 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transformers Learn to Plan via Multi-Token Prediction
Apr 13, 2026While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
The Newton-Muon Optimizer
Apr 01, 2026The Muon optimizer has received considerable attention for its strong performance in training large language models, yet the design principle behind its matrix-gradient orthogonalization remains largely elusive. In this paper, we introduce a surrogate model that not only sheds new light on the design of Muon, but more importantly leads to a new optimizer. In the same spirit as the derivation of Newton's method, the surrogate approximates the loss as a quadratic function of the perturbation to a weight matrix $W$ using only three matrices: the gradient $G$, an output-space curvature matrix $H$, and the data matrix $Z$ that stacks the layer inputs. By minimizing this surrogate in one step and adopting a certain isotropic assumption on the weights, we obtain the closed-form update rule (up to momentum and weight decay) $W \leftarrow W - η\cdot \mathrm{msgn}(G(ZZ^\top)^{-1})$, where $η$ is the learning rate and $\mathrm{msgn}(X)=UV^\top$ if $X=USV^\top$ is a compact singular value decomposition. This new optimization method, which we refer to as Newton-Muon, shows that standard Muon can be interpreted as an implicit Newton-type method that neglects the right preconditioning induced by the input second moment. Empirically, on a reproduction of the earliest publicly released Modded-NanoGPT speedrun configuration using Muon for GPT-2 pretraining, Newton-Muon reaches the target validation loss in 6\% fewer iteration steps and reduces wall-clock training time by about 4\%.
Pretrained Multilingual Transformers Reveal Quantitative Distance Between Human Languages
Mar 18, 2026Understanding the distance between human languages is central to linguistics, anthropology, and tracing human evolutionary history. Yet, while linguistics has long provided rich qualitative accounts of cross-linguistic variation, a unified and scalable quantitative approach to measuring language distance remains lacking. In this paper, we introduce a method that leverages pretrained multilingual language models as systematic instruments for linguistic measurement. Specifically, we show that the spontaneously emerged attention mechanisms of these models provide a robust, tokenization-agnostic measure of cross-linguistic distance, termed Attention Transport Distance (ATD). By treating attention matrices as probability distributions and measuring their geometric divergence via optimal transport, we quantify the representational distance between languages during translation. Applying ATD to a large and diverse set of languages, we demonstrate that the resulting distances recover established linguistic groupings with high fidelity and reveal patterns aligned with geographic and contact-induced relationships. Furthermore, incorporating ATD as a regularizer improves transfer performance in low-resource machine translation. Our results establish a principled foundation for testing linguistic hypotheses using artificial neural networks. This framework transforms multilingual models into powerful tools for quantitative linguistic discovery, facilitating more equitable multilingual AI.
Multimodal OCR: Parse Anything from Documents
Mar 13, 2026We present Multimodal OCR (MOCR), a document parsing paradigm that jointly parses text and graphics into unified textual representations. Unlike conventional OCR systems that focus on text recognition and leave graphical regions as cropped pixels, our method, termed dots.mocr, treats visual elements such as charts, diagrams, tables, and icons as first-class parsing targets, enabling systems to parse documents while preserving semantic relationships across elements. It offers several advantages: (1) it reconstructs both text and graphics as structured outputs, enabling more faithful document reconstruction; (2) it supports end-to-end training over heterogeneous document elements, allowing models to exploit semantic relations between textual and visual components; and (3) it converts previously discarded graphics into reusable code-level supervision, unlocking multimodal supervision embedded in existing documents. To make this paradigm practical at scale, we build a comprehensive data engine from PDFs, rendered webpages, and native SVG assets, and train a compact 3B-parameter model through staged pretraining and supervised fine-tuning. We evaluate dots.mocr from two perspectives: document parsing and structured graphics parsing. On document parsing benchmarks, it ranks second only to Gemini 3 Pro on our OCR Arena Elo leaderboard, surpasses existing open-source document parsing systems, and sets a new state of the art of 83.9 on olmOCR Bench. On structured graphics parsing, dots.mocr achieves higher reconstruction quality than Gemini 3 Pro across image-to-SVG benchmarks, demonstrating strong performance on charts, UI layouts, scientific figures, and chemical diagrams. These results show a scalable path toward building large-scale image-to-code corpora for multimodal pretraining. Code and models are publicly available at https://github.com/rednote-hilab/dots.mocr.
Online LLM watermark detection via e-processes
Feb 15, 2026Watermarking for large language models (LLMs) has emerged as an effective tool for distinguishing AI-generated text from human-written content. Statistically, watermark schemes induce dependence between generated tokens and a pseudo-random sequence, reducing watermark detection to a hypothesis testing problem on independence. We develop a unified framework for LLM watermark detection based on e-processes, providing anytime-valid guarantees for online testing. We propose various methods to construct empirically adaptive e-processes that can enhance the detection power. In addition, theoretical results are established to characterize the power properties of the proposed procedures. Some experiments demonstrate that the proposed framework achieves competitive performance compared to existing watermark detection methods.
Improve the Trade-off Between Watermark Strength and Speculative Sampling Efficiency for Language Models
Feb 01, 2026Watermarking is a principled approach for tracing the provenance of large language model (LLM) outputs, but its deployment in practice is hindered by inference inefficiency. Speculative sampling accelerates inference, with efficiency improving as the acceptance rate between draft and target models increases. Yet recent work reveals a fundamental trade-off: higher watermark strength reduces acceptance, preventing their simultaneous achievement. We revisit this trade-off and show it is not absolute. We introduce a quantitative measure of watermark strength that governs statistical detectability and is maximized when tokens are deterministic functions of pseudorandom numbers. Using this measure, we fully characterize the trade-off as a constrained optimization problem and derive explicit Pareto curves for two existing watermarking schemes. Finally, we introduce a principled mechanism that injects pseudorandomness into draft-token acceptance, ensuring maximal watermark strength while maintaining speculative sampling efficiency. Experiments further show that this approach improves detectability without sacrificing efficiency. Our findings uncover a principle that unites speculative sampling and watermarking, paving the way for their efficient and practical deployment.
