 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal2Skill: Long-Horizon Manipulation with Adaptive Planning and Reflection
Apr 15, 2026Recent vision-language-action (VLA) systems have demonstrated strong capabilities in embodied manipulation. However, most existing VLA policies rely on limited observation windows and end-to-end action prediction, which makes them brittle in long-horizon, memory-dependent tasks with partial observability, occlusions, and multi-stage dependencies. Such tasks require not only precise visuomotor control, but also persistent memory, adaptive task decomposition, and explicit recovery from execution failures. To address these limitations, we propose a dual-system framework for long-horizon embodied manipulation. Our framework explicitly separates high-level semantic reasoning from low-level motor execution. A high-level planner, implemented as a VLM-based agentic module, maintains structured task memory and performs goal decomposition, outcome verification, and error-driven correction. A low-level executor, instantiated as a VLA-based visuomotor controller, carries out each sub-task through diffusion-based action generation conditioned on geometry-preserving filtered observations. Together, the two systems form a closed loop between planning and execution, enabling memory-aware reasoning, adaptive replanning, and robust online recovery. Experiments on representative RMBench tasks show that the proposed framework substantially outperforms representative baselines, achieving a 32.4% average success rate compared with 9.8% for the strongest baseline. Ablation studies further confirm the importance of structured memory and closed-loop recovery for long-horizon manipulation.
Advancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models
Jan 13, 2026Recent advances in world models have shown promise for modeling future dynamics of environmental states, enabling agents to reason and act without accessing real environments. Current methods mainly perform single-step or fixed-horizon rollouts, leaving their potential for complex task planning under-exploited. We propose Imagine-then-Plan (\texttt{ITP}), a unified framework for agent learning via lookahead imagination, where an agent's policy model interacts with the learned world model, yielding multi-step ``imagined'' trajectories. Since the imagination horizon may vary by tasks and stages, we introduce a novel adaptive lookahead mechanism by trading off the ultimate goal and task progress. The resulting imagined trajectories provide rich signals about future consequences, such as achieved progress and potential conflicts, which are fused with current observations, formulating a partially \textit{observable} and \textit{imaginable} Markov decision process to guide policy learning. We instantiate \texttt{ITP} with both training-free and reinforcement-trained variants. Extensive experiments across representative agent benchmarks demonstrate that \texttt{ITP} significantly outperforms competitive baselines. Further analyses validate that our adaptive lookahead largely enhances agents' reasoning capability, providing valuable insights into addressing broader, complex tasks.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Oct 23, 2025State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution
May 27, 2025
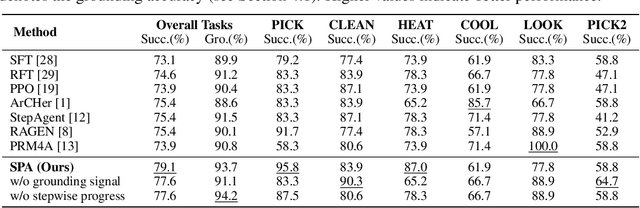
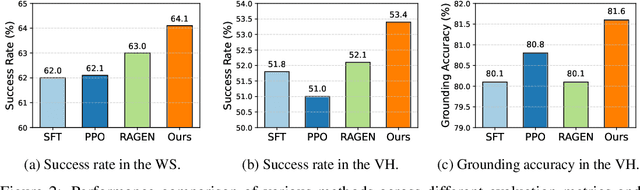
Reinforcement learning (RL) holds significant promise for training LLM agents to handle complex, goal-oriented tasks that require multi-step interactions with external environments. However, a critical challenge when applying RL to these agentic tasks arises from delayed rewards: feedback signals are typically available only after the entire task is completed. This makes it non-trivial to assign delayed rewards to earlier actions, providing insufficient guidance regarding environmental constraints and hindering agent training. In this work, we draw on the insight that the ultimate completion of a task emerges from the cumulative progress an agent makes across individual steps. We propose Stepwise Progress Attribution (SPA), a general reward redistribution framework that decomposes the final reward into stepwise contributions, each reflecting its incremental progress toward overall task completion. To achieve this, we train a progress estimator that accumulates stepwise contributions over a trajectory to match the task completion. During policy optimization, we combine the estimated per-step contribution with a grounding signal for actions executed in the environment as the fine-grained, intermediate reward for effective agent training. Extensive experiments on common agent benchmarks (including Webshop, ALFWorld, and VirtualHome) demonstrate that SPA consistently outperforms the state-of-the-art method in both success rate (+2.5\% on average) and grounding accuracy (+1.9\% on average). Further analyses demonstrate that our method remarkably provides more effective intermediate rewards for RL training. Our code is available at https://github.com/WangHanLinHenry/SPA-RL-Agent.
