 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Based Enhanced Oversampling Method for Imbalanced Classification
Apr 12, 2025This paper introduces a novel oversampling technique designed to improve classification performance on imbalanced datasets. The proposed method enhances the traditional SMOTE algorithm by incorporating convex combination and kernel-based weighting to generate synthetic samples that better represent the minority class. Through experiments on multiple real-world datasets, we demonstrate that the new technique outperforms existing methods in terms of F1-score, G-mean, and AUC, providing a robust solution for handling imbalanced datasets in classification tasks.
Document Type Classification using File Names
Oct 02, 2024Rapid document classification is critical in several time-sensitive applications like digital forensics and large-scale media classification. Traditional approaches that rely on heavy-duty deep learning models fall short due to high inference times over vast input datasets and computational resources associated with analyzing whole documents. In this paper, we present a method using lightweight supervised learning models, combined with a TF-IDF feature extraction-based tokenization method, to accurately and efficiently classify documents based solely on file names that substantially reduces inference time. This approach can distinguish ambiguous file names from the indicative file names through confidence scores and through using a negative class representing ambiguous file names. Our results indicate that file name classifiers can process more than 80% of the in-scope data with 96.7% accuracy when tested on a dataset with a large portion of out-of-scope data with respect to the training dataset while being 442.43x faster than more complex models such as DiT. Our method offers a crucial solution for efficiently processing vast datasets in critical scenarios, enabling fast, more reliable document classification.
DeliLaw: A Chinese Legal Counselling System Based on a Large Language Model
Aug 01, 2024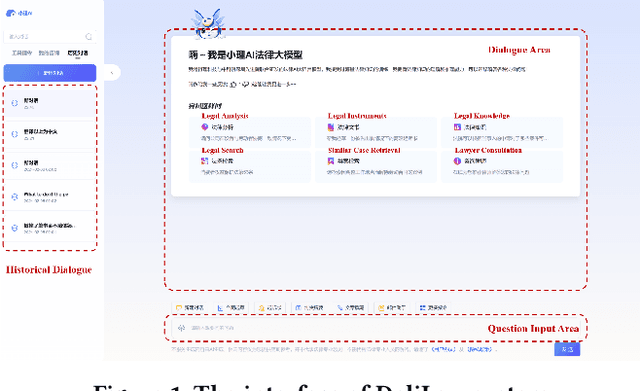

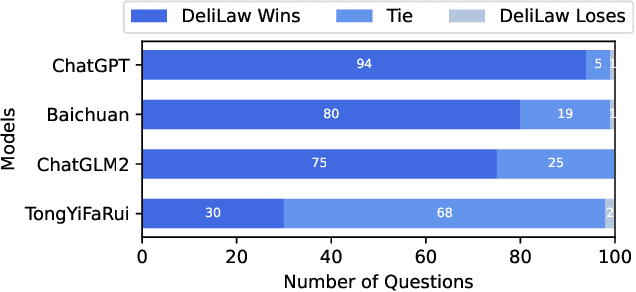
Traditional legal retrieval systems designed to retrieve legal documents, statutes, precedents, and other legal information are unable to give satisfactory answers due to lack of semantic understanding of specific questions. Large Language Models (LLMs) have achieved excellent results in a variety of natural language processing tasks, which inspired us that we train a LLM in the legal domain to help legal retrieval. However, in the Chinese legal domain, due to the complexity of legal questions and the rigour of legal articles, there is no legal large model with satisfactory practical application yet. In this paper, we present DeliLaw, a Chinese legal counselling system based on a large language model. DeliLaw integrates a legal retrieval module and a case retrieval module to overcome the model hallucination. Users can consult professional legal questions, search for legal articles and relevant judgement cases, etc. on the DeliLaw system in a dialogue mode. In addition, DeliLaw supports the use of English for counseling. we provide the address of the system: https://data.delilegal.com/lawQuestion.
