 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAd Insertion in LLM-Generated Responses
Jan 27, 2026Sustainable monetization of Large Language Models (LLMs) remains a critical open challenge. Traditional search advertising, which relies on static keywords, fails to capture the fleeting, context-dependent user intents--the specific information, goods, or services a user seeks--embedded in conversational flows. Beyond the standard goal of social welfare maximization, effective LLM advertising imposes additional requirements on contextual coherence (ensuring ads align semantically with transient user intents) and computational efficiency (avoiding user interaction latency), as well as adherence to ethical and regulatory standards, including preserving privacy and ensuring explicit ad disclosure. Although various recent solutions have explored bidding on token-level and query-level, both categories of approaches generally fail to holistically satisfy this multifaceted set of constraints. We propose a practical framework that resolves these tensions through two decoupling strategies. First, we decouple ad insertion from response generation to ensure safety and explicit disclosure. Second, we decouple bidding from specific user queries by using ``genres'' (high-level semantic clusters) as a proxy. This allows advertisers to bid on stable categories rather than sensitive real-time response, reducing computational burden and privacy risks. We demonstrate that applying the VCG auction mechanism to this genre-based framework yields approximately dominant strategy incentive compatibility (DSIC) and individual rationality (IR), as well as approximately optimal social welfare, while maintaining high computational efficiency. Finally, we introduce an "LLM-as-a-Judge" metric to estimate contextual coherence. Our experiments show that this metric correlates strongly with human ratings (Spearman's $ρ\approx 0.66$), outperforming 80% of individual human evaluators.
Recommendation and Temptation
Dec 13, 2024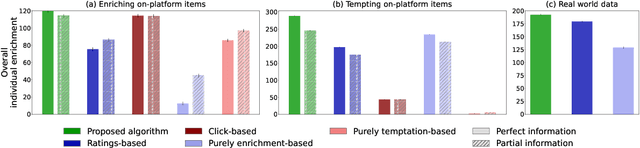
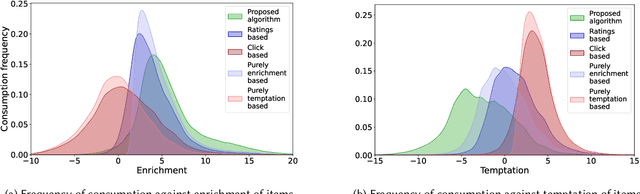
Traditional recommender systems based on utility maximization and revealed preferences often fail to capture users' dual-self nature, where consumption choices are driven by both long-term benefits (enrichment) and desire for instant gratification (temptation). Consequently, these systems may generate recommendations that fail to provide long-lasting satisfaction to users. To address this issue, we propose a novel user model that accounts for this dual-self behavior and develop an optimal recommendation strategy to maximize enrichment from consumption. We highlight the limitations of historical consumption data in implementing this strategy and present an estimation framework that makes minimal assumptions and leverages explicit user feedback and implicit choice data to overcome these constraints. We evaluate our approach through both synthetic simulations and simulations based on real-world data from the MovieLens dataset. Results demonstrate that our proposed recommender can deliver superior enrichment compared to several competitive baseline algorithms that assume a single utility type and rely solely on revealed preferences. Our work emphasizes the critical importance of optimizing for enrichment in recommender systems, particularly in temptation-laden consumption contexts. Our findings have significant implications for content platforms, user experience design, and the development of responsible AI systems, paving the way for more nuanced and user-centric recommendation approaches.