GGBond: Growing Graph-Based AI-Agent Society for Socially-Aware Recommender Simulation
May 27, 2025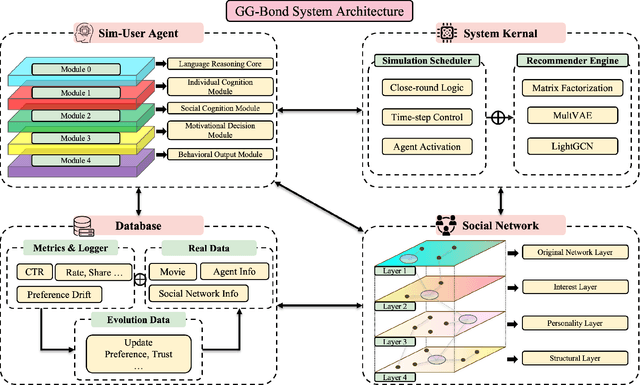
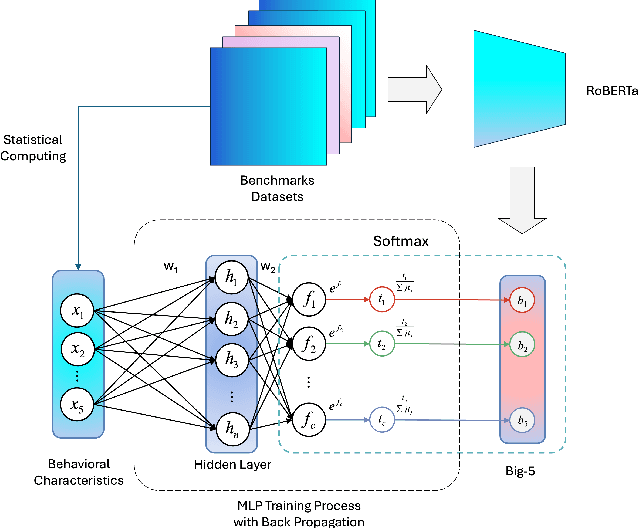
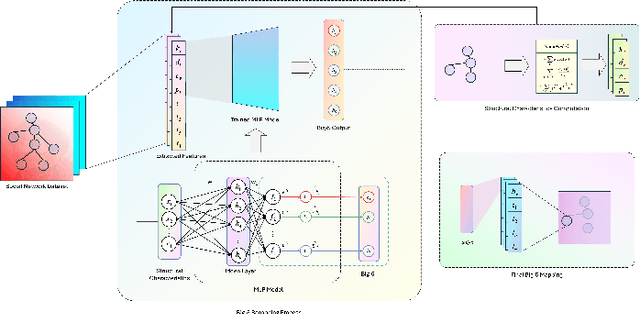
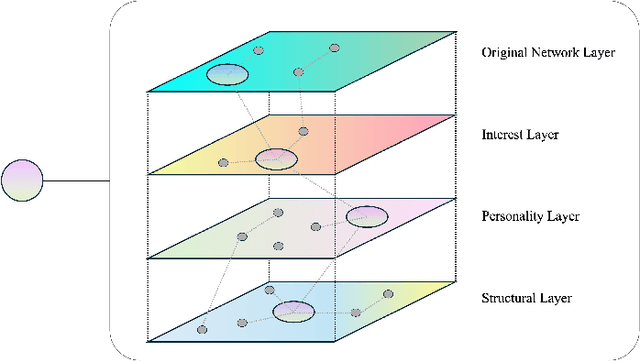
Current personalized recommender systems predominantly rely on static offline data for algorithm design and evaluation, significantly limiting their ability to capture long-term user preference evolution and social influence dynamics in real-world scenarios. To address this fundamental challenge, we propose a high-fidelity social simulation platform integrating human-like cognitive agents and dynamic social interactions to realistically simulate user behavior evolution under recommendation interventions. Specifically, the system comprises a population of Sim-User Agents, each equipped with a five-layer cognitive architecture that encapsulates key psychological mechanisms, including episodic memory, affective state transitions, adaptive preference learning, and dynamic trust-risk assessments. In particular, we innovatively introduce the Intimacy--Curiosity--Reciprocity--Risk (ICR2) motivational engine grounded in psychological and sociological theories, enabling more realistic user decision-making processes. Furthermore, we construct a multilayer heterogeneous social graph (GGBond Graph) supporting dynamic relational evolution, effectively modeling users' evolving social ties and trust dynamics based on interest similarity, personality alignment, and structural homophily. During system operation, agents autonomously respond to recommendations generated by typical recommender algorithms (e.g., Matrix Factorization, MultVAE, LightGCN), deciding whether to consume, rate, and share content while dynamically updating their internal states and social connections, thereby forming a stable, multi-round feedback loop. This innovative design transcends the limitations of traditional static datasets, providing a controlled, observable environment for evaluating long-term recommender effects.
