 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier-Mixed Window Attention: Accelerating Informer for Long Sequence Time-Series Forecasting
Paper and Code
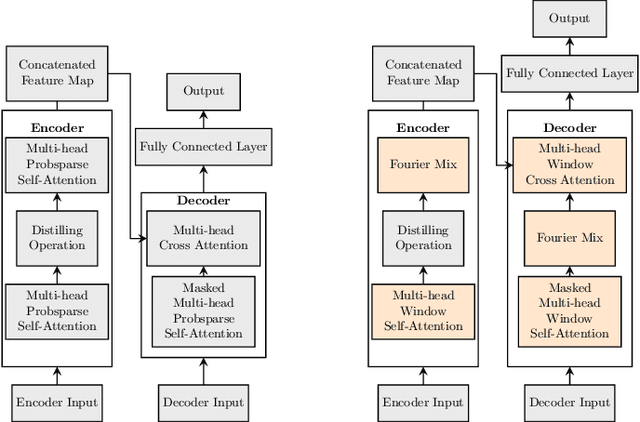

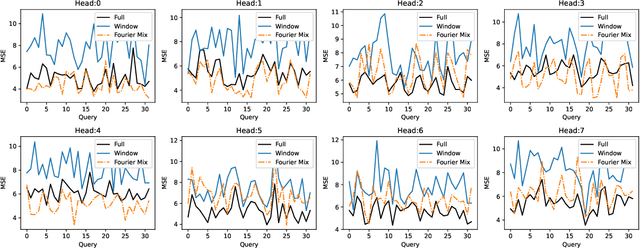

We study a fast local-global window-based attention method to accelerate Informer for long sequence time-series forecasting. While window attention is local and a considerable computational saving, it lacks the ability to capture global token information which is compensated by a subsequent Fourier transform block. Our method, named FWin, does not rely on query sparsity hypothesis and an empirical approximation underlying the ProbSparse attention of Informer. Through experiments on univariate and multivariate datasets, we show that FWin transformers improve the overall prediction accuracies of Informer while accelerating its inference speeds by 40 to 50 %. We also show in a nonlinear regression model that a learned FWin type attention approaches or even outperforms softmax full attention based on key vectors extracted from an Informer model's full attention layer acting on time series data.