Recommending Best Paper Awards for ML/AI Conferences via the Isotonic Mechanism
Jan 21, 2026Machine learning and artificial intelligence conferences such as NeurIPS and ICML now regularly receive tens of thousands of submissions, posing significant challenges to maintaining the quality and consistency of the peer review process. This challenge is particularly acute for best paper awards, which are an important part of the peer review process, yet whose selection has increasingly become a subject of debate in recent years. In this paper, we introduce an author-assisted mechanism to facilitate the selection of best paper awards. Our method employs the Isotonic Mechanism for eliciting authors' assessments of their own submissions in the form of a ranking, which is subsequently utilized to adjust the raw review scores for optimal estimation of the submissions' ground-truth quality. We demonstrate that authors are incentivized to report truthfully when their utility is a convex additive function of the adjusted scores, and we validate this convexity assumption for best paper awards using publicly accessible review data of ICLR from 2019 to 2023 and NeurIPS from 2021 to 2023. Crucially, in the special case where an author has a single quota -- that is, may nominate only one paper -- we prove that truthfulness holds even when the utility function is merely nondecreasing and additive. This finding represents a substantial relaxation of the assumptions required in prior work. For practical implementation, we extend our mechanism to accommodate the common scenario of overlapping authorship. Finally, simulation results demonstrate that our mechanism significantly improves the quality of papers selected for awards.
How to Find Fantastic Papers: Self-Rankings as a Powerful Predictor of Scientific Impact Beyond Peer Review
Oct 02, 2025Peer review in academic research aims not only to ensure factual correctness but also to identify work of high scientific potential that can shape future research directions. This task is especially critical in fast-moving fields such as artificial intelligence (AI), yet it has become increasingly difficult given the rapid growth of submissions. In this paper, we investigate an underexplored measure for identifying high-impact research: authors' own rankings of their multiple submissions to the same AI conference. Grounded in game-theoretic reasoning, we hypothesize that self-rankings are informative because authors possess unique understanding of their work's conceptual depth and long-term promise. To test this hypothesis, we conducted a large-scale experiment at a leading AI conference, where 1,342 researchers self-ranked their 2,592 submissions by perceived quality. Tracking outcomes over more than a year, we found that papers ranked highest by their authors received twice as many citations as their lowest-ranked counterparts; self-rankings were especially effective at identifying highly cited papers (those with over 150 citations). Moreover, we showed that self-rankings outperformed peer review scores in predicting future citation counts. Our results remained robust after accounting for confounders such as preprint posting time and self-citations. Together, these findings demonstrate that authors' self-rankings provide a reliable and valuable complement to peer review for identifying and elevating high-impact research in AI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
CoMemo: LVLMs Need Image Context with Image Memory
Jun 06, 2025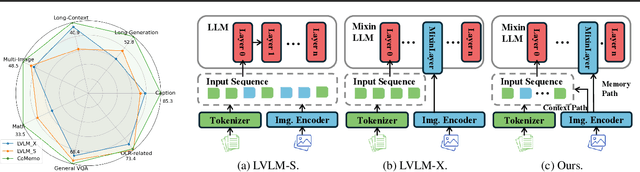
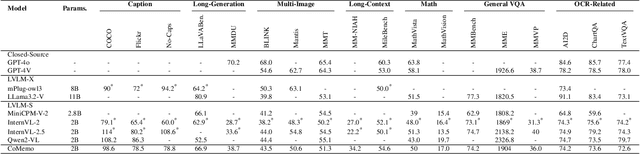
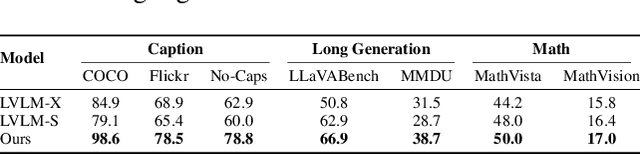
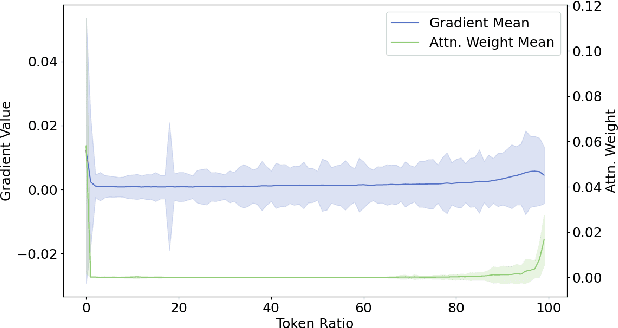
Recent advancements in Large Vision-Language Models built upon Large Language Models have established aligning visual features with LLM representations as the dominant paradigm. However, inherited LLM architectural designs introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of middle visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images. To address these limitations, we propose CoMemo - a dual-path architecture that combines a Context image path with an image Memory path for visual processing, effectively alleviating visual information neglect. Additionally, we introduce RoPE-DHR, a novel positional encoding mechanism that employs thumbnail-based positional aggregation to maintain 2D spatial awareness while mitigating remote decay in extended sequences. Evaluations across seven benchmarks,including long-context comprehension, multi-image reasoning, and visual question answering, demonstrate CoMemo's superior performance compared to conventional LVLM architectures. Project page is available at https://lalbj.github.io/projects/CoMemo/.