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
May 22, 2025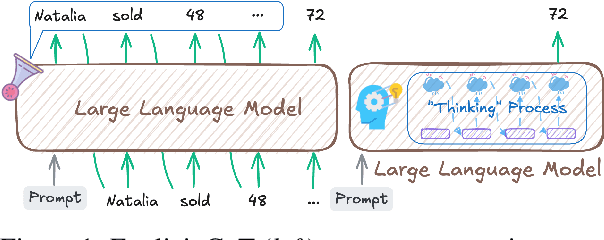

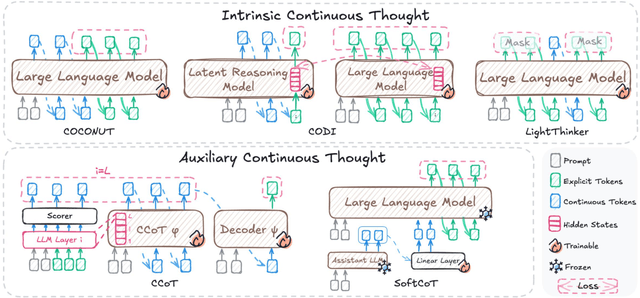
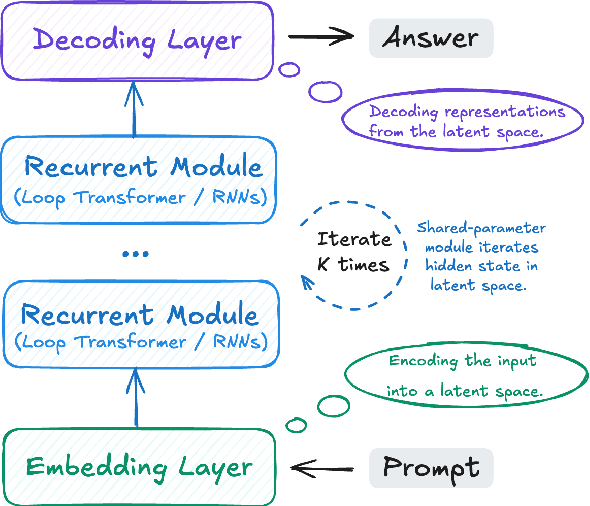
Large Language Models (LLMs) have achieved impressive performance on complex reasoning tasks with Chain-of-Thought (CoT) prompting. However, conventional CoT relies on reasoning steps explicitly verbalized in natural language, introducing inefficiencies and limiting its applicability to abstract reasoning. To address this, there has been growing research interest in latent CoT reasoning, where inference occurs within latent spaces. By decoupling reasoning from language, latent reasoning promises richer cognitive representations and more flexible, faster inference. Researchers have explored various directions in this promising field, including training methodologies, structural innovations, and internal reasoning mechanisms. This paper presents a comprehensive overview and analysis of this reasoning paradigm. We begin by proposing a unified taxonomy from four perspectives: token-wise strategies, internal mechanisms, analysis, and applications. We then provide in-depth discussions and comparative analyses of representative methods, highlighting their design patterns, strengths, and open challenges. We aim to provide a structured foundation for advancing this emerging direction in LLM reasoning. The relevant papers will be regularly updated at https://github.com/EIT-NLP/Awesome-Latent-CoT.
Kernel-Based Enhanced Oversampling Method for Imbalanced Classification
Apr 12, 2025This paper introduces a novel oversampling technique designed to improve classification performance on imbalanced datasets. The proposed method enhances the traditional SMOTE algorithm by incorporating convex combination and kernel-based weighting to generate synthetic samples that better represent the minority class. Through experiments on multiple real-world datasets, we demonstrate that the new technique outperforms existing methods in terms of F1-score, G-mean, and AUC, providing a robust solution for handling imbalanced datasets in classification tasks.
STeCa: Step-level Trajectory Calibration for LLM Agent Learning
Feb 20, 2025Large language model (LLM)-based agents have shown promise in tackling complex tasks by interacting dynamically with the environment. Existing work primarily focuses on behavior cloning from expert demonstrations and preference learning through exploratory trajectory sampling. However, these methods often struggle in long-horizon tasks, where suboptimal actions accumulate step by step, causing agents to deviate from correct task trajectories. To address this, we highlight the importance of timely calibration and the need to automatically construct calibration trajectories for training agents. We propose Step-Level Trajectory Calibration (STeCa), a novel framework for LLM agent learning. Specifically, STeCa identifies suboptimal actions through a step-level reward comparison during exploration. It constructs calibrated trajectories using LLM-driven reflection, enabling agents to learn from improved decision-making processes. These calibrated trajectories, together with successful trajectory data, are utilized for reinforced training. Extensive experiments demonstrate that STeCa significantly outperforms existing methods. Further analysis highlights that step-level calibration enables agents to complete tasks with greater robustness. Our code and data are available at https://github.com/WangHanLinHenry/STeCa.