. In these frameworks, a classification-based model is used to generate pseudo labels for a regression-based student model to learn from. However, the quality of pseudo labels in the framework, which is a key factor to the final result, is not carefully studied. In this paper, we propose a set of simple yet efficient pseudo label quality enhancement mechanisms to build our FuSTAL framework. FuSTAL enhances pseudo label quality at three stages: cross-video contrastive learning at proposal Generation-Stage, prior-based filtering at proposal Selection-Stage and EMA-based distillation at Training-Stage. These designs enhance pseudo label quality at different stages in the framework, and help produce more informative, less false and smoother action proposals. With the help of these comprehensive designs at all stages, FuSTAL achieves an average mAP of 50.8% on THUMOS'14, outperforming the previous best method by 1.2%, and becomes the first method to reach the milestone of 50%.
VCC-INFUSE: Towards Accurate and Efficient Selection of Unlabeled Examples in Semi-supervised Learning
Apr 18, 2024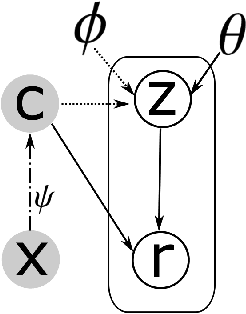

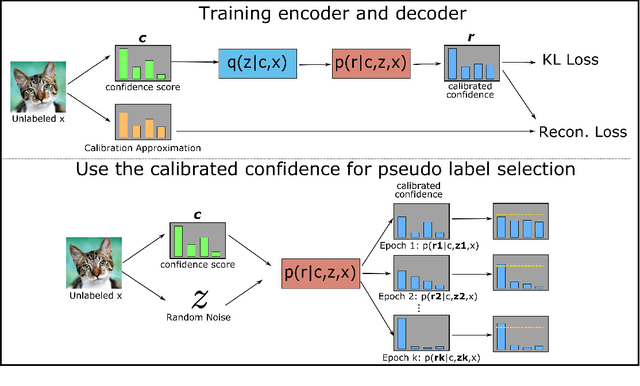

Despite the progress of Semi-supervised Learning (SSL), existing methods fail to utilize unlabeled data effectively and efficiently. Many pseudo-label-based methods select unlabeled examples based on inaccurate confidence scores from the classifier. Most prior work also uses all available unlabeled data without pruning, making it difficult to handle large amounts of unlabeled data. To address these issues, we propose two methods: Variational Confidence Calibration (VCC) and Influence-Function-based Unlabeled Sample Elimination (INFUSE). VCC is an universal plugin for SSL confidence calibration, using a variational autoencoder to select more accurate pseudo labels based on three types of consistency scores. INFUSE is a data pruning method that constructs a core dataset of unlabeled examples under SSL. Our methods are effective in multiple datasets and settings, reducing classification errors rates and saving training time. Together, VCC-INFUSE reduces the error rate of FlexMatch on the CIFAR-100 dataset by 1.08% while saving nearly half of the training time.
Target specific peptide design using latent space approximate trajectory collector
Feb 02, 2023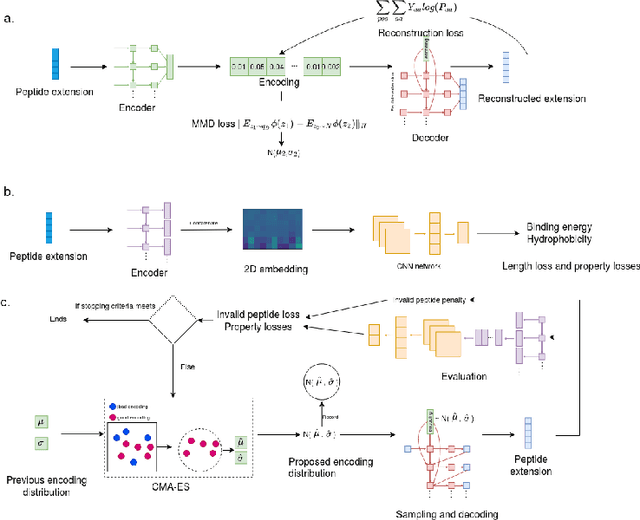