Generating Hard-Negative Out-of-Scope Data with ChatGPT for Intent Classification
Mar 08, 2024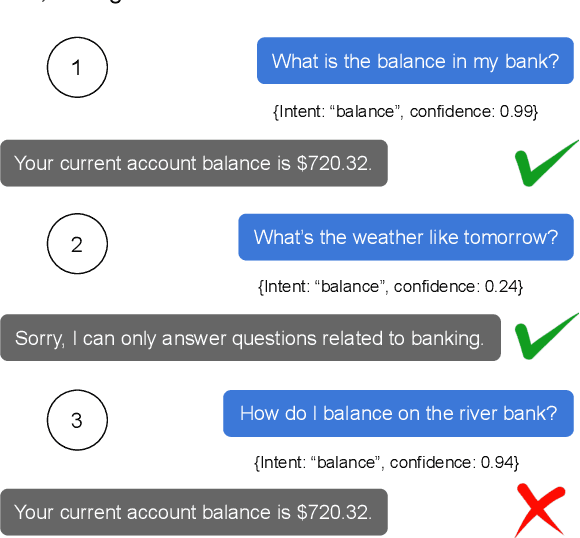
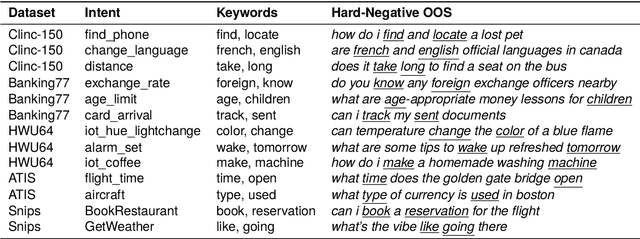
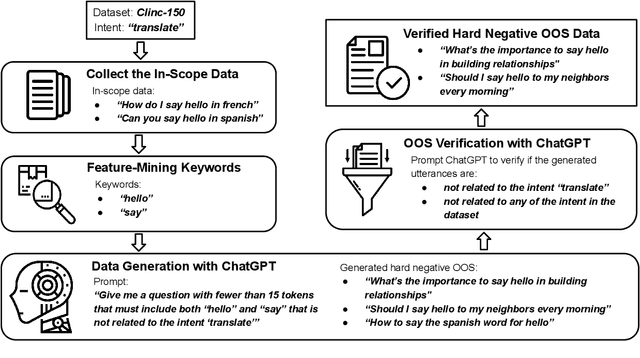
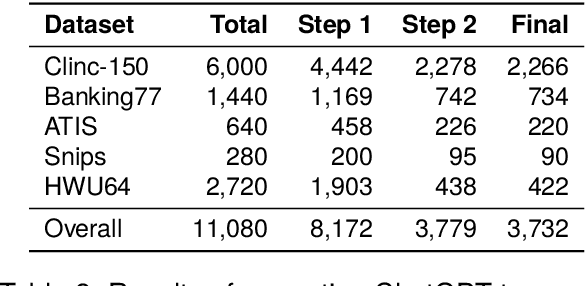
Intent classifiers must be able to distinguish when a user's utterance does not belong to any supported intent to avoid producing incorrect and unrelated system responses. Although out-of-scope (OOS) detection for intent classifiers has been studied, previous work has not yet studied changes in classifier performance against hard-negative out-of-scope utterances (i.e., inputs that share common features with in-scope data, but are actually out-of-scope). We present an automated technique to generate hard-negative OOS data using ChatGPT. We use our technique to build five new hard-negative OOS datasets, and evaluate each against three benchmark intent classifiers. We show that classifiers struggle to correctly identify hard-negative OOS utterances more than general OOS utterances. Finally, we show that incorporating hard-negative OOS data for training improves model robustness when detecting hard-negative OOS data and general OOS data. Our technique, datasets, and evaluation address an important void in the field, offering a straightforward and inexpensive way to collect hard-negative OOS data and improve intent classifiers' robustness.
Feature Affinity Assisted Knowledge Distillation and Quantization of Deep Neural Networks on Label-Free Data
Feb 10, 2023



In this paper, we propose a feature affinity (FA) assisted knowledge distillation (KD) method to improve quantization-aware training of deep neural networks (DNN). The FA loss on intermediate feature maps of DNNs plays the role of teaching middle steps of a solution to a student instead of only giving final answers in the conventional KD where the loss acts on the network logits at the output level. Combining logit loss and FA loss, we found that the quantized student network receives stronger supervision than from the labeled ground-truth data. The resulting FAQD is capable of compressing model on label-free data, which brings immediate practical benefits as pre-trained teacher models are readily available and unlabeled data are abundant. In contrast, data labeling is often laborious and expensive. Finally, we propose a fast feature affinity (FFA) loss that accurately approximates FA loss with a lower order of computational complexity, which helps speed up training for high resolution image input.
