 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShabbyPages: A Reproducible Document Denoising and Binarization Dataset
Mar 17, 2023



Document denoising and binarization are fundamental problems in the document processing space, but current datasets are often too small and lack sufficient complexity to effectively train and benchmark modern data-driven machine learning models. To fill this gap, we introduce ShabbyPages, a new document image dataset designed for training and benchmarking document denoisers and binarizers. ShabbyPages contains over 6,000 clean "born digital" images with synthetically-noised counterparts ("shabby pages") that were augmented using the Augraphy document augmentation tool to appear as if they have been printed and faxed, photocopied, or otherwise altered through physical processes. In this paper, we discuss the creation process of ShabbyPages and demonstrate the utility of ShabbyPages by training convolutional denoisers which remove real noise features with a high degree of human-perceptible fidelity, establishing baseline performance for a new ShabbyPages benchmark.
Augraphy: A Data Augmentation Library for Document Images
Aug 30, 2022

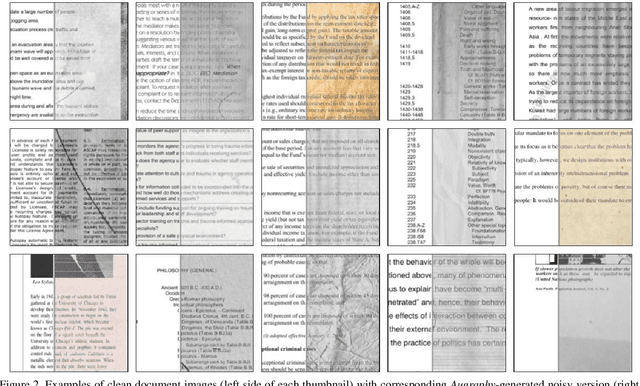
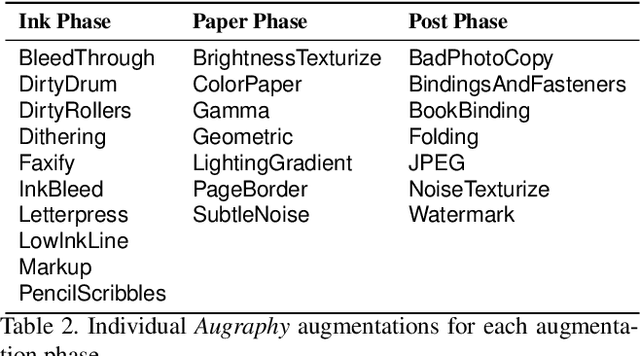
This paper introduces Augraphy, a Python package geared toward realistic data augmentation strategies for document images. Augraphy uses many different augmentation strategies to produce augmented versions of clean document images that appear as if they have been distorted from standard office operations, such as printing, scanning, and faxing through old or dirty machines, degradation of ink over time, and handwritten markings. Augraphy can be used both as a data augmentation tool for (1) producing diverse training data for tasks such as document de-noising, and (2) generating challenging test data for evaluating model robustness on document image modeling tasks. This paper provides an overview of Augraphy and presents three example robustness testing use-cases of Augraphy.