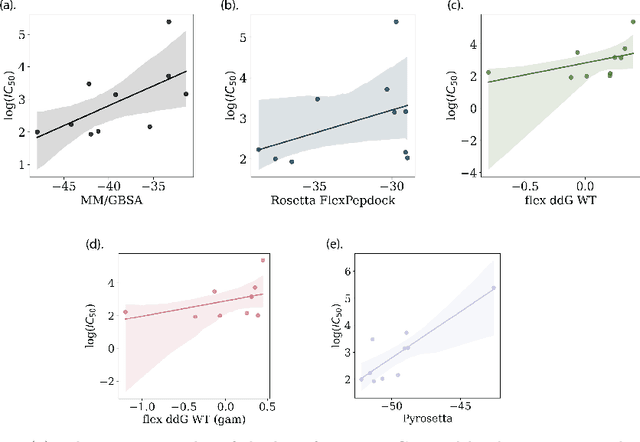
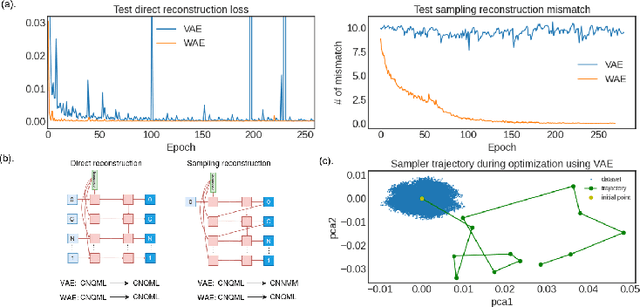
Despite the prevalence and many successes of deep learning applications in de novo molecular design, the problem of peptide generation targeting specific proteins remains unsolved. A main barrier for this is the scarcity of the high-quality training data. To tackle the issue, we propose a novel machine learning based peptide design architecture, called Latent Space Approximate Trajectory Collector (LSATC). It consists of a series of samplers on an optimization trajectory on a highly non-convex energy landscape that approximates the distributions of peptides with desired properties in a latent space. The process involves little human intervention and can be implemented in an end-to-end manner. We demonstrate the model by the design of peptide extensions targeting Beta-catenin, a key nuclear effector protein involved in canonical Wnt signalling. When compared with a random sampler, LSATC can sample peptides with $36\%$ lower binding scores in a $16$ times smaller interquartile range (IQR) and $284\%$ less hydrophobicity with a $1.4$ times smaller IQR. LSATC also largely outperforms other common generative models. Finally, we utilized a clustering algorithm to select 4 peptides from the 100 LSATC designed peptides for experimental validation. The result confirms that all the four peptides extended by LSATC show improved Beta-catenin binding by at least $20.0\%$, and two of the peptides show a $3$ fold increase in binding affinity as compared to the base peptide.
Efficient Meta-Learning for Continual Learning with Taylor Expansion Approximation
Oct 03, 2022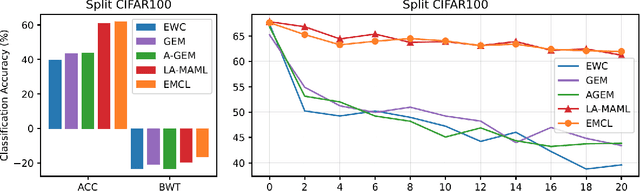
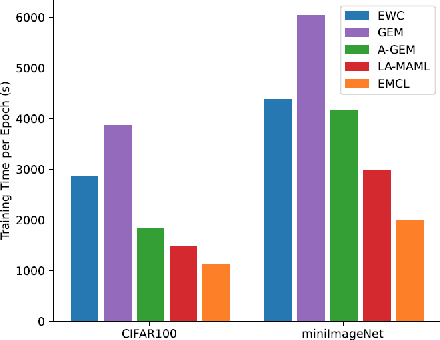
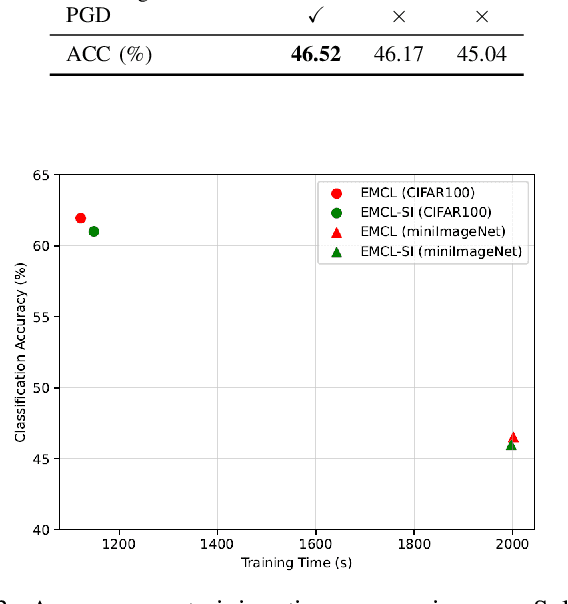

