 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Errors in the Tobacco3482 Dataset
Dec 17, 2024



Tobacco3482 is a widely used document classification benchmark dataset. However, our manual inspection of the entire dataset uncovers widespread ontological issues, especially large amounts of annotation label problems in the dataset. We establish data label guidelines and find that 11.7% of the dataset is improperly annotated and should either have an unknown label or a corrected label, and 16.7% of samples in the dataset have multiple valid labels. We then analyze the mistakes of a top-performing model and find that 35% of the model's mistakes can be directly attributed to these label issues, highlighting the inherent problems with using a noisily labeled dataset as a benchmark. Supplementary material, including dataset annotations and code, is available at https://github.com/gordon-lim/tobacco3482-mistakes/.
Robust Testing for Deep Learning using Human Label Noise
Nov 29, 2024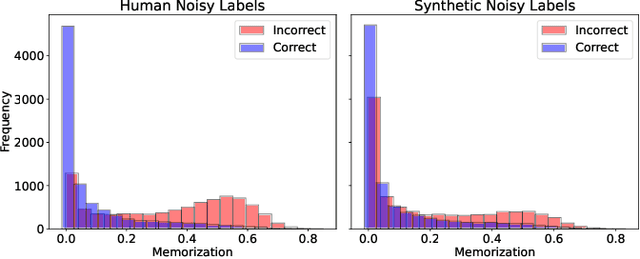
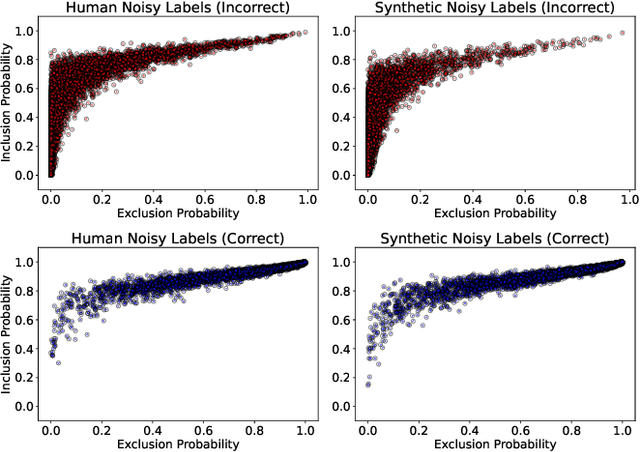
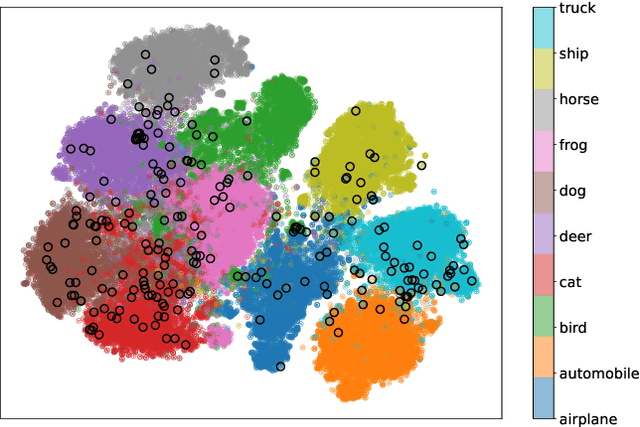

