 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedwood: Using Collision Detection to Grow a Large-Scale Intent Classification Dataset
Paper and Code
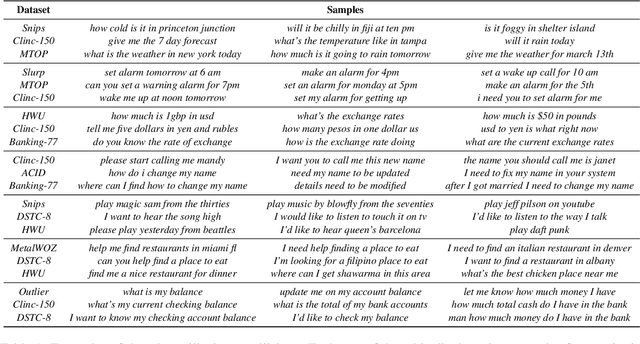
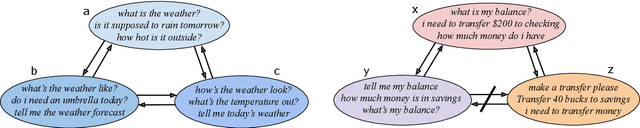


Dialog systems must be capable of incorporating new skills via updates over time in order to reflect new use cases or deployment scenarios. Similarly, developers of such ML-driven systems need to be able to add new training data to an already-existing dataset to support these new skills. In intent classification systems, problems can arise if training data for a new skill's intent overlaps semantically with an already-existing intent. We call such cases collisions. This paper introduces the task of intent collision detection between multiple datasets for the purposes of growing a system's skillset. We introduce several methods for detecting collisions, and evaluate our methods on real datasets that exhibit collisions. To highlight the need for intent collision detection, we show that model performance suffers if new data is added in such a way that does not arbitrate colliding intents. Finally, we use collision detection to construct and benchmark a new dataset, Redwood, which is composed of 451 ntent categories from 13 original intent classification datasets, making it the largest publicly available intent classification benchmark.