 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Feb 12, 2026Time Series Foundation Models (TSFMs) achieve strong zero-shot forecasting through large-scale pre-training, but adapting them to downstream domains under distribution shift remains challenging. Existing solutions face a trade-off: Parametric Adaptation can cause catastrophic forgetting and requires costly multi-domain maintenance, while Non-Parametric Retrieval improves forecasts but incurs high inference latency due to datastore search. We propose Parametric Memory Distillation and implement it as TS-Memory, a lightweight memory adapter that augments frozen TSFMs. TS-Memory is trained in two stages. First, we construct an offline, leakage-safe kNN teacher that synthesizes confidence-aware quantile targets from retrieved futures. Second, we distill this retrieval-induced distributional correction into a lightweight memory adapter via confidence-gated supervision. During inference, TS-Memory fuses memory and backbone predictions with constant-time overhead, enabling retrieval-free deployment. Experiments across diverse TSFMs and benchmarks demonstrate consistent improvements in both point and probabilistic forecasting over representative adaptation methods, with efficiency comparable to the frozen backbone.
Breaking the Regional Barrier: Inductive Semantic Topology Learning for Worldwide Air Quality Forecasting
Jan 29, 2026Global air quality forecasting grapples with extreme spatial heterogeneity and the poor generalization of existing transductive models to unseen regions. To tackle this, we propose OmniAir, a semantic topology learning framework tailored for global station-level prediction. By encoding invariant physical environmental attributes into generalizable station identities and dynamically constructing adaptive sparse topologies, our approach effectively captures long-range non-Euclidean correlations and physical diffusion patterns across unevenly distributed global networks. We further curate WorldAir, a massive dataset covering over 7,800 stations worldwide. Extensive experiments show that OmniAir achieves state-of-the-art performance against 18 baselines, maintaining high efficiency and scalability with speeds nearly 10 times faster than existing models, while effectively bridging the monitoring gap in data-sparse regions.
DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting
Jan 29, 2026Deep time series models are vulnerable to noisy data ubiquitous in real-world applications. Existing robustness strategies either prune data or rely on costly prior quantification, failing to balance effectiveness and efficiency. In this paper, we introduce DropoutTS, a model-agnostic plugin that shifts the paradigm from "what" to learn to "how much" to learn. DropoutTS employs a Sample-Adaptive Dropout mechanism: leveraging spectral sparsity to efficiently quantify instance-level noise via reconstruction residuals, it dynamically calibrates model learning capacity by mapping noise to adaptive dropout rates - selectively suppressing spurious fluctuations while preserving fine-grained fidelity. Extensive experiments across diverse noise regimes and open benchmarks show DropoutTS consistently boosts superior backbones' performance, delivering advanced robustness with negligible parameter overhead and no architectural modifications. Our code is available at https://github.com/CityMind-Lab/DropoutTS.
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Jan 17, 2026Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally expensive and grapples with the heterogeneity of domain-specific spatial patterns. Substantially extending our preliminary conference version, we present FactoST-v2, an enhanced factorized framework redesigned for full weight transfer and arbitrary-length generalization. FactoST-v2 decouples universal temporal learning from domain-specific spatial adaptation. The first stage pretrains a minimalist encoder-only backbone using randomized sequence masking to capture invariant temporal dynamics, enabling probabilistic quantile prediction across variable horizons. The second stage employs a streamlined adapter to rapidly inject spatial awareness via meta adaptive learning and prompting. Comprehensive evaluations across diverse domains demonstrate that FactoST-v2 achieves state-of-the-art accuracy with linear efficiency - significantly outperforming existing foundation models in zero-shot and few-shot scenarios while rivaling domain-specific expert baselines. This factorized paradigm offers a practical, scalable path toward truly universal STFMs. Code is available at https://github.com/CityMind-Lab/FactoST.