Benchmarking LLMs' Judgments with No Gold Standard
Nov 11, 2024



We introduce the GEM (Generative Estimator for Mutual Information), an evaluation metric for assessing language generation by Large Language Models (LLMs), particularly in generating informative judgments, without the need for a gold standard reference. GEM broadens the scenarios where we can benchmark LLM generation performance-from traditional ones, like machine translation and summarization, where gold standard references are readily available, to subjective tasks without clear gold standards, such as academic peer review. GEM uses a generative model to estimate mutual information between candidate and reference responses, without requiring the reference to be a gold standard. In experiments on a human-annotated dataset, GEM demonstrates competitive correlations with human scores compared to the state-of-the-art GPT-4o Examiner, and outperforms all other baselines. Additionally, GEM is more robust against strategic manipulations, such as rephrasing or elongation, which can artificially inflate scores under a GPT-4o Examiner. We also present GRE-bench (Generating Review Evaluation Benchmark) which evaluates LLMs based on how well they can generate high-quality peer reviews for academic research papers. Because GRE-bench is based upon GEM, it inherits its robustness properties. Additionally, GRE-bench circumvents data contamination problems (or data leakage) by using the continuous influx of new open-access research papers and peer reviews each year. We show GRE-bench results of various popular LLMs on their peer review capabilities using the ICLR2023 dataset.
Eliciting Informative Text Evaluations with Large Language Models
May 28, 2024
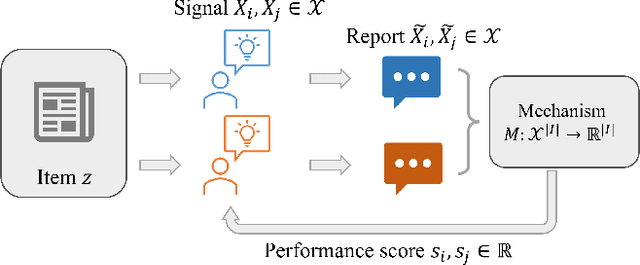


Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
Filter Bubble or Homogenization? Disentangling the Long-Term Effects of Recommendations on User Consumption Patterns
Mar 07, 2024Recommendation algorithms play a pivotal role in shaping our media choices, which makes it crucial to comprehend their long-term impact on user behavior. These algorithms are often linked to two critical outcomes: homogenization, wherein users consume similar content despite disparate underlying preferences, and the filter bubble effect, wherein individuals with differing preferences only consume content aligned with their preferences (without much overlap with other users). Prior research assumes a trade-off between homogenization and filter bubble effects and then shows that personalized recommendations mitigate filter bubbles by fostering homogenization. However, because of this assumption of a tradeoff between these two effects, prior work cannot develop a more nuanced view of how recommendation systems may independently impact homogenization and filter bubble effects. We develop a more refined definition of homogenization and the filter bubble effect by decomposing them into two key metrics: how different the average consumption is between users (inter-user diversity) and how varied an individual's consumption is (intra-user diversity). We then use a novel agent-based simulation framework that enables a holistic view of the impact of recommendation systems on homogenization and filter bubble effects. Our simulations show that traditional recommendation algorithms (based on past behavior) mainly reduce filter bubbles by affecting inter-user diversity without significantly impacting intra-user diversity. Building on these findings, we introduce two new recommendation algorithms that take a more nuanced approach by accounting for both types of diversity.
Spot Check Equivalence: an Interpretable Metric for Information Elicitation Mechanisms
Feb 21, 2024Because high-quality data is like oxygen for AI systems, effectively eliciting information from crowdsourcing workers has become a first-order problem for developing high-performance machine learning algorithms. Two prevalent paradigms, spot-checking and peer prediction, enable the design of mechanisms to evaluate and incentivize high-quality data from human labelers. So far, at least three metrics have been proposed to compare the performances of these techniques [33, 8, 3]. However, different metrics lead to divergent and even contradictory results in various contexts. In this paper, we harmonize these divergent stories, showing that two of these metrics are actually the same within certain contexts and explain the divergence of the third. Moreover, we unify these different contexts by introducing \textit{Spot Check Equivalence}, which offers an interpretable metric for the effectiveness of a peer prediction mechanism. Finally, we present two approaches to compute spot check equivalence in various contexts, where simulation results verify the effectiveness of our proposed metric.
