 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
Jun 08, 2026Chain-of-Thought (CoT) improves the performance of Large Language Models (LLMs) and has been extended to Multimodal Large Language Models (MLLMs). More recent work further moves from text-based multimodal reasoning toward interleaved-modal reasoning, where intermediate steps can incorporate both textual rationales and visual evidence. In this work, we propose a bolder and more ambitious idea: could images alone serve as the reasoning medium for both language and multimodal tasks? To explore this, we propose optical reasoning, which treats images as a standalone reasoning medium. We instantiate this concept with two variants: typographic-based optical reasoning, which optimizes visual layouts for compact rationale rendering, and graphical-based optical reasoning, which composes text and graphical elements into structured visual rationales. Across mathematical, scientific, and interleaved-modal reasoning benchmarks, optical reasoning can match or even exceed traditional text reasoning while reducing reasoning tokens by an average of 28.57% on language tasks and 16% on multimodal tasks, achieving 1.96 times the token efficiency of text reasoning. These results show that images can effectively and efficiently encode rationales while providing a unified visual canvas for reasoning.
ToolSpec: Accelerating Tool Calling via Schema-Aware and Retrieval-Augmented Speculative Decoding
Apr 15, 2026Tool calling has greatly expanded the practical utility of large language models (LLMs) by enabling them to interact with external applications. As LLM capabilities advance, effective tool use increasingly involves multi-step, multi-turn interactions to solve complex tasks. However, the resulting growth in tool interactions incurs substantial latency, posing a key challenge for real-time LLM serving. Through empirical analysis, we find that tool-calling traces are highly structured, conform to constrained schemas, and often exhibit recurring invocation patterns. Motivated by this, we propose ToolSpec, a schema-aware, retrieval-augmented speculative decoding method for accelerating tool calling. ToolSpec exploits predefined tool schemas to generate accurate drafts, using a finite-state machine to alternate between deterministic schema token filling and speculative generation for variable fields. In addition, ToolSpec retrieves similar historical tool invocations and reuses them as drafts to further improve efficiency. ToolSpec presents a plug-and-play solution that can be seamlessly integrated into existing LLM workflows. Experiments across multiple benchmarks demonstrate that ToolSpec achieves up to a 4.2x speedup, substantially outperforming existing training-free speculative decoding methods.
Finding RELIEF: Shaping Reasoning Behavior without Reasoning Supervision via Belief Engineering
Jan 20, 2026Large reasoning models (LRMs) have achieved remarkable success in complex problem-solving, yet they often suffer from computational redundancy or reasoning unfaithfulness. Current methods for shaping LRM behavior typically rely on reinforcement learning or fine-tuning with gold-standard reasoning traces, a paradigm that is both computationally expensive and difficult to scale. In this paper, we reveal that LRMs possess latent \textit{reasoning beliefs} that internally track their own reasoning traits, which can be captured through simple logit probing. Building upon this insight, we propose Reasoning Belief Engineering (RELIEF), a simple yet effective framework that shapes LRM behavior by aligning the model's self-concept with a target belief blueprint. Crucially, RELIEF completely bypasses the need for reasoning-trace supervision. It internalizes desired traits by fine-tuning on synthesized, self-reflective question-answering pairs that affirm the target belief. Extensive experiments on efficiency and faithfulness tasks demonstrate that RELIEF matches or outperforms behavior-supervised and preference-based baselines while requiring lower training costs. Further analysis validates that shifting a model's reasoning belief effectively shapes its actual behavior.
LLM-REVal: Can We Trust LLM Reviewers Yet?