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting
Feb 06, 2025Recent advancements in time series forecasting have explored augmenting models with text or vision modalities to improve accuracy. While text provides contextual understanding, it often lacks fine-grained temporal details. Conversely, vision captures intricate temporal patterns but lacks semantic context, limiting the complementary potential of these modalities. To address this, we propose Time-VLM, a novel multimodal framework that leverages pre-trained Vision-Language Models (VLMs) to bridge temporal, visual, and textual modalities for enhanced forecasting. Our framework comprises three key components: (1) a Retrieval-Augmented Learner, which extracts enriched temporal features through memory bank interactions; (2) a Vision-Augmented Learner, which encodes time series as informative images; and (3) a Text-Augmented Learner, which generates contextual textual descriptions. These components collaborate with frozen pre-trained VLMs to produce multimodal embeddings, which are then fused with temporal features for final prediction. Extensive experiments across diverse datasets demonstrate that Time-VLM achieves superior performance, particularly in few-shot and zero-shot scenarios, thereby establishing a new direction for multimodal time series forecasting.
Cross Space and Time: A Spatio-Temporal Unitized Model for Traffic Flow Forecasting
Nov 14, 2024



Predicting spatio-temporal traffic flow presents significant challenges due to complex interactions between spatial and temporal factors. Existing approaches often address these dimensions in isolation, neglecting their critical interdependencies. In this paper, we introduce the Spatio-Temporal Unitized Model (STUM), a unified framework designed to capture both spatial and temporal dependencies while addressing spatio-temporal heterogeneity through techniques such as distribution alignment and feature fusion. It also ensures both predictive accuracy and computational efficiency. Central to STUM is the Adaptive Spatio-temporal Unitized Cell (ASTUC), which utilizes low-rank matrices to seamlessly store, update, and interact with space, time, as well as their correlations. Our framework is also modular, allowing it to integrate with various spatio-temporal graph neural networks through components such as backbone models, feature extractors, residual fusion blocks, and predictive modules to collectively enhance forecasting outcomes. Experimental results across multiple real-world datasets demonstrate that STUM consistently improves prediction performance with minimal computational cost. These findings are further supported by hyperparameter optimization, pre-training analysis, and result visualization. We provide our source code for reproducibility at https://anonymous.4open.science/r/STUM-E4F0.
Navigating Spatio-Temporal Heterogeneity: A Graph Transformer Approach for Traffic Forecasting
Aug 20, 2024



Traffic forecasting has emerged as a crucial research area in the development of smart cities. Although various neural networks with intricate architectures have been developed to address this problem, they still face two key challenges: i) Recent advancements in network designs for modeling spatio-temporal correlations are starting to see diminishing returns in performance enhancements. ii) Additionally, most models do not account for the spatio-temporal heterogeneity inherent in traffic data, i.e., traffic distribution varies significantly across different regions and traffic flow patterns fluctuate across various time slots. To tackle these challenges, we introduce the Spatio-Temporal Graph Transformer (STGormer), which effectively integrates attribute and structure information inherent in traffic data for learning spatio-temporal correlations, and a mixture-of-experts module for capturing heterogeneity along spaital and temporal axes. Specifically, we design two straightforward yet effective spatial encoding methods based on the graph structure and integrate time position encoding into the vanilla transformer to capture spatio-temporal traffic patterns. Additionally, a mixture-of-experts enhanced feedforward neural network (FNN) module adaptively assigns suitable expert layers to distinct patterns via a spatio-temporal gating network, further improving overall prediction accuracy. Experiments on five real-world datasets demonstrate that STGormer achieves state-of-the-art performance.