In deep learning (DL) systems, label noise in training datasets often degrades model performance, as models may learn incorrect patterns from mislabeled data. The area of Learning with Noisy Labels (LNL) has introduced methods to effectively train DL models in the presence of noisily-labeled datasets. Traditionally, these methods are tested using synthetic label noise, where ground truth labels are randomly (and automatically) flipped. However, recent findings highlight that models perform substantially worse under human label noise than synthetic label noise, indicating a need for more realistic test scenarios that reflect noise introduced due to imperfect human labeling. This underscores the need for generating realistic noisy labels that simulate human label noise, enabling rigorous testing of deep neural networks without the need to collect new human-labeled datasets. To address this gap, we present Cluster-Based Noise (CBN), a method for generating feature-dependent noise that simulates human-like label noise. Using insights from our case study of label memorization in the CIFAR-10N dataset, we design CBN to create more realistic tests for evaluating LNL methods. Our experiments demonstrate that current LNL methods perform worse when tested using CBN, highlighting its use as a rigorous approach to testing neural networks. Next, we propose Soft Neighbor Label Sampling (SNLS), a method designed to handle CBN, demonstrating its improvement over existing techniques in tackling this more challenging type of noise.
Document Type Classification using File Names
Oct 02, 2024Rapid document classification is critical in several time-sensitive applications like digital forensics and large-scale media classification. Traditional approaches that rely on heavy-duty deep learning models fall short due to high inference times over vast input datasets and computational resources associated with analyzing whole documents. In this paper, we present a method using lightweight supervised learning models, combined with a TF-IDF feature extraction-based tokenization method, to accurately and efficiently classify documents based solely on file names that substantially reduces inference time. This approach can distinguish ambiguous file names from the indicative file names through confidence scores and through using a negative class representing ambiguous file names. Our results indicate that file name classifiers can process more than 80% of the in-scope data with 96.7% accuracy when tested on a dataset with a large portion of out-of-scope data with respect to the training dataset while being 442.43x faster than more complex models such as DiT. Our method offers a crucial solution for efficiently processing vast datasets in critical scenarios, enabling fast, more reliable document classification.
Generating Hard-Negative Out-of-Scope Data with ChatGPT for Intent Classification
Mar 08, 2024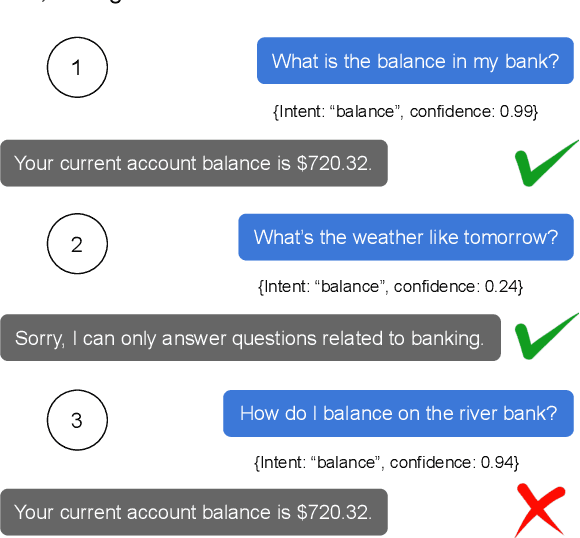
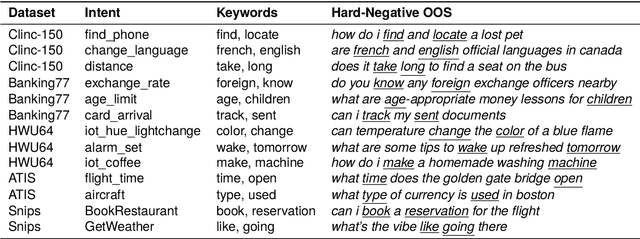
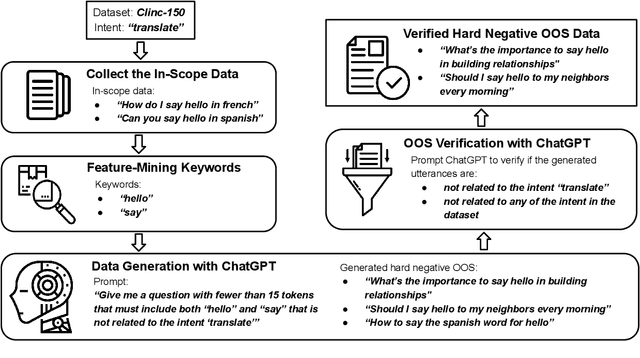
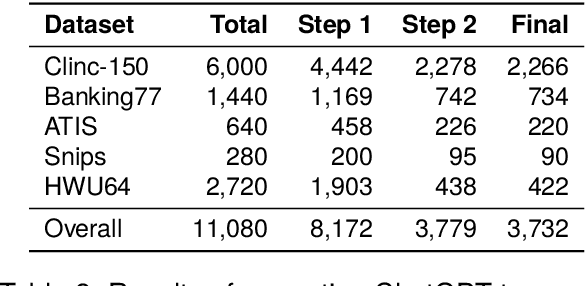
Intent classifiers must be able to distinguish when a user's utterance does not belong to any supported intent to avoid producing incorrect and unrelated system responses. Although out-of-scope (OOS) detection for intent classifiers has been studied, previous work has not yet studied changes in classifier performance against hard-negative out-of-scope utterances (i.e., inputs that share common features with in-scope data, but are actually out-of-scope). We present an automated technique to generate hard-negative OOS data using ChatGPT. We use our technique to build five new hard-negative OOS datasets, and evaluate each against three benchmark intent classifiers. We show that classifiers struggle to correctly identify hard-negative OOS utterances more than general OOS utterances. Finally, we show that incorporating hard-negative OOS data for training improves model robustness when detecting hard-negative OOS data and general OOS data. Our technique, datasets, and evaluation address an important void in the field, offering a straightforward and inexpensive way to collect hard-negative OOS data and improve intent classifiers' robustness.
On Evaluation of Document Classification using RVL-CDIP
Jun 21, 2023



