 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proximal Algorithm for Network Slimming
Paper and Code
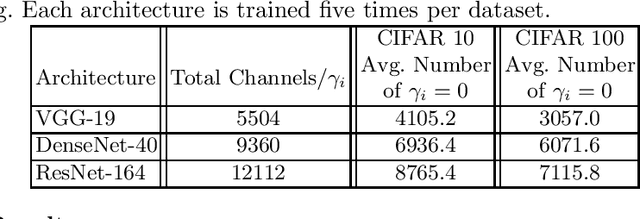

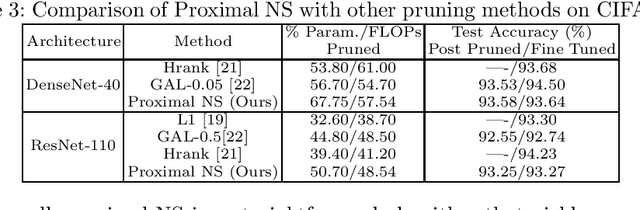
As a popular channel pruning method for convolutional neural networks (CNNs), network slimming (NS) has a three-stage process: (1) it trains a CNN with $\ell_1$ regularization applied to the scaling factors of the batch normalization layers; (2) it removes channels whose scaling factors are below a chosen threshold; and (3) it retrains the pruned model to recover the original accuracy. This time-consuming, three-step process is a result of using subgradient descent to train CNNs. Because subgradient descent does not exactly train CNNs towards sparse, accurate structures, the latter two steps are necessary. Moreover, subgradient descent does not have any convergence guarantee. Therefore, we develop an alternative algorithm called proximal NS. Our proposed algorithm trains CNNs towards sparse, accurate structures, so identifying a scaling factor threshold is unnecessary and fine tuning the pruned CNNs is optional. Using Kurdyka-{\L}ojasiewicz assumptions, we establish global convergence of proximal NS. Lastly, we validate the efficacy of the proposed algorithm on VGGNet, DenseNet and ResNet on CIFAR 10/100. Our experiments demonstrate that after one round of training, proximal NS yields a CNN with competitive accuracy and compression.