Predicting Parking Availability in Singapore with Cross-Domain Data: A New Dataset and A Data-Driven Approach
May 29, 2024



The increasing number of vehicles highlights the need for efficient parking space management. Predicting real-time Parking Availability (PA) can help mitigate traffic congestion and the corresponding social problems, which is a pressing issue in densely populated cities like Singapore. In this study, we aim to collectively predict future PA across Singapore with complex factors from various domains. The contributions in this paper are listed as follows: (1) A New Dataset: We introduce the \texttt{SINPA} dataset, containing a year's worth of PA data from 1,687 parking lots in Singapore, enriched with various spatial and temporal factors. (2) A Data-Driven Approach: We present DeepPA, a novel deep-learning framework, to collectively and efficiently predict future PA across thousands of parking lots. (3) Extensive Experiments and Deployment: DeepPA demonstrates a 9.2% reduction in prediction error for up to 3-hour forecasts compared to existing advanced models. Furthermore, we implement DeepPA in a practical web-based platform to provide real-time PA predictions to aid drivers and inform urban planning for the governors in Singapore. We release the dataset and source code at https://github.com/yoshall/SINPA.
UrbanCross: Enhancing Satellite Image-Text Retrieval with Cross-Domain Adaptation
Apr 22, 2024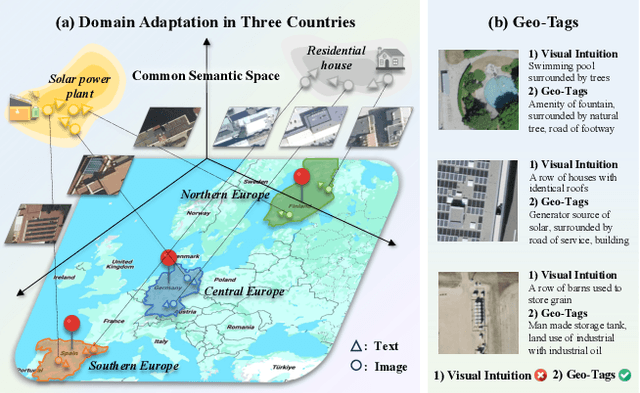



Urbanization challenges underscore the necessity for effective satellite image-text retrieval methods to swiftly access specific information enriched with geographic semantics for urban applications. However, existing methods often overlook significant domain gaps across diverse urban landscapes, primarily focusing on enhancing retrieval performance within single domains. To tackle this issue, we present UrbanCross, a new framework for cross-domain satellite image-text retrieval. UrbanCross leverages a high-quality, cross-domain dataset enriched with extensive geo-tags from three countries to highlight domain diversity. It employs the Large Multimodal Model (LMM) for textual refinement and the Segment Anything Model (SAM) for visual augmentation, achieving a fine-grained alignment of images, segments and texts, yielding a 10% improvement in retrieval performance. Additionally, UrbanCross incorporates an adaptive curriculum-based source sampler and a weighted adversarial cross-domain fine-tuning module, progressively enhancing adaptability across various domains. Extensive experiments confirm UrbanCross's superior efficiency in retrieval and adaptation to new urban environments, demonstrating an average performance increase of 15% over its version without domain adaptation mechanisms, effectively bridging the domain gap.
UrbanVLP: A Multi-Granularity Vision-Language Pre-Trained Foundation Model for Urban Indicator Prediction
Mar 25, 2024Urban indicator prediction aims to infer socio-economic metrics in diverse urban landscapes using data-driven methods. However, prevalent pre-trained models, particularly those reliant on satellite imagery, face dual challenges. Firstly, concentrating solely on macro-level patterns from satellite data may introduce bias, lacking nuanced details at micro levels, such as architectural details at a place. Secondly, the lack of interpretability in pre-trained models limits their utility in providing transparent evidence for urban planning. In response to these issues, we devise a novel Vision-Language Pre-Trained Model (UrbanVLP) in this paper. Our UrbanVLP seamlessly integrates multi-granularity information from both macro (satellite) and micro (street-view) levels, overcoming the limitations of prior pre-trained models. Moreover, it introduces automatic text generation and calibration, elevating interpretability in downstream applications by producing high-quality text descriptions of urban imagery. Rigorous experiments conducted across six socio-economic tasks underscore UrbanVLP's superior performance. We also deploy a web platform to verify its practicality.