The RVL-CDIP benchmark is widely used for measuring performance on the task of document classification. Despite its widespread use, we reveal several undesirable characteristics of the RVL-CDIP benchmark. These include (1) substantial amounts of label noise, which we estimate to be 8.1% (ranging between 1.6% to 16.9% per document category); (2) presence of many ambiguous or multi-label documents; (3) a large overlap between test and train splits, which can inflate model performance metrics; and (4) presence of sensitive personally-identifiable information like US Social Security numbers (SSNs). We argue that there is a risk in using RVL-CDIP for benchmarking document classifiers, as its limited scope, presence of errors (state-of-the-art models now achieve accuracy error rates that are within our estimated label error rate), and lack of diversity make it less than ideal for benchmarking. We further advocate for the creation of a new document classification benchmark, and provide recommendations for what characteristics such a resource should include.
ShabbyPages: A Reproducible Document Denoising and Binarization Dataset
Mar 17, 2023



Document denoising and binarization are fundamental problems in the document processing space, but current datasets are often too small and lack sufficient complexity to effectively train and benchmark modern data-driven machine learning models. To fill this gap, we introduce ShabbyPages, a new document image dataset designed for training and benchmarking document denoisers and binarizers. ShabbyPages contains over 6,000 clean "born digital" images with synthetically-noised counterparts ("shabby pages") that were augmented using the Augraphy document augmentation tool to appear as if they have been printed and faxed, photocopied, or otherwise altered through physical processes. In this paper, we discuss the creation process of ShabbyPages and demonstrate the utility of ShabbyPages by training convolutional denoisers which remove real noise features with a high degree of human-perceptible fidelity, establishing baseline performance for a new ShabbyPages benchmark.
Evaluating Out-of-Distribution Performance on Document Image Classifiers
Oct 14, 2022


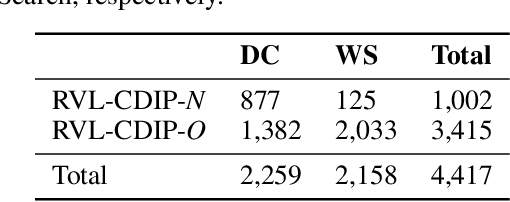
The ability of a document classifier to handle inputs that are drawn from a distribution different from the training distribution is crucial for robust deployment and generalizability. The RVL-CDIP corpus is the de facto standard benchmark for document classification, yet to our knowledge all studies that use this corpus do not include evaluation on out-of-distribution documents. In this paper, we curate and release a new out-of-distribution benchmark for evaluating out-of-distribution performance for document classifiers. Our new out-of-distribution benchmark consists of two types of documents: those that are not part of any of the 16 in-domain RVL-CDIP categories (RVL-CDIP-O), and those that are one of the 16 in-domain categories yet are drawn from a distribution different from that of the original RVL-CDIP dataset (RVL-CDIP-N). While prior work on document classification for in-domain RVL-CDIP documents reports high accuracy scores, we find that these models exhibit accuracy drops of between roughly 15-30% on our new out-of-domain RVL-CDIP-N benchmark, and further struggle to distinguish between in-domain RVL-CDIP-N and out-of-domain RVL-CDIP-O inputs. Our new benchmark provides researchers with a valuable new resource for analyzing out-of-distribution performance on document classifiers. Our new out-of-distribution data can be found at https://tinyurl.com/4he6my23.
Augraphy: A Data Augmentation Library for Document Images
Aug 30, 2022