Continual learning aims to alleviate catastrophic forgetting when handling consecutive tasks under non-stationary distributions. Gradient-based meta-learning algorithms have shown the capability to implicitly solve the transfer-interference trade-off problem between different examples. However, they still suffer from the catastrophic forgetting problem in the setting of continual learning, since the past data of previous tasks are no longer available. In this work, we propose a novel efficient meta-learning algorithm for solving the online continual learning problem, where the regularization terms and learning rates are adapted to the Taylor approximation of the parameter's importance to mitigate forgetting. The proposed method expresses the gradient of the meta-loss in closed-form and thus avoid computing second-order derivative which is computationally inhibitable. We also use Proximal Gradient Descent to further improve computational efficiency and accuracy. Experiments on diverse benchmarks show that our method achieves better or on-par performance and much higher efficiency compared to the state-of-the-art approaches.
Unsupervised Domain Adaptation with Histogram-gated Image Translation for Delayered IC Image Analysis
Sep 27, 2022
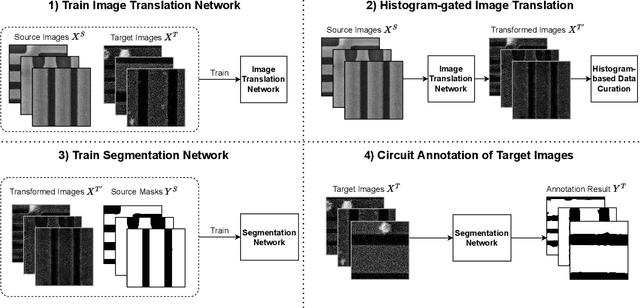


