 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey Equivalence: A Procedure for Measuring Classifier Accuracy Against Human Labels
Paper and Code
Jun 02, 2021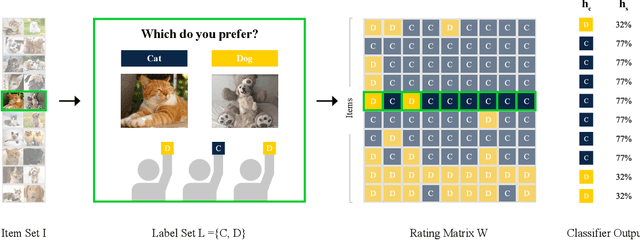
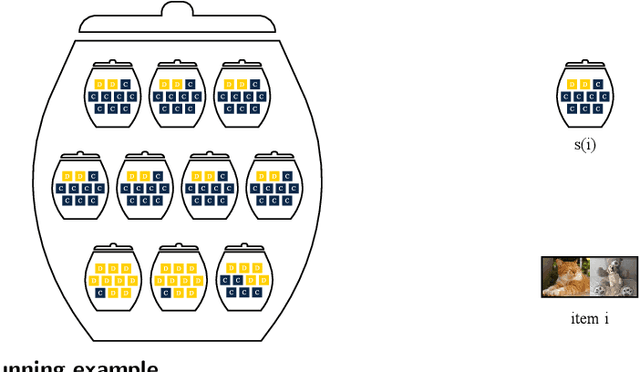


In many classification tasks, the ground truth is either noisy or subjective. Examples include: which of two alternative paper titles is better? is this comment toxic? what is the political leaning of this news article? We refer to such tasks as survey settings because the ground truth is defined through a survey of one or more human raters. In survey settings, conventional measurements of classifier accuracy such as precision, recall, and cross-entropy confound the quality of the classifier with the level of agreement among human raters. Thus, they have no meaningful interpretation on their own. We describe a procedure that, given a dataset with predictions from a classifier and K ratings per item, rescales any accuracy measure into one that has an intuitive interpretation. The key insight is to score the classifier not against the best proxy for the ground truth, such as a majority vote of the raters, but against a single human rater at a time. That score can be compared to other predictors' scores, in particular predictors created by combining labels from several other human raters. The survey equivalence of any classifier is the minimum number of raters needed to produce the same expected score as that found for the classifier.