Channel Pruning In Quantization-aware Training: An Adaptive Projection-gradient Descent-shrinkage-splitting Method
Apr 09, 2022
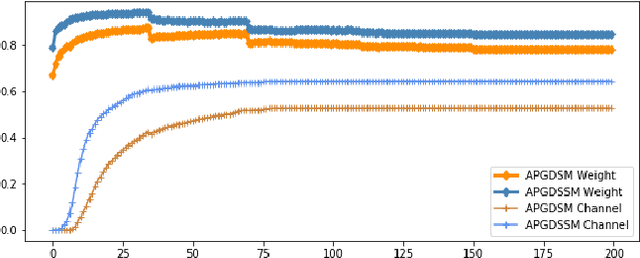
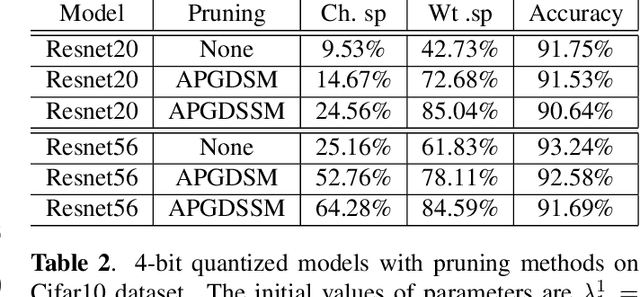
We propose an adaptive projection-gradient descent-shrinkage-splitting method (APGDSSM) to integrate penalty based channel pruning into quantization-aware training (QAT). APGDSSM concurrently searches weights in both the quantized subspace and the sparse subspace. APGDSSM uses shrinkage operator and a splitting technique to create sparse weights, as well as the Group Lasso penalty to push the weight sparsity into channel sparsity. In addition, we propose a novel complementary transformed l1 penalty to stabilize the training for extreme compression.
An integrated recurrent neural network and regression model with spatial and climatic couplings for vector-borne disease dynamics
Jan 23, 2022
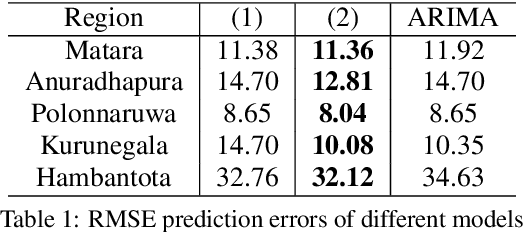


We developed an integrated recurrent neural network and nonlinear regression spatio-temporal model for vector-borne disease evolution. We take into account climate data and seasonality as external factors that correlate with disease transmitting insects (e.g. flies), also spill-over infections from neighboring regions surrounding a region of interest. The climate data is encoded to the model through a quadratic embedding scheme motivated by recommendation systems. The neighboring regions' influence is modeled by a long short-term memory neural network. The integrated model is trained by stochastic gradient descent and tested on leish-maniasis data in Sri Lanka from 2013-2018 where infection outbreaks occurred. Our model outperformed ARIMA models across a number of regions with high infections, and an associated ablation study renders support to our modeling hypothesis and ideas.
DPVI: A Dynamic-Weight Particle-Based Variational Inference Framework
Dec 02, 2021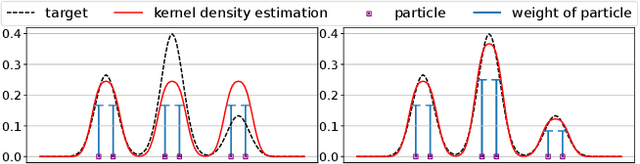



The recently developed Particle-based Variational Inference (ParVI) methods drive the empirical distribution of a set of \emph{fixed-weight} particles towards a given target distribution $\pi$ by iteratively updating particles' positions. However, the fixed weight restriction greatly confines the empirical distribution's approximation ability, especially when the particle number is limited. In this paper, we propose to dynamically adjust particles' weights according to a Fisher-Rao reaction flow. We develop a general Dynamic-weight Particle-based Variational Inference (DPVI) framework according to a novel continuous composite flow, which evolves the positions and weights of particles simultaneously. We show that the mean-field limit of our composite flow is actually a Wasserstein-Fisher-Rao gradient flow of certain dissimilarity functional $\mathcal{F}$, which leads to a faster decrease of $\mathcal{F}$ than the Wasserstein gradient flow underlying existing fixed-weight ParVIs. By using different finite-particle approximations in our general framework, we derive several efficient DPVI algorithms. The empirical results demonstrate the superiority of our derived DPVI algorithms over their fixed-weight counterparts.
