 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Strongly Truthful Multi-Task Peer Prediction: A Variational Approach
Paper and Code
Sep 30, 2020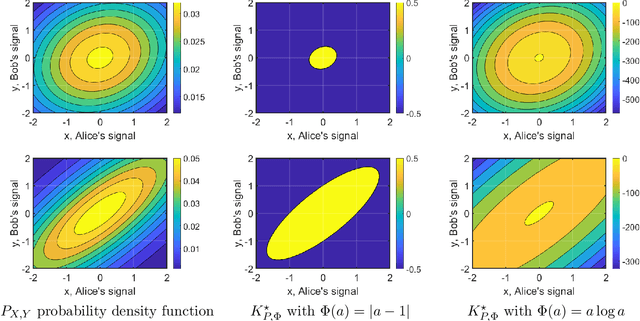
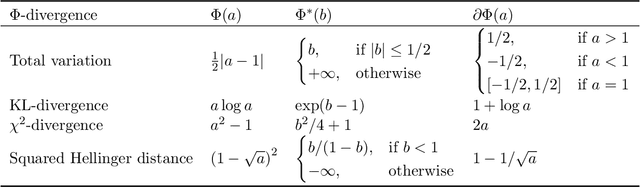
Peer prediction mechanisms incentivize agents to truthfully report their signals even in the absence of verification by comparing agents' reports with those of their peers. In the detail-free multi-task setting, agents respond to multiple independent and identically distributed tasks, and the mechanism does not know the prior distribution of agents' signals. The goal is to provide an $\epsilon$-strongly truthful mechanism where truth-telling rewards agents "strictly" more than any other strategy profile (with $\epsilon$ additive error), and to do so while requiring as few tasks as possible. We design a family of mechanisms with a scoring function that maps a pair of reports to a score. The mechanism is strongly truthful if the scoring function is "prior ideal," and $\epsilon$-strongly truthful as long as the scoring function is sufficiently close to the ideal one. This reduces the above mechanism design problem to a learning problem -- specifically learning an ideal scoring function. We leverage this reduction to obtain the following three results. 1) We show how to derive good bounds on the number of tasks required for different types of priors. Our reduction applies to myriad continuous signal space settings. This is the first peer-prediction mechanism on continuous signals designed for the multi-task setting. 2) We show how to turn a soft-predictor of an agent's signals (given the other agents' signals) into a mechanism. This allows the practical use of machine learning algorithms that give good results even when many agents provide noisy information. 3) For finite signal spaces, we obtain $\epsilon$-strongly truthful mechanisms on any stochastically relevant prior, which is the maximal possible prior. In contrast, prior work only achieves a weaker notion of truthfulness (informed truthfulness) or requires stronger assumptions on the prior.