Oct 14, 2025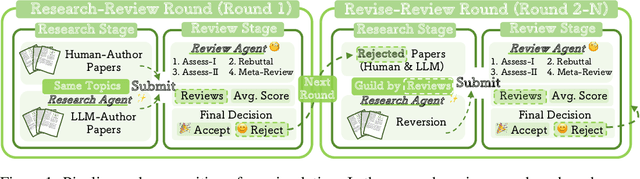
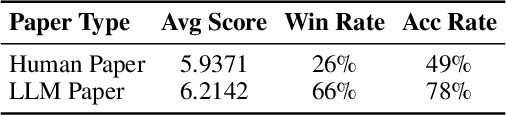
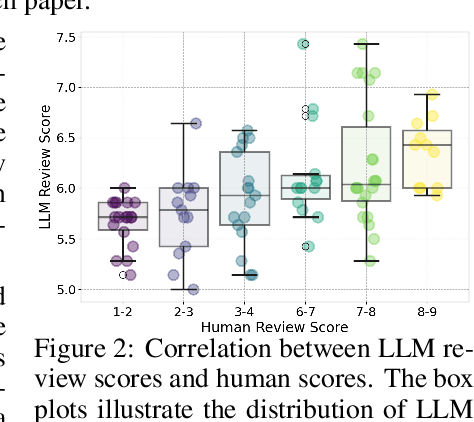
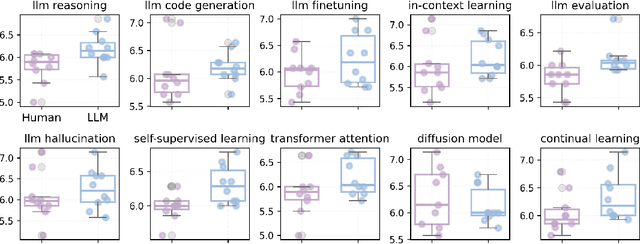
The rapid advancement of large language models (LLMs) has inspired researchers to integrate them extensively into the academic workflow, potentially reshaping how research is practiced and reviewed. While previous studies highlight the potential of LLMs in supporting research and peer review, their dual roles in the academic workflow and the complex interplay between research and review bring new risks that remain largely underexplored. In this study, we focus on how the deep integration of LLMs into both peer-review and research processes may influence scholarly fairness, examining the potential risks of using LLMs as reviewers by simulation. This simulation incorporates a research agent, which generates papers and revises, alongside a review agent, which assesses the submissions. Based on the simulation results, we conduct human annotations and identify pronounced misalignment between LLM-based reviews and human judgments: (1) LLM reviewers systematically inflate scores for LLM-authored papers, assigning them markedly higher scores than human-authored ones; (2) LLM reviewers persistently underrate human-authored papers with critical statements (e.g., risk, fairness), even after multiple revisions. Our analysis reveals that these stem from two primary biases in LLM reviewers: a linguistic feature bias favoring LLM-generated writing styles, and an aversion toward critical statements. These results highlight the risks and equity concerns posed to human authors and academic research if LLMs are deployed in the peer review cycle without adequate caution. On the other hand, revisions guided by LLM reviews yield quality gains in both LLM-based and human evaluations, illustrating the potential of the LLMs-as-reviewers for early-stage researchers and enhancing low-quality papers.
Towards Harmonized Uncertainty Estimation for Large Language Models
May 25, 2025



To facilitate robust and trustworthy deployment of large language models (LLMs), it is essential to quantify the reliability of their generations through uncertainty estimation. While recent efforts have made significant advancements by leveraging the internal logic and linguistic features of LLMs to estimate uncertainty scores, our empirical analysis highlights the pitfalls of these methods to strike a harmonized estimation between indication, balance, and calibration, which hinders their broader capability for accurate uncertainty estimation. To address this challenge, we propose CUE (Corrector for Uncertainty Estimation): A straightforward yet effective method that employs a lightweight model trained on data aligned with the target LLM's performance to adjust uncertainty scores. Comprehensive experiments across diverse models and tasks demonstrate its effectiveness, which achieves consistent improvements of up to 60% over existing methods.
KNN-SSD: Enabling Dynamic Self-Speculative Decoding via Nearest Neighbor Layer Set Optimization
May 22, 2025Speculative Decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by efficiently drafting multiple tokens using a compact model and then verifying them in parallel using the target LLM. Notably, Self-Speculative Decoding proposes skipping certain layers to construct the draft model, which eliminates the need for additional parameters or training. Despite its strengths, we observe in this work that drafting with layer skipping exhibits significant sensitivity to domain shifts, leading to a substantial drop in acceleration performance. To enhance the domain generalizability of this paradigm, we introduce KNN-SSD, an algorithm that leverages K-Nearest Neighbor (KNN) search to match different skipped layers with various domain inputs. We evaluated our algorithm in various models and multiple tasks, observing that its application leads to 1.3x-1.6x speedup in LLM inference.