A Deep Learning Approach for Macroscopic Energy Consumption Prediction with Microscopic Quality for Electric Vehicles
Nov 25, 2021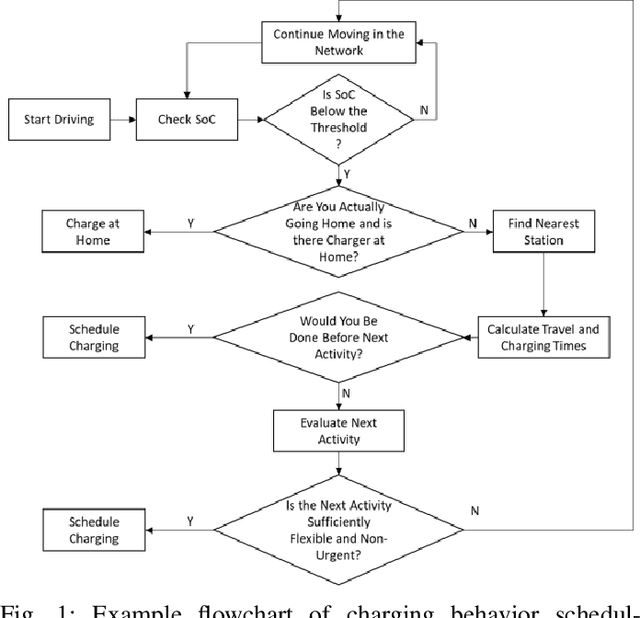
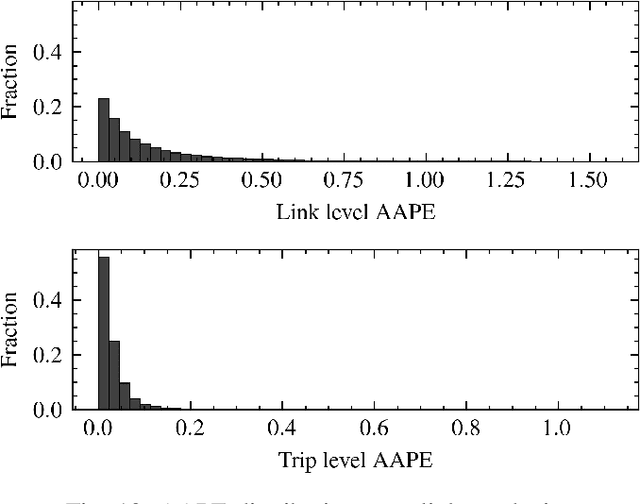
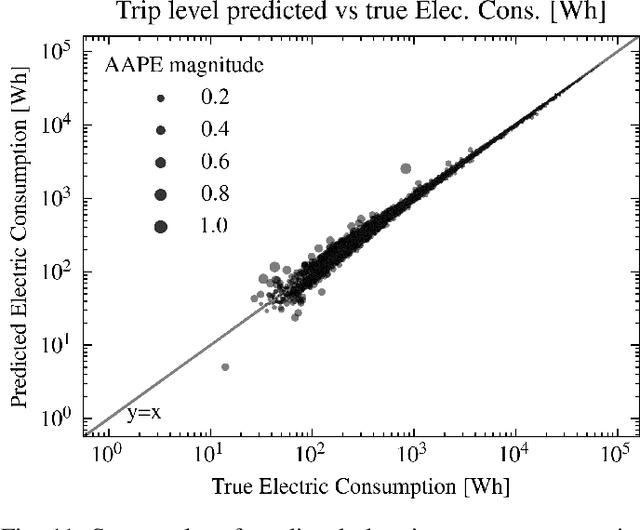
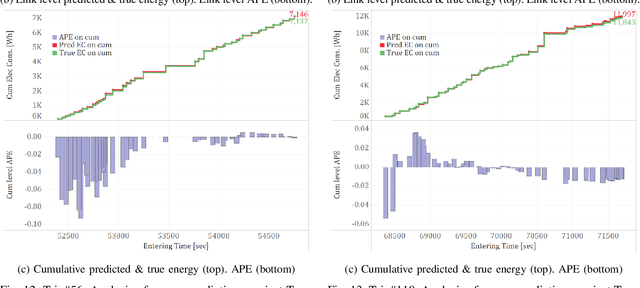
This paper presents a machine learning approach to model the electric consumption of electric vehicles at macroscopic level, i.e., in the absence of a speed profile, while preserving microscopic level accuracy. For this work, we leveraged a high-performance, agent-based transportation tool to model trips that occur in the Greater Chicago region under various scenario changes, along with physics-based modeling and simulation tools to provide high-fidelity energy consumption values. The generated results constitute a very large dataset of vehicle-route energy outcomes that capture variability in vehicle and routing setting, and in which high-fidelity time series of vehicle speed dynamics is masked. We show that although all internal dynamics that affect energy consumption are masked, it is possible to learn aggregate-level energy consumption values quite accurately with a deep learning approach. When large-scale data is available, and with carefully tailored feature engineering, a well-designed model can overcome and retrieve latent information. This model has been deployed and integrated within POLARIS Transportation System Simulation Tool to support real-time behavioral transportation models for individual charging decision-making, and rerouting of electric vehicles.