Eliciting Honest Information From Authors Using Sequential Review
Nov 24, 2023In the setting of conference peer review, the conference aims to accept high-quality papers and reject low-quality papers based on noisy review scores. A recent work proposes the isotonic mechanism, which can elicit the ranking of paper qualities from an author with multiple submissions to help improve the conference's decisions. However, the isotonic mechanism relies on the assumption that the author's utility is both an increasing and a convex function with respect to the review score, which is often violated in peer review settings (e.g.~when authors aim to maximize the number of accepted papers). In this paper, we propose a sequential review mechanism that can truthfully elicit the ranking information from authors while only assuming the agent's utility is increasing with respect to the true quality of her accepted papers. The key idea is to review the papers of an author in a sequence based on the provided ranking and conditioning the review of the next paper on the review scores of the previous papers. Advantages of the sequential review mechanism include 1) eliciting truthful ranking information in a more realistic setting than prior work; 2) improving the quality of accepted papers, reducing the reviewing workload and increasing the average quality of papers being reviewed; 3) incentivizing authors to write fewer papers of higher quality.
Survey Equivalence: A Procedure for Measuring Classifier Accuracy Against Human Labels
Jun 02, 2021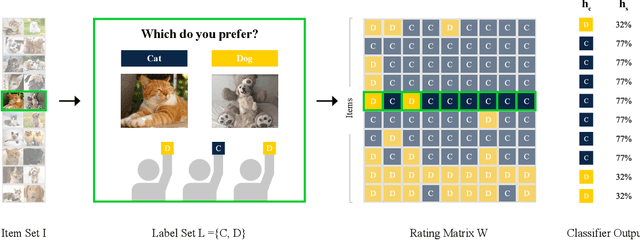
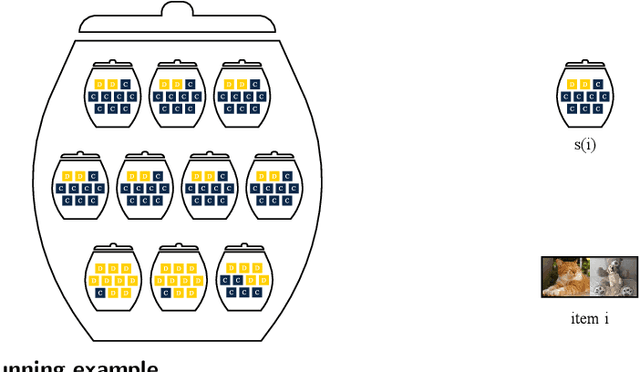


In many classification tasks, the ground truth is either noisy or subjective. Examples include: which of two alternative paper titles is better? is this comment toxic? what is the political leaning of this news article? We refer to such tasks as survey settings because the ground truth is defined through a survey of one or more human raters. In survey settings, conventional measurements of classifier accuracy such as precision, recall, and cross-entropy confound the quality of the classifier with the level of agreement among human raters. Thus, they have no meaningful interpretation on their own. We describe a procedure that, given a dataset with predictions from a classifier and K ratings per item, rescales any accuracy measure into one that has an intuitive interpretation. The key insight is to score the classifier not against the best proxy for the ground truth, such as a majority vote of the raters, but against a single human rater at a time. That score can be compared to other predictors' scores, in particular predictors created by combining labels from several other human raters. The survey equivalence of any classifier is the minimum number of raters needed to produce the same expected score as that found for the classifier.