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
May 22, 2025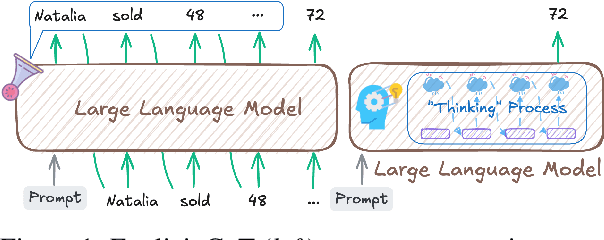

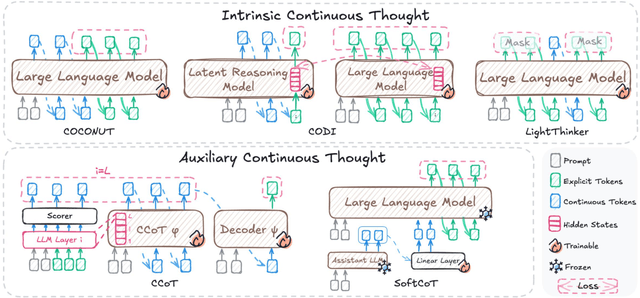
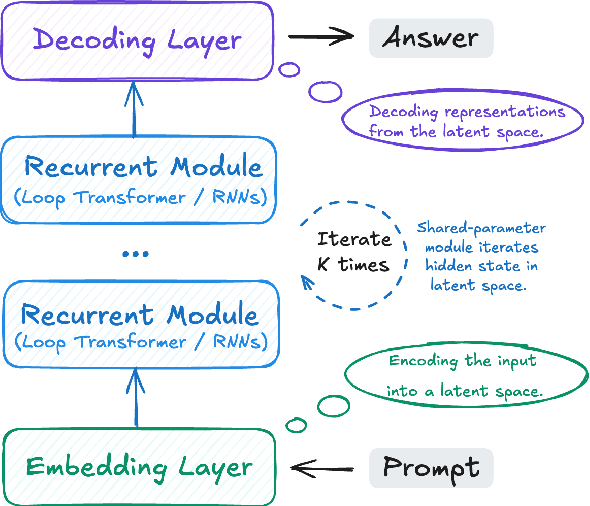
Large Language Models (LLMs) have achieved impressive performance on complex reasoning tasks with Chain-of-Thought (CoT) prompting. However, conventional CoT relies on reasoning steps explicitly verbalized in natural language, introducing inefficiencies and limiting its applicability to abstract reasoning. To address this, there has been growing research interest in latent CoT reasoning, where inference occurs within latent spaces. By decoupling reasoning from language, latent reasoning promises richer cognitive representations and more flexible, faster inference. Researchers have explored various directions in this promising field, including training methodologies, structural innovations, and internal reasoning mechanisms. This paper presents a comprehensive overview and analysis of this reasoning paradigm. We begin by proposing a unified taxonomy from four perspectives: token-wise strategies, internal mechanisms, analysis, and applications. We then provide in-depth discussions and comparative analyses of representative methods, highlighting their design patterns, strengths, and open challenges. We aim to provide a structured foundation for advancing this emerging direction in LLM reasoning. The relevant papers will be regularly updated at https://github.com/EIT-NLP/Awesome-Latent-CoT.
PEToolLLM: Towards Personalized Tool Learning in Large Language Models
Feb 26, 2025Tool learning has emerged as a promising direction by extending Large Language Models' (LLMs) capabilities with external tools. Existing tool learning studies primarily focus on the general-purpose tool-use capability, which addresses explicit user requirements in instructions. However, they overlook the importance of personalized tool-use capability, leading to an inability to handle implicit user preferences. To address the limitation, we first formulate the task of personalized tool learning, which integrates user's interaction history towards personalized tool usage. To fill the gap of missing benchmarks, we construct PEToolBench, featuring diverse user preferences reflected in interaction history under three distinct personalized settings, and encompassing a wide range of tool-use scenarios. Moreover, we propose a framework PEToolLLaMA to adapt LLMs to the personalized tool learning task, which is trained through supervised fine-tuning and direct preference optimization. Extensive experiments on PEToolBench demonstrate the superiority of PEToolLLaMA over existing LLMs.
How Far are LLMs from Being Our Digital Twins? A Benchmark for Persona-Based Behavior Chain Simulation
Feb 20, 2025Recently, LLMs have garnered increasing attention across academic disciplines for their potential as human digital twins, virtual proxies designed to replicate individuals and autonomously perform tasks such as decision-making, problem-solving, and reasoning on their behalf. However, current evaluations of LLMs primarily emphasize dialogue simulation while overlooking human behavior simulation, which is crucial for digital twins. To address this gap, we introduce BehaviorChain, the first benchmark for evaluating LLMs' ability to simulate continuous human behavior. BehaviorChain comprises diverse, high-quality, persona-based behavior chains, totaling 15,846 distinct behaviors across 1,001 unique personas, each with detailed history and profile metadata. For evaluation, we integrate persona metadata into LLMs and employ them to iteratively infer contextually appropriate behaviors within dynamic scenarios provided by BehaviorChain. Comprehensive evaluation results demonstrated that even state-of-the-art models struggle with accurately simulating continuous human behavior.
Beyond Single Frames: Can LMMs Comprehend Temporal and Contextual Narratives in Image Sequences?
Feb 19, 2025Large Multimodal Models (LMMs) have achieved remarkable success across various visual-language tasks. However, existing benchmarks predominantly focus on single-image understanding, leaving the analysis of image sequences largely unexplored. To address this limitation, we introduce StripCipher, a comprehensive benchmark designed to evaluate capabilities of LMMs to comprehend and reason over sequential images. StripCipher comprises a human-annotated dataset and three challenging subtasks: visual narrative comprehension, contextual frame prediction, and temporal narrative reordering. Our evaluation of $16$ state-of-the-art LMMs, including GPT-4o and Qwen2.5VL, reveals a significant performance gap compared to human capabilities, particularly in tasks that require reordering shuffled sequential images. For instance, GPT-4o achieves only 23.93% accuracy in the reordering subtask, which is 56.07% lower than human performance. Further quantitative analysis discuss several factors, such as input format of images, affecting the performance of LLMs in sequential understanding, underscoring the fundamental challenges that remain in the development of LMMs.