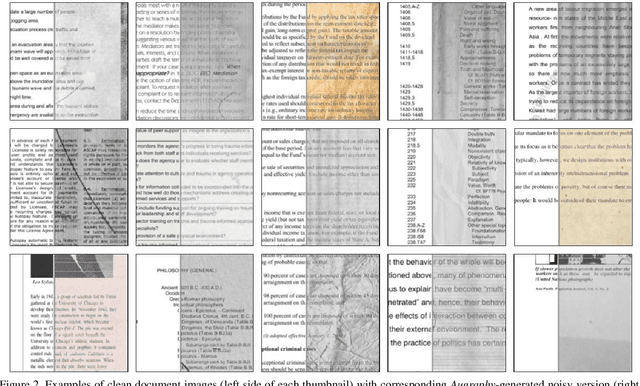
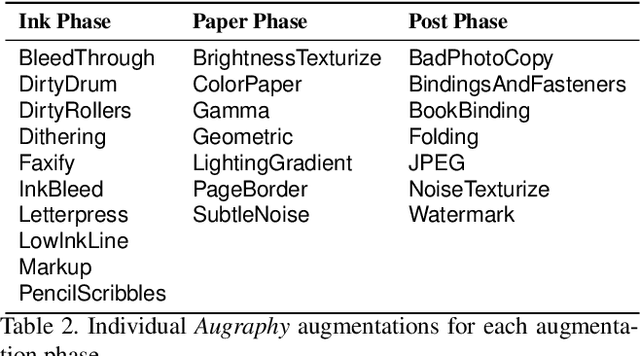
This paper introduces Augraphy, a Python package geared toward realistic data augmentation strategies for document images. Augraphy uses many different augmentation strategies to produce augmented versions of clean document images that appear as if they have been distorted from standard office operations, such as printing, scanning, and faxing through old or dirty machines, degradation of ink over time, and handwritten markings. Augraphy can be used both as a data augmentation tool for (1) producing diverse training data for tasks such as document de-noising, and (2) generating challenging test data for evaluating model robustness on document image modeling tasks. This paper provides an overview of Augraphy and presents three example robustness testing use-cases of Augraphy.
A Survey of Intent Classification and Slot-Filling Datasets for Task-Oriented Dialog
Jul 26, 2022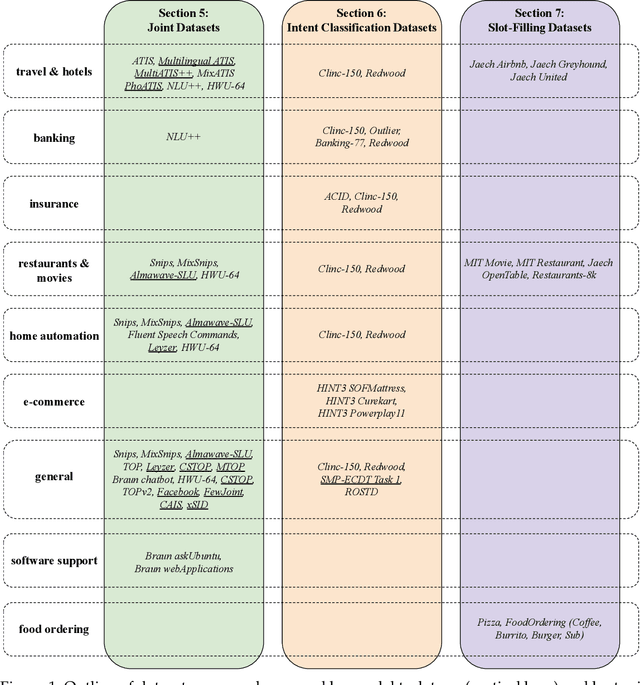

