 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Intent Classification and Slot-Filling Datasets for Task-Oriented Dialog
Paper and Code
Jul 26, 2022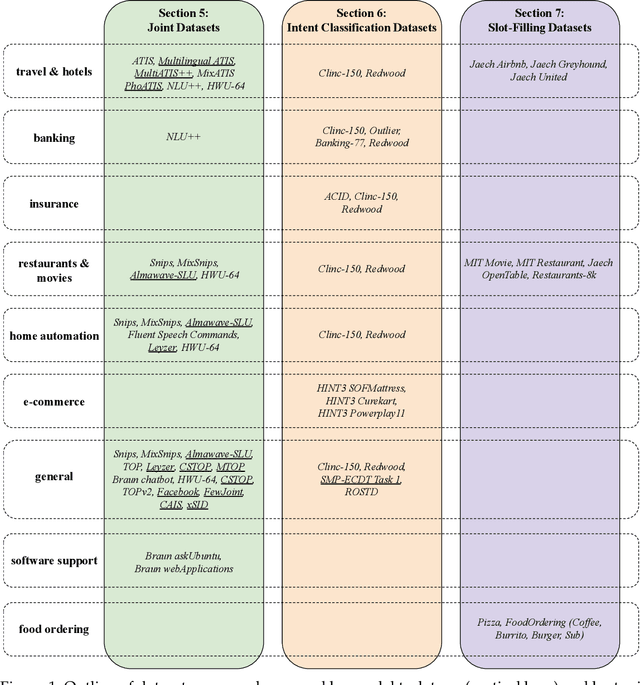

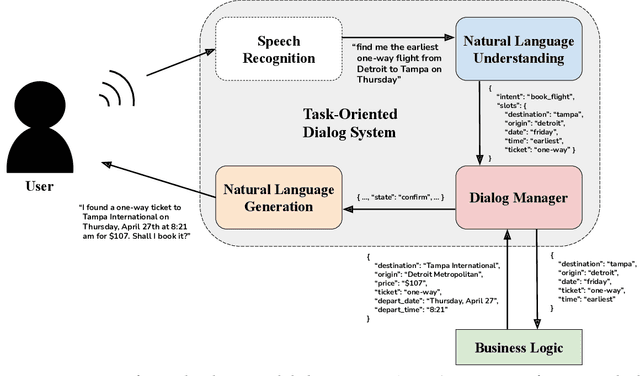

Interest in dialog systems has grown substantially in the past decade. By extension, so too has interest in developing and improving intent classification and slot-filling models, which are two components that are commonly used in task-oriented dialog systems. Moreover, good evaluation benchmarks are important in helping to compare and analyze systems that incorporate such models. Unfortunately, much of the literature in the field is limited to analysis of relatively few benchmark datasets. In an effort to promote more robust analyses of task-oriented dialog systems, we have conducted a survey of publicly available datasets for the tasks of intent classification and slot-filling. We catalog the important characteristics of each dataset, and offer discussion on the applicability, strengths, and weaknesses of each. Our goal is that this survey aids in increasing the accessibility of these datasets, which we hope will enable their use in future evaluations of intent classification and slot-filling models for task-oriented dialog systems.