 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan MLLMs Understand the Deep Implication Behind Chinese Images?
Oct 17, 2024
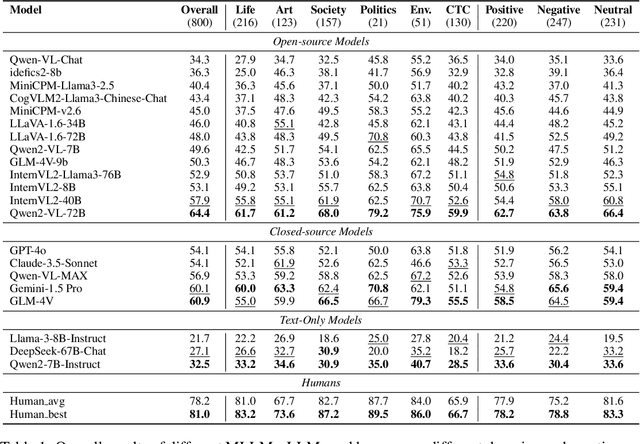
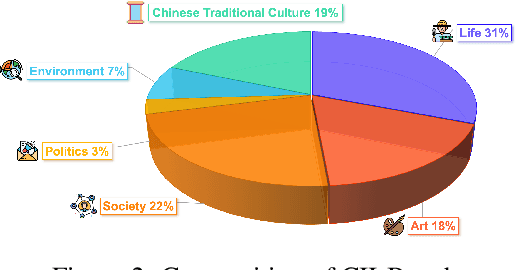
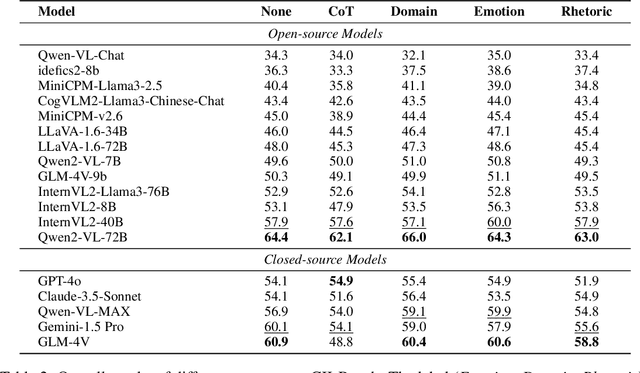
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the **C**hinese **I**mage **I**mplication understanding **Bench**mark, **CII-Bench**, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.
DeliLaw: A Chinese Legal Counselling System Based on a Large Language Model
Aug 01, 2024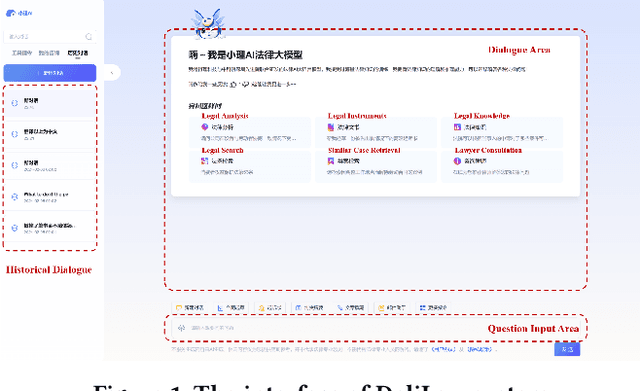

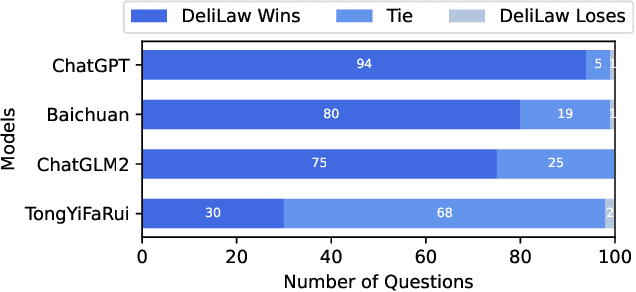
Traditional legal retrieval systems designed to retrieve legal documents, statutes, precedents, and other legal information are unable to give satisfactory answers due to lack of semantic understanding of specific questions. Large Language Models (LLMs) have achieved excellent results in a variety of natural language processing tasks, which inspired us that we train a LLM in the legal domain to help legal retrieval. However, in the Chinese legal domain, due to the complexity of legal questions and the rigour of legal articles, there is no legal large model with satisfactory practical application yet. In this paper, we present DeliLaw, a Chinese legal counselling system based on a large language model. DeliLaw integrates a legal retrieval module and a case retrieval module to overcome the model hallucination. Users can consult professional legal questions, search for legal articles and relevant judgement cases, etc. on the DeliLaw system in a dialogue mode. In addition, DeliLaw supports the use of English for counseling. we provide the address of the system: https://data.delilegal.com/lawQuestion.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
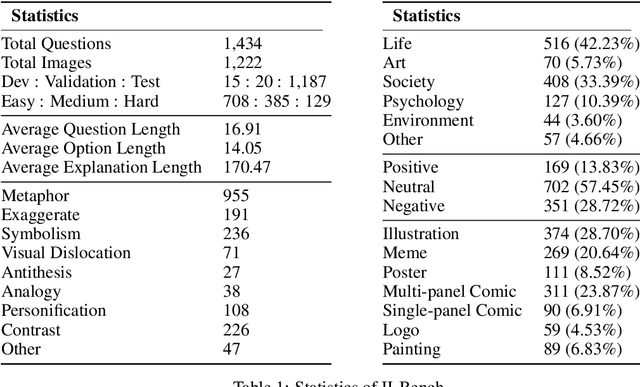
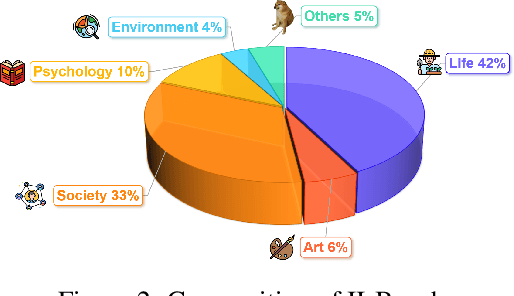
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
CLHA: A Simple yet Effective Contrastive Learning Framework for Human Alignment
Mar 26, 2024Reinforcement learning from human feedback (RLHF) is a crucial technique in aligning large language models (LLMs) with human preferences, ensuring these LLMs behave in beneficial and comprehensible ways to users. However, a longstanding challenge in human alignment techniques based on reinforcement learning lies in their inherent complexity and difficulty in training. To address this challenge, we present a simple yet effective Contrastive Learning Framework for Human Alignment (CLHA) to align LLMs with human preferences directly. CLHA employs a novel rescoring strategy to evaluate the noise within the data by considering its inherent quality and dynamically adjusting the training process. Simultaneously, CLHA utilizes pairwise contrastive loss and adaptive supervised fine-tuning loss to adaptively modify the likelihood of generating responses, ensuring enhanced alignment with human preferences. Using advanced methods, CLHA surpasses other algorithms, showcasing superior performance in terms of reward model scores, automatic evaluations, and human assessments on the widely used ``Helpful and Harmless'' dataset.