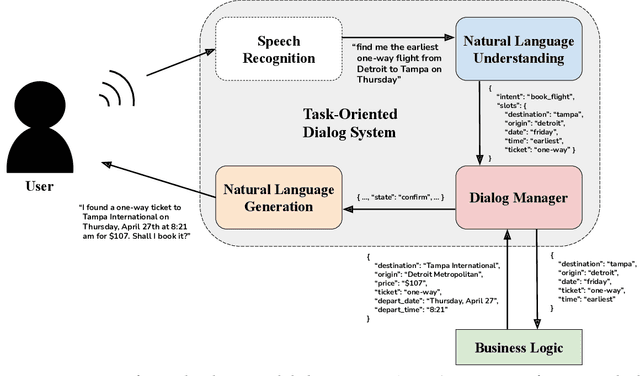

Interest in dialog systems has grown substantially in the past decade. By extension, so too has interest in developing and improving intent classification and slot-filling models, which are two components that are commonly used in task-oriented dialog systems. Moreover, good evaluation benchmarks are important in helping to compare and analyze systems that incorporate such models. Unfortunately, much of the literature in the field is limited to analysis of relatively few benchmark datasets. In an effort to promote more robust analyses of task-oriented dialog systems, we have conducted a survey of publicly available datasets for the tasks of intent classification and slot-filling. We catalog the important characteristics of each dataset, and offer discussion on the applicability, strengths, and weaknesses of each. Our goal is that this survey aids in increasing the accessibility of these datasets, which we hope will enable their use in future evaluations of intent classification and slot-filling models for task-oriented dialog systems.
Redwood: Using Collision Detection to Grow a Large-Scale Intent Classification Dataset
Apr 12, 2022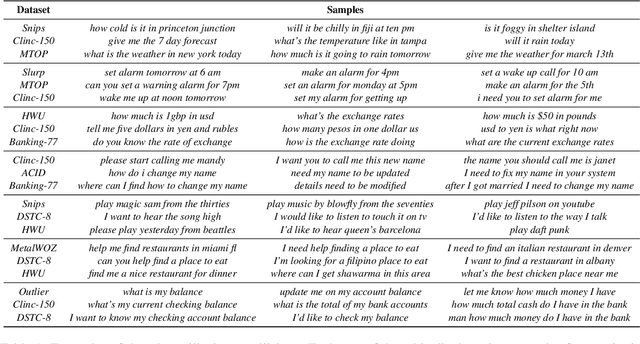
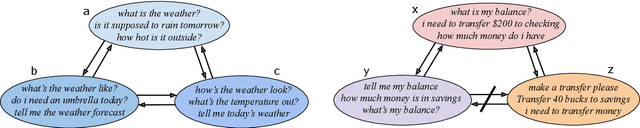


Dialog systems must be capable of incorporating new skills via updates over time in order to reflect new use cases or deployment scenarios. Similarly, developers of such ML-driven systems need to be able to add new training data to an already-existing dataset to support these new skills. In intent classification systems, problems can arise if training data for a new skill's intent overlaps semantically with an already-existing intent. We call such cases collisions. This paper introduces the task of intent collision detection between multiple datasets for the purposes of growing a system's skillset. We introduce several methods for detecting collisions, and evaluate our methods on real datasets that exhibit collisions. To highlight the need for intent collision detection, we show that model performance suffers if new data is added in such a way that does not arbitrate colliding intents. Finally, we use collision detection to construct and benchmark a new dataset, Redwood, which is composed of 451 ntent categories from 13 original intent classification datasets, making it the largest publicly available intent classification benchmark.