A Real-Time Energy and Cost Efficient Vehicle Route Assignment Neural Recommender System
Oct 21, 2021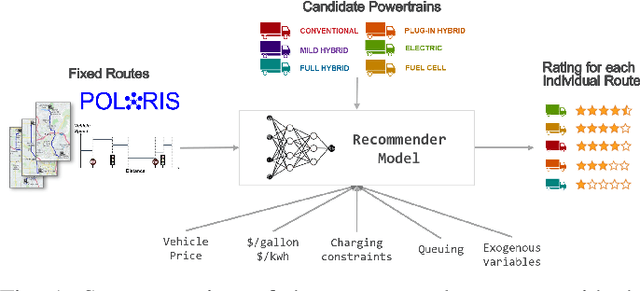
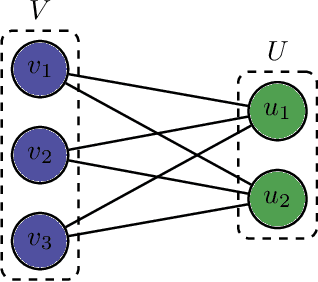
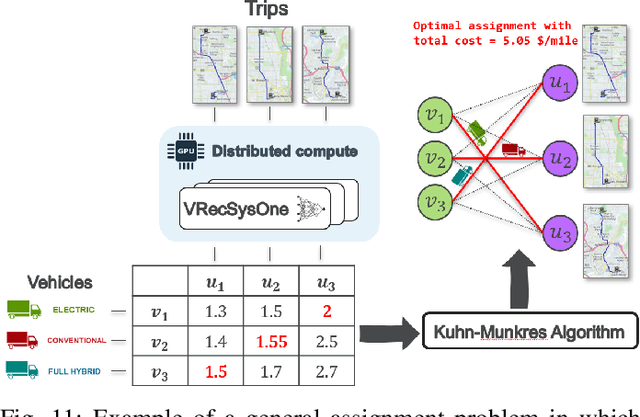
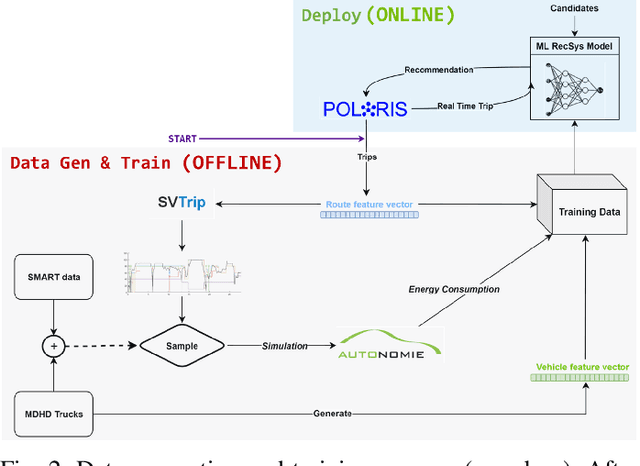
This paper presents a neural network recommender system algorithm for assigning vehicles to routes based on energy and cost criteria. In this work, we applied this new approach to efficiently identify the most cost-effective medium and heavy duty truck (MDHDT) powertrain technology, from a total cost of ownership (TCO) perspective, for given trips. We employ a machine learning based approach to efficiently estimate the energy consumption of various candidate vehicles over given routes, defined as sequences of links (road segments), with little information known about internal dynamics, i.e using high level macroscopic route information. A complete recommendation logic is then developed to allow for real-time optimum assignment for each route, subject to the operational constraints of the fleet. We show how this framework can be used to (1) efficiently provide a single trip recommendation with a top-$k$ vehicles star ranking system, and (2) engage in more general assignment problems where $n$ vehicles need to be deployed over $m \leq n$ trips. This new assignment system has been deployed and integrated into the POLARIS Transportation System Simulation Tool for use in research conducted by the Department of Energy's Systems and Modeling for Accelerated Research in Transportation (SMART) Mobility Consortium