 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Ride-Hailing Forecasting at DiDi with Multi-View Geospatial Representation Learning from the Web
Feb 11, 2026The proliferation of ride-hailing services has fundamentally transformed urban mobility patterns, making accurate ride-hailing forecasting crucial for optimizing passenger experience and urban transportation efficiency. However, ride-hailing forecasting faces significant challenges due to geospatial heterogeneity and high susceptibility to external events. This paper proposes MVGR-Net(Multi-View Geospatial Representation Learning), a novel framework that addresses these challenges through a two-stage approach. In the pretraining stage, we learn comprehensive geospatial representations by integrating Points-of-Interest and temporal mobility patterns to capture regional characteristics from both semantic attribute and temporal mobility pattern views. The forecasting stage leverages these representations through a prompt-empowered framework that fine-tunes Large Language Models while incorporating external events. Extensive experiments on DiDi's real-world datasets demonstrate the state-of-the-art performance.
Unlocking Location Intelligence: A Survey from Deep Learning to The LLM Era
May 13, 2025Location Intelligence (LI), the science of transforming location-centric geospatial data into actionable knowledge, has become a cornerstone of modern spatial decision-making. The rapid evolution of Geospatial Representation Learning is fundamentally reshaping LI development through two successive technological revolutions: the deep learning breakthrough and the emerging large language model (LLM) paradigm. While deep neural networks (DNNs) have demonstrated remarkable success in automated feature extraction from structured geospatial data (e.g., satellite imagery, GPS trajectories), the recent integration of LLMs introduces transformative capabilities for cross-modal geospatial reasoning and unstructured geo-textual data processing. This survey presents a comprehensive review of geospatial representation learning across both technological eras, organizing them into a structured taxonomy based on the complete pipeline comprising: (1) data perspective, (2) methodological perspective and (3) application perspective. We also highlight current advancements, discuss existing limitations, and propose potential future research directions in the LLM era. This work offers a thorough exploration of the field and providing a roadmap for further innovation in LI. The summary of the up-to-date paper list can be found in https://github.com/CityMind-Lab/Awesome-Location-Intelligence and will undergo continuous updates.
Advancing Medical Radiograph Representation Learning: A Hybrid Pre-training Paradigm with Multilevel Semantic Granularity
Oct 01, 2024

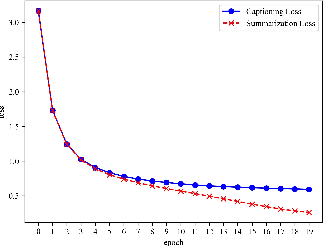

This paper introduces an innovative approach to Medical Vision-Language Pre-training (Med-VLP) area in the specialized context of radiograph representation learning. While conventional methods frequently merge textual annotations into unified reports, we acknowledge the intrinsic hierarchical relationship between the findings and impression section in radiograph datasets. To establish a targeted correspondence between images and texts, we propose a novel HybridMED framework to align global-level visual representations with impression and token-level visual representations with findings. Moreover, our framework incorporates a generation decoder that employs two proxy tasks, responsible for generating the impression from (1) images, via a captioning branch, and (2) findings, through a summarization branch. Additionally, knowledge distillation is leveraged to facilitate the training process. Experiments on the MIMIC-CXR dataset reveal that our summarization branch effectively distills knowledge to the captioning branch, enhancing model performance without significantly increasing parameter requirements due to the shared self-attention and feed-forward architecture.
* 18 pages
Learning Geospatial Region Embedding with Heterogeneous Graph
May 23, 2024Learning effective geospatial embeddings is crucial for a series of geospatial applications such as city analytics and earth monitoring. However, learning comprehensive region representations presents two significant challenges: first, the deficiency of effective intra-region feature representation; and second, the difficulty of learning from intricate inter-region dependencies. In this paper, we present GeoHG, an effective heterogeneous graph structure for learning comprehensive region embeddings for various downstream tasks. Specifically, we tailor satellite image representation learning through geo-entity segmentation and point-of-interest (POI) integration for expressive intra-regional features. Furthermore, GeoHG unifies informative spatial interdependencies and socio-environmental attributes into a powerful heterogeneous graph to encourage explicit modeling of higher-order inter-regional relationships. The intra-regional features and inter-regional correlations are seamlessly integrated by a model-agnostic graph learning framework for diverse downstream tasks. Extensive experiments demonstrate the effectiveness of GeoHG in geo-prediction tasks compared to existing methods, even under extreme data scarcity (with just 5% of training data). With interpretable region representations, GeoHG exhibits strong generalization capabilities across regions. We will release code and data upon paper notification.
UrbanCross: Enhancing Satellite Image-Text Retrieval with Cross-Domain Adaptation
Apr 22, 2024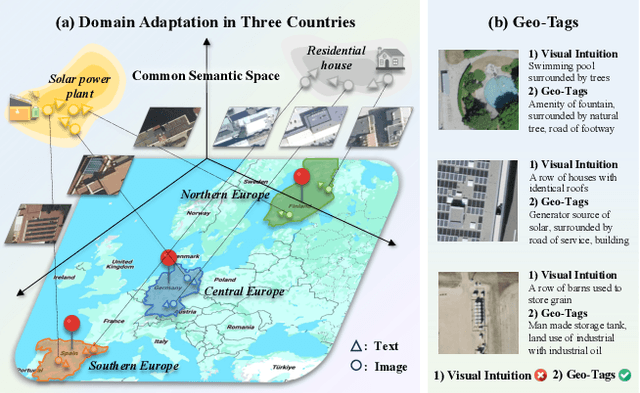



