 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2CL: Exploration-based Error Correction Learning for Embodied Agents
Paper and Code
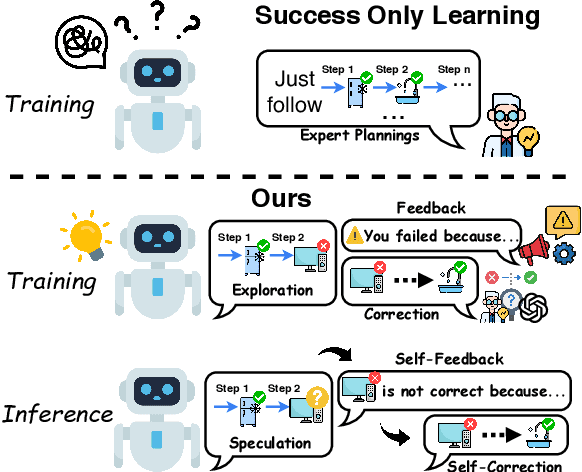



Language models are exhibiting increasing capability in knowledge utilization and reasoning. However, when applied as agents in embodied environments, they often suffer from misalignment between their intrinsic knowledge and environmental knowledge, leading to infeasible actions. Traditional environment alignment methods, such as supervised learning on expert trajectories and reinforcement learning, face limitations in covering environmental knowledge and achieving efficient convergence, respectively. Inspired by human learning, we propose Exploration-based Error Correction Learning (E2CL), a novel framework that leverages exploration-induced errors and environmental feedback to enhance environment alignment for LM-based agents. E2CL incorporates teacher-guided and teacher-free exploration to gather environmental feedback and correct erroneous actions. The agent learns to provide feedback and self-correct, thereby enhancing its adaptability to target environments. Evaluations in the Virtualhome environment demonstrate that E2CL-trained agents outperform those trained by baseline methods and exhibit superior self-correction capabilities.