Deep learning has achieved great success in the challenging circuit annotation task by employing Convolutional Neural Networks (CNN) for the segmentation of circuit structures. The deep learning approaches require a large amount of manually annotated training data to achieve a good performance, which could cause a degradation in performance if a deep learning model trained on a given dataset is applied to a different dataset. This is commonly known as the domain shift problem for circuit annotation, which stems from the possibly large variations in distribution across different image datasets. The different image datasets could be obtained from different devices or different layers within a single device. To address the domain shift problem, we propose Histogram-gated Image Translation (HGIT), an unsupervised domain adaptation framework which transforms images from a given source dataset to the domain of a target dataset, and utilize the transformed images for training a segmentation network. Specifically, our HGIT performs generative adversarial network (GAN)-based image translation and utilizes histogram statistics for data curation. Experiments were conducted on a single labeled source dataset adapted to three different target datasets (without labels for training) and the segmentation performance was evaluated for each target dataset. We have demonstrated that our method achieves the best performance compared to the reported domain adaptation techniques, and is also reasonably close to the fully supervised benchmark.
Regularizing Deep Neural Networks with Stochastic Estimators of Hessian Trace
Aug 11, 2022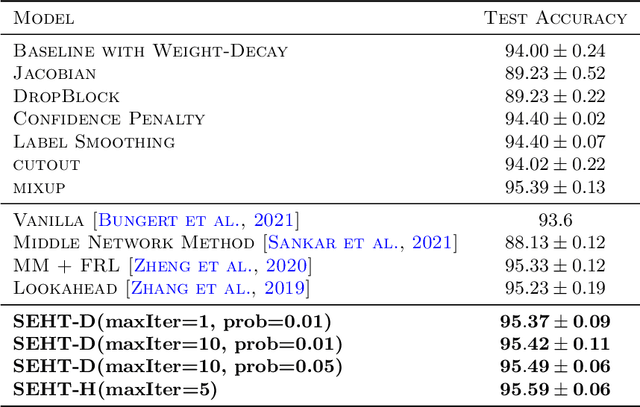
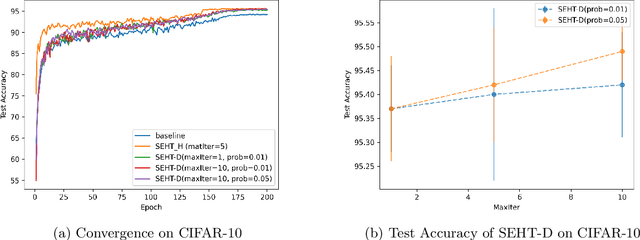
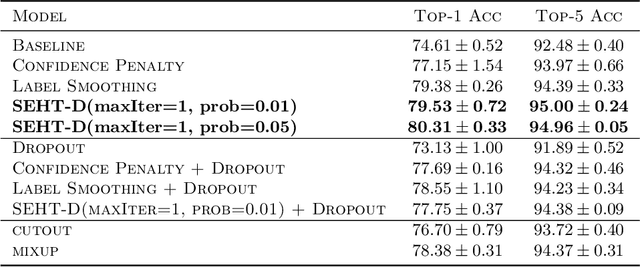

In this paper we develop a novel regularization method for deep neural networks by penalizing the trace of Hessian. This regularizer is motivated by a recent guarantee bound of the generalization error. Hutchinson method is a classical unbiased estimator for the trace of a matrix, but it is very time-consuming on deep learning models. Hence a dropout scheme is proposed to efficiently implements the Hutchinson method. Then we discuss a connection to linear stability of a nonlinear dynamical system and flat/sharp minima. Experiments demonstrate that our method outperforms existing regularizers and data augmentation methods, such as Jacobian, confidence penalty, and label smoothing, cutout and mixup.
Boosting Image Outpainting with Semantic Layout Prediction
Oct 18, 2021

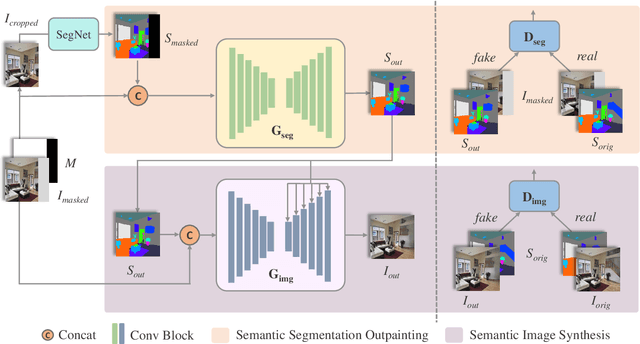

The objective of image outpainting is to extend image current border and generate new regions based on known ones. Previous methods adopt generative adversarial networks (GANs) to synthesize realistic images. However, the lack of explicit semantic representation leads to blurry and abnormal image pixels when the outpainting areas are complex and with various objects. In this work, we decompose the outpainting task into two stages. Firstly, we train a GAN to extend regions in semantic segmentation domain instead of image domain. Secondly, another GAN model is trained to synthesize real images based on the extended semantic layouts. The first model focuses on low frequent context such as sizes, classes and other semantic cues while the second model focuses on high frequent context like color and texture. By this design, our approach can handle semantic clues more easily and hence works better in complex scenarios. We evaluate our framework on various datasets and make quantitative and qualitative analysis. Experiments demonstrate that our method generates reasonable extended semantic layouts and images, outperforming state-of-the-art models.