Urbanization challenges underscore the necessity for effective satellite image-text retrieval methods to swiftly access specific information enriched with geographic semantics for urban applications. However, existing methods often overlook significant domain gaps across diverse urban landscapes, primarily focusing on enhancing retrieval performance within single domains. To tackle this issue, we present UrbanCross, a new framework for cross-domain satellite image-text retrieval. UrbanCross leverages a high-quality, cross-domain dataset enriched with extensive geo-tags from three countries to highlight domain diversity. It employs the Large Multimodal Model (LMM) for textual refinement and the Segment Anything Model (SAM) for visual augmentation, achieving a fine-grained alignment of images, segments and texts, yielding a 10% improvement in retrieval performance. Additionally, UrbanCross incorporates an adaptive curriculum-based source sampler and a weighted adversarial cross-domain fine-tuning module, progressively enhancing adaptability across various domains. Extensive experiments confirm UrbanCross's superior efficiency in retrieval and adaptation to new urban environments, demonstrating an average performance increase of 15% over its version without domain adaptation mechanisms, effectively bridging the domain gap.
UrbanVLP: A Multi-Granularity Vision-Language Pre-Trained Foundation Model for Urban Indicator Prediction
Mar 25, 2024Urban indicator prediction aims to infer socio-economic metrics in diverse urban landscapes using data-driven methods. However, prevalent pre-trained models, particularly those reliant on satellite imagery, face dual challenges. Firstly, concentrating solely on macro-level patterns from satellite data may introduce bias, lacking nuanced details at micro levels, such as architectural details at a place. Secondly, the lack of interpretability in pre-trained models limits their utility in providing transparent evidence for urban planning. In response to these issues, we devise a novel Vision-Language Pre-Trained Model (UrbanVLP) in this paper. Our UrbanVLP seamlessly integrates multi-granularity information from both macro (satellite) and micro (street-view) levels, overcoming the limitations of prior pre-trained models. Moreover, it introduces automatic text generation and calibration, elevating interpretability in downstream applications by producing high-quality text descriptions of urban imagery. Rigorous experiments conducted across six socio-economic tasks underscore UrbanVLP's superior performance. We also deploy a web platform to verify its practicality.
Deep Learning for Cross-Domain Data Fusion in Urban Computing: Taxonomy, Advances, and Outlook
Feb 29, 2024



As cities continue to burgeon, Urban Computing emerges as a pivotal discipline for sustainable development by harnessing the power of cross-domain data fusion from diverse sources (e.g., geographical, traffic, social media, and environmental data) and modalities (e.g., spatio-temporal, visual, and textual modalities). Recently, we are witnessing a rising trend that utilizes various deep-learning methods to facilitate cross-domain data fusion in smart cities. To this end, we propose the first survey that systematically reviews the latest advancements in deep learning-based data fusion methods tailored for urban computing. Specifically, we first delve into data perspective to comprehend the role of each modality and data source. Secondly, we classify the methodology into four primary categories: feature-based, alignment-based, contrast-based, and generation-based fusion methods. Thirdly, we further categorize multi-modal urban applications into seven types: urban planning, transportation, economy, public safety, society, environment, and energy. Compared with previous surveys, we focus more on the synergy of deep learning methods with urban computing applications. Furthermore, we shed light on the interplay between Large Language Models (LLMs) and urban computing, postulating future research directions that could revolutionize the field. We firmly believe that the taxonomy, progress, and prospects delineated in our survey stand poised to significantly enrich the research community. The summary of the comprehensive and up-to-date paper list can be found at https://github.com/yoshall/Awesome-Multimodal-Urban-Computing.
Deformation Robust Text Spotting with Geometric Prior
Aug 31, 2023



The goal of text spotting is to perform text detection and recognition in an end-to-end manner. Although the diversity of luminosity and orientation in scene texts has been widely studied, the font diversity and shape variance of the same character are ignored in recent works, since most characters in natural images are rendered in standard fonts. To solve this problem, we present a Chinese Artistic Dataset, termed as ARText, which contains 33,000 artistic images with rich shape deformation and font diversity. Based on this database, we develop a deformation robust text spotting method (DR TextSpotter) to solve the recognition problem of complex deformation of characters in different fonts. Specifically, we propose a geometric prior module to highlight the important features based on the unsupervised landmark detection sub-network. A graph convolution network is further constructed to fuse the character features and landmark features, and then performs semantic reasoning to enhance the discrimination for different characters. The experiments are conducted on ARText and IC19-ReCTS datasets. Our results demonstrate the effectiveness of our proposed method.