Learning and Strongly Truthful Multi-Task Peer Prediction: A Variational Approach
Sep 30, 2020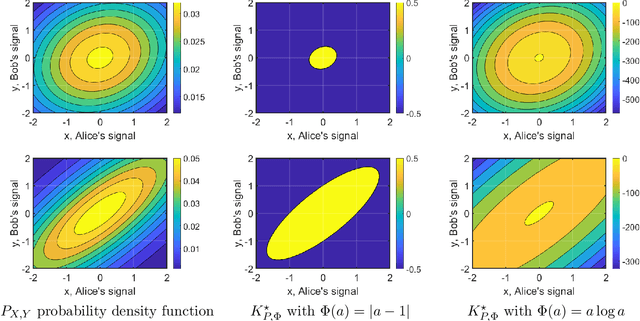
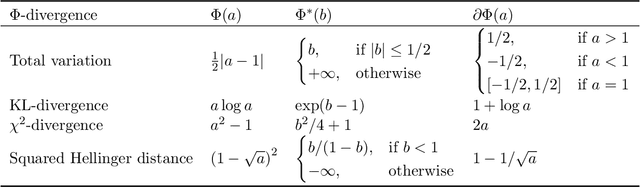
Peer prediction mechanisms incentivize agents to truthfully report their signals even in the absence of verification by comparing agents' reports with those of their peers. In the detail-free multi-task setting, agents respond to multiple independent and identically distributed tasks, and the mechanism does not know the prior distribution of agents' signals. The goal is to provide an $\epsilon$-strongly truthful mechanism where truth-telling rewards agents "strictly" more than any other strategy profile (with $\epsilon$ additive error), and to do so while requiring as few tasks as possible. We design a family of mechanisms with a scoring function that maps a pair of reports to a score. The mechanism is strongly truthful if the scoring function is "prior ideal," and $\epsilon$-strongly truthful as long as the scoring function is sufficiently close to the ideal one. This reduces the above mechanism design problem to a learning problem -- specifically learning an ideal scoring function. We leverage this reduction to obtain the following three results. 1) We show how to derive good bounds on the number of tasks required for different types of priors. Our reduction applies to myriad continuous signal space settings. This is the first peer-prediction mechanism on continuous signals designed for the multi-task setting. 2) We show how to turn a soft-predictor of an agent's signals (given the other agents' signals) into a mechanism. This allows the practical use of machine learning algorithms that give good results even when many agents provide noisy information. 3) For finite signal spaces, we obtain $\epsilon$-strongly truthful mechanisms on any stochastically relevant prior, which is the maximal possible prior. In contrast, prior work only achieves a weaker notion of truthfulness (informed truthfulness) or requires stronger assumptions on the prior.
Water from Two Rocks: Maximizing the Mutual Information
May 22, 2018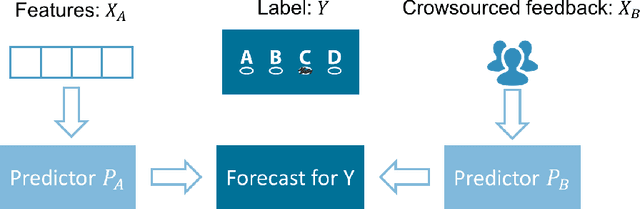
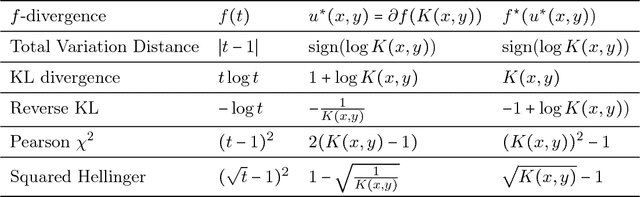

We build a natural connection between the learning problem, co-training, and forecast elicitation without verification (related to peer-prediction) and address them simultaneously using the same information theoretic approach. In co-training/multiview learning, the goal is to aggregate two views of data into a prediction for a latent label. We show how to optimally combine two views of data by reducing the problem to an optimization problem. Our work gives a unified and rigorous approach to the general setting. In forecast elicitation without verification we seek to design a mechanism that elicits high quality forecasts from agents in the setting where the mechanism does not have access to the ground truth. By assuming the agents' information is independent conditioning on the outcome, we propose mechanisms where truth-telling is a strict equilibrium for both the single-task and multi-task settings. Our multi-task mechanism additionally has the property that the truth-telling equilibrium pays better than any other strategy profile and strictly better than any other "non-permutation" strategy profile when the prior satisfies some mild conditions.